
Operator Metering은 쿠버네티스 클러스터 전반에서 리소스가 사용되는 방식에 책임을 부여하는 차지백 및 보고 툴입니다. 클러스터 관리자는 포드, 네임스페이스, 클러스터 전체의 과거 사용량 데이터를 기반으로 리포트를 예약할 수 있습니다.
미터링 오퍼레이터를 설치할 때는 즉시 사용 가능한 다양한 리포트 쿼리가 제공됩니다. 예를 들어 관리자가 클러스터 노드(또는 포드)의 CPU(또는 메모리) 사용량을 측정하려는 경우 미터링 오퍼레이터를 설치하고 Report 사용자 정의 리소스를 작성하여 리포트(월별, 시간별 등)를 생성하기만 하면 됩니다.
활용 사례
다음은 고객들로부터 항상 듣는 몇 가지 요구 사항입니다.
- 프로덕션 이외의 환경을 위한 OpenShift 클러스터의 작업자 노드는 경우에 따라 실행되지 않을 수도 있습니다(예: 관리자가 사용 가능한 용량에 따라 또는 주말 동안 일부 작업자 노드를 끄려는 경우). 따라서 인프라 팀에서 실제 노드 사용률에 따라 사용자에게 차지백을 제공할 수 있도록 노드의 CPU(또는 메모리) 사용량을 매월 측정하려고 합니다.
- 고객은 특정 팀을 위한 전용 OpenShift 클러스터를 배포하는 배포 모델을 보유하고 있습니다. 미터링 오퍼레이터를 설치하여 노드 사용량을 확인할 수 있지만 차지백 리포트에 작업자 노드를 사용하는 팀(또는 사업부)을 포함하려고 합니다. 이러한 활용 사례는 공유된 전용 클러스터에 '레이블이 지정된' 노드가 있고 각 레이블이 노드에서 실행되는 사업부/팀의 워크로드를 식별하는 사례로 확장될 수도 있습니다.
- 운영 팀은 공유 클러스터에서 포드의 실행 시간(CPU 또는 메모리 사용량일 수도 있음)에 따라 팀에 차지백을 제공하려고 합니다. 이번에도, 포드가 속한 팀(또는 사업부)을 포함하도록 리포트를 간소화하려고 합니다.
이러한 요구 사항으로 인해 클러스터에서 몇 가지 사용자 정의 리소스를 생성해야 하며, 이 문서에서는 이러한 작업을 손쉽게 수행하는 방법을 제시합니다. 미터링 오퍼레이터 설치는 이 문서에서 다루지 않습니다. 여기에서 설치 설명서를 참조할 수 있습니다. 즉시 사용 가능한 리포트를 사용하는 방법에 대한 자세한 내용은 여기에서 설명서를 참조하세요.
미터링의 작동 방식
위 섹션에서 언급한 대로 활용 사례에 대한 새 사용자 정의 리소스를 생성하기 전에 OpenShift Metering의 작동 방식을 간단히 설명하겠습니다. OpenShift Metering을 설치하면 미터링 오퍼레이터가 생성하는 사용자 정의 리소스는 총 6개가 됩니다. 6개 항목 중 다음 항목에 대해 약간의 설명이 필요합니다.
- ReportDataSources(rds): rds는 어떤 데이터가 사용 가능한지, 그리고 ReportQuery 또는 Report 사용자 정의 리소스에서 어떤 데이터를 사용할 수 있는지를 정의하는 메커니즘입니다. 또한 여러 소스에서 데이터를 가져올 수 있습니다. OpenShift에서는 Prometheus 및 ReportQuery(rq) 사용자 정의 리소스에서 데이터를 가져옵니다.
- ReportQuery (rq): rq에는 rds와 함께 저장된 데이터에 대한 분석을 수행하는 SQL 쿼리가 포함되어 있습니다. Report 오브젝트에서 rq 오브젝트를 참조하는 경우 rq 오브젝트는 리포트가 실행될 때 리포팅할 대상도 관리합니다. rds 오브젝트에서 참조하는 경우 rq 오브젝트는 렌더링된 쿼리를 기반으로 Presto 테이블(미터링 설치의 일부로 생성됨) 내에 보기를 생성하도록 미터링에 명령합니다.
- Report: 이 사용자 정의 리소스를 사용하면 구성된 ReportQuery 리소스를 사용하여 리포트가 생성됩니다. 이는 미터링 오퍼레이터의 최종 사용자가 상호 작용하는 기본 리소스입니다. 리포트는 일정에 따라 실행되도록 구성할 수 있습니다.
즉시 사용할 수 있는 rds 및 rq는 다양합니다. 여기서는 노드 수준 미터링에 중점을 두고 있으므로 자체 사용자 정의 쿼리를 작성하기 위해 이해해야 하는 항목을 보여 드리겠습니다. 'openshift-metering' 프로젝트에서 다음 커맨드를 실행합니다.
$ oc project openshift-metering $ oc get reportdatasources | grep node node-allocatable-cpu-cores node-allocatable-memory-bytes node-capacity-cpu-cores node-capacity-memory-bytes node-cpu-allocatable-raw node-cpu-capacity-raw node-memory-allocatable-raw node-memory-capacity-raw |
CPU 사용량을 측정해야 하므로 'node-capacity-cpu-cores' 및 'node-cpu-capacity-raw'라는 두 rds를 중점적으로 살펴보고자 합니다. Node-capacity-cpu-cores를 중심으로 다음 커맨드를 실행하여 Prometheus에서 데이터를 수집하는 방법을 살펴보겠습니다.
$ oc get reportdatasource/node-capacity-cpu-cores -o yaml spec: prometheusMetricsImporter: query: | kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id) |
Prometheus에서 데이터를 가져와 Presto 테이블에 저장하는 데 사용되는 Prometheus 쿼리를 확인할 수 있습니다. OpenShift의 메트릭 콘솔에서 동일한 쿼리를 실행하고 결과를 살펴보겠습니다. 작업자 노드 2개(각 노드의 코어 16개)와 마스터 노드 3개(각각 코어 8개)가 있는 OpenShift 클러스터가 있습니다. 마지막 열 'value'는 노드에 할당된 코어를 기록합니다.
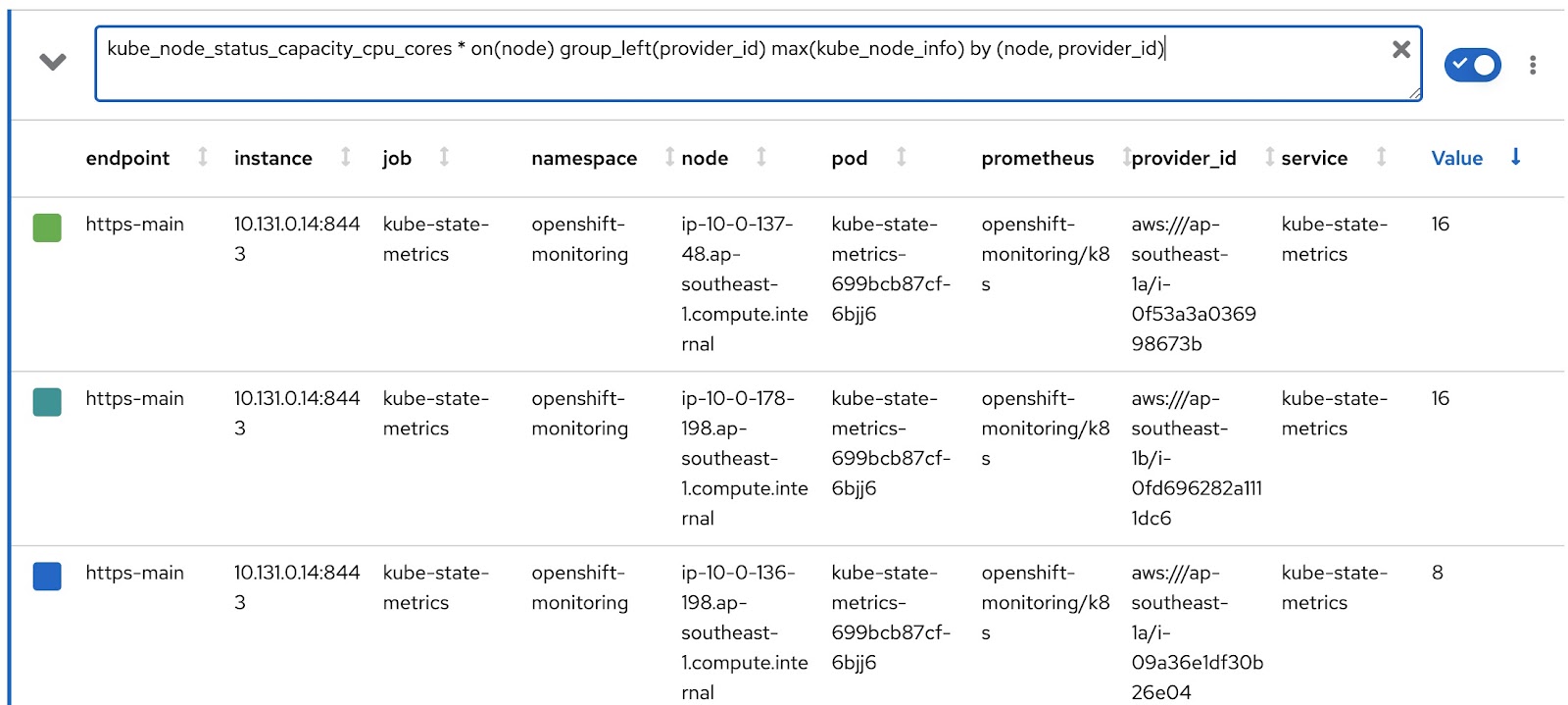
따라서 데이터가 수집되어 Presto 테이블에 저장됩니다. 이제 몇 가지 reportquery(rq) 사용자 정의 리소스를 집중적으로 살펴보겠습니다.
$ oc project openshift-metering $ oc get reportqueries | grep node-cpu node-cpu-allocatable node-cpu-allocatable-raw node-cpu-capacity node-cpu-capacity-raw node-cpu-utilization |
여기서는 'node-cpu-capacity' 및 'node-cpu-capacity-raw' rqs를 중심으로 살펴보겠습니다. 이러한 reportquery를 설명하고, 이들이 데이터를 계산(예: 노드가 가동되는 시간, 할당된 CPU 수 등) 및 집계하고 있음을 알 수 있습니다.
실제로 아래 다이어그램은 각각 2개의 rds와 rq가 연결되는 방식에 대한 체인을 보여줍니다.
node-cpu-capacity(rq) 사용 node-cpu-capacity-raw(rds) 사용 node-cpu-capacity-raw(rq) 사용 node-capacity-cpu-cores(rds)
리포트 사용자 정의
사용자 정의 rds 및 rq를 작성하는 방법을 살펴보겠습니다. 먼저 노드가 마스터/작업자 노드로 작동하는지의 여부를 포함하도록 Prometheus 쿼리를 변경한 다음, 노드가 속한 팀을 식별하는 적절한 노드 레이블을 포함해야 합니다. 'kube_node_role' Prometheus 메트릭에는 데이터 wrt nodel 역할(마스터 또는 작업자)이 있습니다. 'role' 열을 확인해 보세요.

'kube_node_labels' prometheus 메트릭은 노드에 적용된 모든 레이블을 캡처합니다. 모든 레이블은 'label_
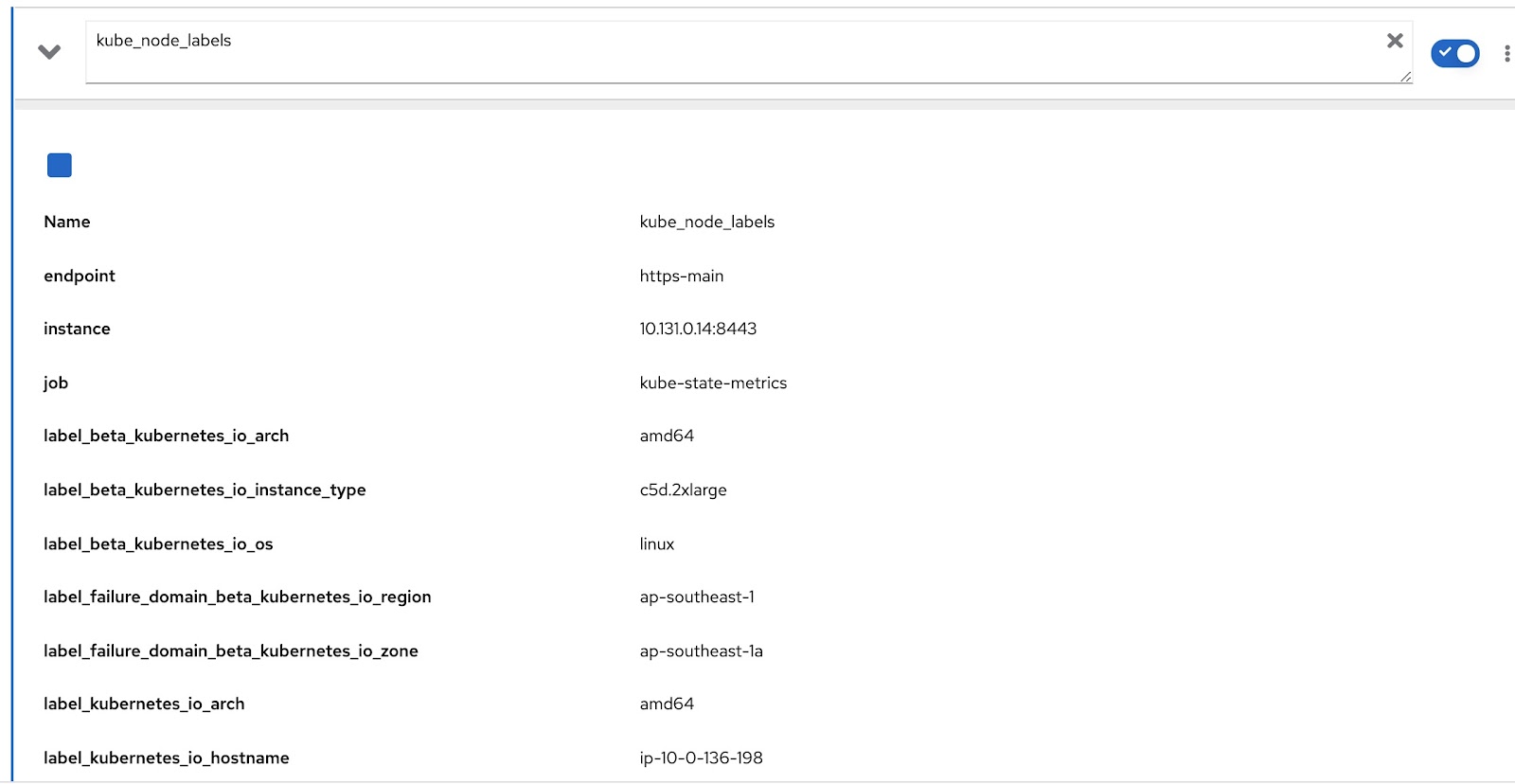
이제 몇 가지 추가 Prometheus 쿼리와 함께 원본 쿼리를 수정하여 관련 데이터를 가져오기만 하면 됩니다. 이 쿼리는 다음과 같습니다.
((kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id)) * on(node) group_left (role) kube_node_role{role='worker'}) * on(node) group_right(provider_id, role) kube_node_labels
OpenShift의 메트릭 콘솔에서 이 쿼리를 실행하고 레이블(node_lob)과 역할 정보가 모두 있는지 확인합니다. 아래에는 출력으로 label_node_lob과 역할이 있습니다(쿼리에서 많은 열을 출력하므로 역할 정보는 볼 수 없지만 캡처됨).
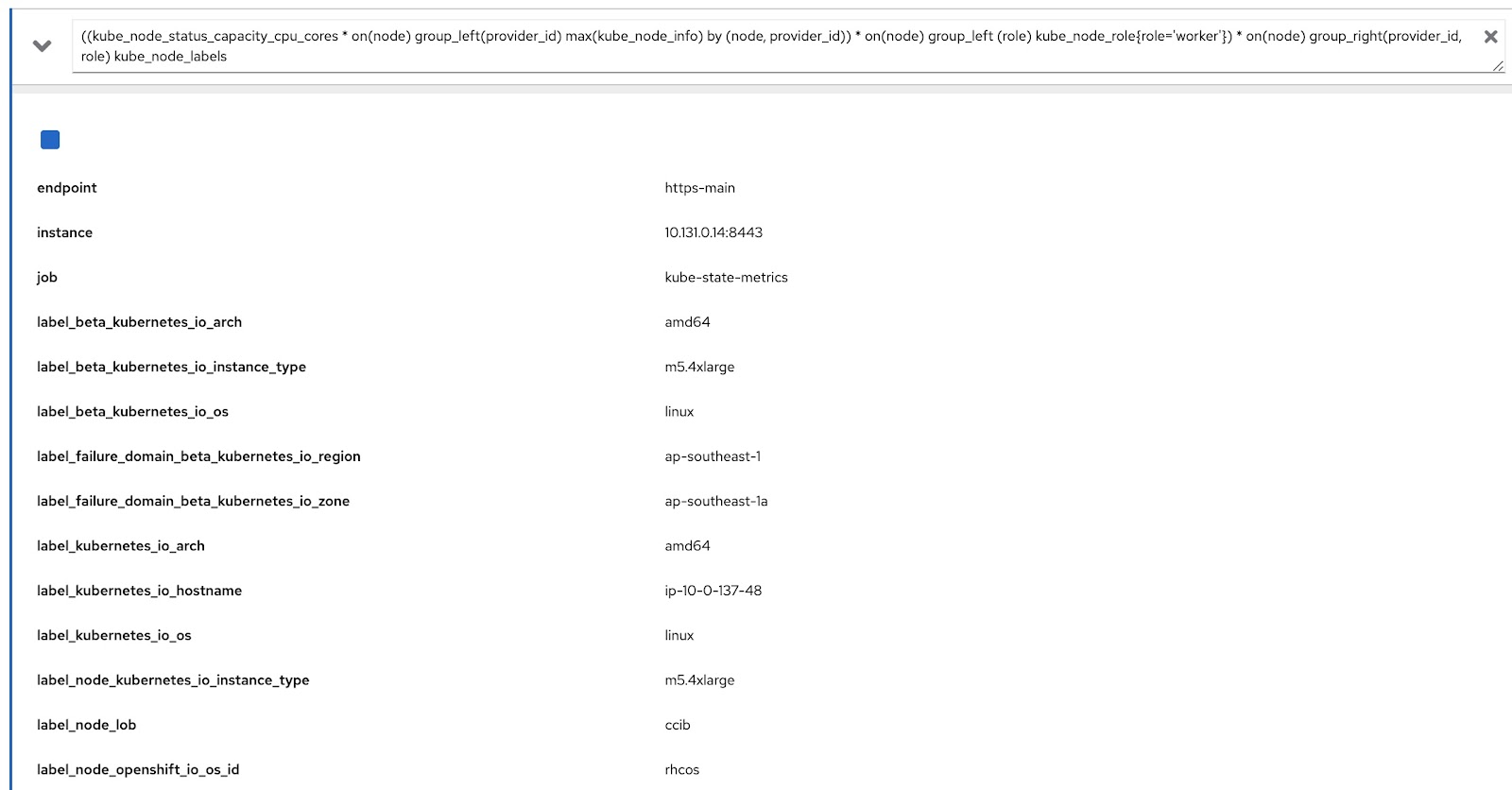
따라서 사용자 정의 리소스 4개를 작성합니다. 편의를 위해 이러한 사용자 정의 리소스를 여기에 업로드했습니다.
- rds-custom-node-capacity-cpu-cores.yaml: Prometheus 쿼리를 정의합니다.
- rq-custom-node-cpu-capacity-raw.yaml: 위 rds를 나타내며 원시 데이터를 계산합니다.
- rds-custom-node-cpu-capacity-raw.yaml: 위 rq를 나타내며 Presto에서 보기를 생성합니다.
- rq-custom-node-cpu-capacity-with-cpus-labels.yaml: 위 3번에서 언급한 rds를 나타내며 입력 시작 및 종료 데이터를 기반으로 데이터를 계산합니다. 또한 role 및 node_label 열을 검색하는 파일입니다.
이러한 yaml 파일을 작성하고 나면 openshift-metering 프로젝트로 이동하여 다음 커맨드를 실행합니다.
$ oc project openshift-metering $ oc create -f rds-custom-node-capacity-cpu-cores.yaml $ oc create -f rq-custom-node-cpu-capacity-raw.yaml $ oc create -f rds-custom-node-cpu-capacity-raw.yaml $ oc create -f rq-custom-node-cpu-capacity-with-cpus-labels.yaml |
마지막으로 위에서 생성한 마지막 rq 오브젝트를 참조하는 Report 사용자 정의 오브젝트를 작성하기만 하면 됩니다. 아래와 같이 작성할 수 있습니다. 아래 리포트는 즉시 실행되며 9월 15일부터 30일까지의 데이터를 표시합니다.
$ cat report_immediate.yaml apiVersion: metering.openshift.io/v1 kind: Report metadata: name: custom-role-node-cpu-capacity-lables-immediate namespace: openshift-metering spec: query: custom-role-node-cpu-capacity-labels reportingStart: "2020-09-15T00:00:00Z" reportingEnd: "2020-09-30T00:00:00Z" runImmediately: true
$ oc create -f report-immediate.yaml |
이 리포트를 실행하면 다음 URL을 통해 파일(csv 또는 json 형식)을 다운로드할 수 있습니다(DOMAIN NAME을 적절하게 변경).
아래의 CSV 스냅샷에는 role과 node_lob 열이 모두 있는 캡처된 데이터가 표시되어 있습니다. 노드의 런타임(초)에 도달하려면 'node_capacity_cpu_core_seconds' 열을 'node_capacity_cpu_cores'로 나누어야 합니다.

요약
미터링 오퍼레이터는 매우 유용하며 어떤 실행 위치에서든 OpenShift 클러스터에서 실행할 수 있습니다. 고객이 자체 사용자 정의 리소스를 작성하여 필요에 따라 리포트를 생성할 수 있도록 확장 가능한 프레임워크를 제공합니다. 위에 사용된 모든 코드는 여기에서 사용할 수 있습니다.
저자 소개
유사한 검색 결과
과거의 운영 방식에서 벗어나 IT의 미래 구축
강력한 보안, 즉시 사용 가능, 추가 비용 없이 제공: 컨테이너 보안의 진화
Crack the Cloud_Open | Command Line Heroes
Can Kubernetes Help People Find Love? | Compiler
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래