
O Red Hat OpenShift Virtualization 4.19 melhora muito o desempenho e a velocidade de cargas de trabalho com alto nível de E/S, como bancos de dados. O uso de várias linhas de E/S é uma nova funcionalidade do Red Hat OpenShift Virtualization para distribuir operações de E/S de um disco de máquina virtual (VM) entre várias linhas de nó de trabalho no host. Essas linhas, por sua vez, são mapeadas para filas de disco dentro da VM. Assim, a VM usa a vCPU e a CPU do host com mais eficiência no processamento de vários fluxos de E/S, resultando em um desempenho melhor.
Este artigo serve como um complemento ao artigo introdução à funcionalidade de Jenifer Abrams. Abaixo, apresento os resultados do desempenho para você ajustar sua VM e melhorar a taxa de transferência de E/S.
Nos testes, usei o fio com VMs Linux para simular uma carga de trabalho de E/S sintética. Há outros testes sendo realizados com aplicações e também no Microsoft Windows.
Para mais informações sobre como essa funcionalidade é implementada na KVM, leia o artigo sobre o IOThread Virtqueue Mapping. Consulte também o artigo complementar que demonstra as melhorias no desempenho em cargas de trabalho de banco de dados em VMs executadas em um ambiente Red Hat Enterprise Linux (RHEL).
Descrição do teste
Testei a taxa de transferência de E/S em duas configurações:
- Um cluster com armazenamento local usando o gerenciador de volume lógico (LVM) provisionado pelo operador de armazenamento local (LSO).
- Um cluster separado usando o OpenShift Data Foundation (ODF).
As configurações são muito diferentes e não podem ser comparadas.
Os testes foram feitos em pods (para estabelecer uma linha de base) e em VMs. As VMs receberam 16 núcleos e 8 GB de RAM. Usei arquivos de teste de 512 GB em uma VM e de 256 GB em duas VMs. Executei operações diretas de E/S em todos os testes. Nas VMs, usei declarações de volume permanente (PVC) no modo de bloco e formatadas como ext4. Já nos pods, usei PVCs no modo de sistema de arquivos, também formatadas como ext4. Todos os testes foram executados com o mecanismo de E/S da libaio.
Testei a matriz a seguir:
Parâmetro | Configurações |
Tipo de volume de armazenamento | Armazenamento local (LSO), ODF |
Número de pods/VMs | 1, 2 |
Número de linhas de E/S (somente VMs) | Nenhuma (linha de base), 1, 2, 3, 4, 6, 8, 12, 16 |
Operações de E/S | Leituras e gravações sequenciais e aleatórias |
Tamanhos dos blocos de E/S (bytes) | 2K, 4K, 32K, 1M |
Tarefas simultâneas | 1, 4, 16 |
Profundidade de E/S (iodepth) | 1, 4, 16 |
Usei o ClusterBuster para orquestrar os testes. Como imagem base de container, as VMs usaram o CentOS Stream 9. Os pods também usaram o CentOS Stream.
Armazenamento local
O cluster de armazenamento local tinha cinco nós (3 mestres e 2 de trabalho). Esse cluster era composto por nós Dell R740xd com duas CPUs Intel Xeon Gold 6130, cada uma com 16 núcleos e 2 linhas (32 CPUs), totalizando 32 núcleos e 64 CPUs. Além disso, cada nó tinha 192 GB de RAM. O subsistema de E/S consistia em quatro unidades NVMe Kioxia CM6 MU de 1,6 TB, da marca Dell, configuradas como vários dispositivos (MD) distribuídos em RAID0 com as definições padrão. As PVCs foram retiradas desse MD usando o operador lvmcluster. Infelizmente, eu só tinha à minha disposição essa configuração modesta. É muito provável que um sistema mais veloz tenha um desempenho ainda melhor com o uso de várias linhas de E/S.
OpenShift Data Foundation
O cluster do OpenShift Data Foundation (ODF) tinha 6 nós (3 mestres e 3 de trabalho). Eles eram nós Dell PowerEdge R7625 com 2 CPUs AMD EPYC 9534, cada uma com 64 núcleos e 2 linhas (128 CPUs), totalizando 128 núcleos e 256 CPUs. Cada nó tinha 512 GB de RAM. O subsistema de E/S consistia em duas unidades NVMe de 5,8 TB por nó, com replicação tripla em uma rede padrão de pods de 25 GbE. Não foi possível usar uma rede mais rápida para realizar esse teste, mas um hardware de rede mais novo teria provavelmente resultado em uma melhoria superior.
Resumo dos resultados
O teste avaliou o processamento de várias linhas de E/S com back-ends específicos que talvez não se encaixem no seu caso de uso. As diferenças nas características de armazenamento podem ter grande impacto na escolha do número de linhas de E/S.
O que os testes revelaram:
- Taxa de transferência máxima de E/S: no caso da configuração com armazenamento local, a taxa de transferência máxima alcançou cerca de 7,3 GB/s na leitura e 6,7 GB/s na gravação. Esse resultado foi observado tanto para os pods quanto para as VMs, independentemente de iodepth ou do número de tarefas no armazenamento local. Esse é um desempenho muito abaixo do esperado com esse hardware. Os dispositivos (quatro máquinas PCIe gen4) são classificados em 6,9 GB/s para leitura e 4,2 MB/s para gravação. Não investiguei o motivo disso, mas o hardware usado era antigo. O pico de desempenho é claramente melhor do que o alcançado por uma única unidade, indicando que a distribuição surtiu um efeito positivo. No caso do cluster do ODF, o melhor que conseguimos foi cerca de 5 GB/s de leitura e 2 GB/s de gravação.
- O desempenho de E/S de bloco grande (1 MB) apresentou pouca ou nenhuma melhoria, pois já estava limitado pelo sistema.
- O número ideal de linhas de E/S depende das características da carga de trabalho e do armazenamento. Como esperado, não houve muitos benefícios para as cargas de trabalho sem uma quantidade significativa de operações simultâneas de E/S.
- Armazenamento local: nas VMs com um grande número de operações simultâneas de E/S, o ideal é começar com 4 a 8 linhas. Em específico, as cargas de trabalho com operações pequenas de E/S, mas em alto volume simultâneo, podem se beneficiar de uma quantidade maior de linhas.
- ODF: ter mais de uma linha de E/S raramente produziu algum benefício significativo. Em muitos casos, nenhuma foi necessária. É provável que o motivo seja a lentidão da rede de pods. Uma rede mais rápida deve produzir resultados diferentes.
- Nesse teste, usar várias linhas de E/S trouxe mais melhorias no desempenho em cenários com várias tarefas simultâneas do que com operações muito assíncronas de E/S.
- Houve pouca diferença de comportamento entre uma e duas VMs simultâneas até que a taxa de transferência máxima agregada de E/S (mencionada acima) fosse atingida.
- O uso de várias linhas de E/S não superou por completo a diferença em relação aos pods com uma baixa contagem de tarefas ou iodepth. Em um cenário de alta iodepth de E/S com operações pequenas, as VMs tiveram um desempenho muito superior ao dos pods na gravação.
Em números
Você pode conferir a seguir a taxa de transferência geral obtida usando várias linhas de E/S no meu sistema com armazenamento local. Como é possível constatar, os benefícios para as cargas de trabalho com operações menores de E/S e alto paralelismo para um sistema veloz são muitos. Abaixo, apresento outras descobertas sobre os benefícios que obtive usando números diferentes de linhas de E/S. A melhoria observada com um tamanho de bloco de 1 MB foi pequena porque o desempenho já estava muito próximo do limite do sistema. Com um hardware mais veloz, é possível que usar um número maior de linhas de E/S produza melhorias mesmo em blocos grandes.
Melhoria máxima em relação à linha de base de VM com mais linhas de E/S | ||||||||||
(Armazenamento local) | tarefas | iodepth | ||||||||
1 | 4 | 16 | ||||||||
tamanho | op | 1 | 4 | 16 | 1 | 4 | 16 | 1 | 4 | 16 |
2.048 | randread | 18% | 31% | 30% | 30% | 103% | 192% | 151% | 432% | 494% |
randwrite | 81% | 59% | 24% | 153% | 199% | 187% | 458% | 433% | 353% | |
read | 67% | 58% | 25% | 64% | 71% | 103% | 252% | 241% | 287% | |
write | 103% | 64% | 0% | 143% | 99% | 84% | 410% | 250% | 203% | |
Total em 2.048 | 67% | 53% | 20% | 97% | 118% | 141% | 318% | 339% | 334% | |
4.096 | randread | 18% | 34% | 28% | 33% | 101% | 208% | 156% | 432% | 492% |
randwrite | 95% | 69% | 20% | 149% | 200% | 187% | 471% | 543% | 481% | |
read | 26% | 53% | 27% | 24% | 46% | 66% | 142% | 155% | 165% | |
write | 103% | 69% | 0% | 144% | 86% | 48% | 438% | 256% | 161% | |
Total em 4.096 | 60% | 56% | 19% | 87% | 108% | 127% | 302% | 346% | 325% | |
32.768 | randread | 16% | 23% | 26% | 23% | 71% | 124% | 99% | 160% | 129% |
randwrite | 75% | 71% | 28% | 108% | 132% | 116% | 203% | 123% | 115% | |
read | 21% | 57% | 25% | 21% | 42% | 32% | 77% | 54% | 32% | |
write | 79% | 64% | 26% | 104% | 59% | 24% | 195% | 45% | 27% | |
Total em 32.768 | 48% | 53% | 26% | 64% | 76% | 74% | 143% | 96% | 76% | |
1.048.576 | randread | 5% | 2% | 0% | 9% | 0% | 0% | 17% | 0% | 0% |
randwrite | 10% | 0% | 1% | 6% | 0% | 2% | 9% | 0% | 2% | |
read | 12% | 18% | 0% | 9% | 0% | 0% | 16% | 0% | 0% | |
write | 19% | 0% | 0% | 7% | 0% | 0% | 9% | 0% | 0% | |
Total em 1.048.576 | 11% | 5% | 0% | 8% | 0% | 1% | 13% | 0% | 0% | |
A seguir, mostro quantas linhas de E/S são necessárias para alcançar 90% do melhor resultado possível com até 16 linhas. Por exemplo, se o melhor resultado alcançado no meu teste com uma combinação específica de operações, tamanho de bloco, tarefas e iodepth foi de 1 GB/s, a métrica seria a menor quantidade necessária de linhas para atingir 900 MB/s. Assim, é possível definir um número mais moderado de linhas e ainda conseguir um bom desempenho.
Contagem mínima de linhas de E/S para alcançar 90% do pico de desempenho | ||||||||||
(Armazenamento local) | tarefas | iodepth | ||||||||
1 | 4 | 16 | ||||||||
tamanho | op | 1 | 4 | 16 | 1 | 4 | 16 | 1 | 4 | 16 |
2.048 | randread | 1 | 1 | 1 | 1 | 4 | 8 | 3 | 12 | 12 |
randwrite | 1 | 1 | 1 | 3 | 16 | 12 | 8 | 12 | 12 | |
read | 1 | 1 | 1 | 1 | 4 | 4 | 4 | 6 | 8 | |
write | 1 | 1 | 0 | 2 | 12 | 6 | 8 | 6 | 6 | |
Total em 2.048 | 1 | 1 | 1 | 2 | 9 | 8 | 6 | 9 | 10 | |
4.096 | randread | 1 | 1 | 1 | 1 | 4 | 8 | 3 | 12 | 12 |
randwrite | 1 | 1 | 1 | 3 | 16 | 12 | 8 | 12 | 12 | |
read | 1 | 1 | 1 | 1 | 2 | 3 | 3 | 6 | 8 | |
write | 1 | 1 | 0 | 3 | 12 | 4 | 8 | 6 | 4 | |
Total em 4.096 | 1 | 1 | 1 | 2 | 9 | 7 | 6 | 9 | 9 | |
32.768 | randread | 1 | 1 | 1 | 1 | 3 | 6 | 2 | 4 | 3 |
randwrite | 1 | 1 | 1 | 2 | 12 | 6 | 4 | 3 | 3 | |
read | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | |
write | 1 | 1 | 1 | 2 | 6 | 2 | 4 | 2 | 1 | |
Total em 32.768 | 1 | 1 | 1 | 2 | 6 | 4 | 3 | 3 | 2 | |
1.048.576 | randread | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
randwrite | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
read | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
write | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
Total em 1.048.576 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
Resultados detalhados
Para cada caso de teste avaliado, calculei as seguintes métricas:
- Medição da taxa de transferência de E/S
- Pico de desempenho das VMs (não informado diretamente)
- Número mínimo de linhas de E/S para alcançar 90% do pico de desempenho das VMs
- Proporção entre o pico de desempenho das VMs e dos pods
- Melhoria do pico de desempenho das VM em relação ao desempenho da linha de base
Resolvi NÃO divulgar o número de linhas para alcançar o pico de desempenho porque, em muitos casos, as diferenças foram muito pequenas e até menores do que a variação usual na medição do desempenho de E/S.
Estou apresentando dois resumos separados para os resultados das configurações com armazenamento local e ODF porque as características são muito diferentes.
Todos os gráficos de desempenho abaixo mostram resultados obtidos com os pods (pod), uma VM de linha de base sem linhas de E/S (0) e o número especificado de linhas de E/S no eixo X.
Armazenamento local
Analisando o desempenho bruto, é possível constatar que, em pelo menos alguns casos, o uso de várias linhas de E/S traz benefícios substanciais. Por exemplo, no caso da configuração com armazenamento local executando 16 tarefas e operações assíncronas de E/S com iodepth 1, o uso de mais linhas pode proporcionar uma melhoria de quase uma ordem de magnitude:
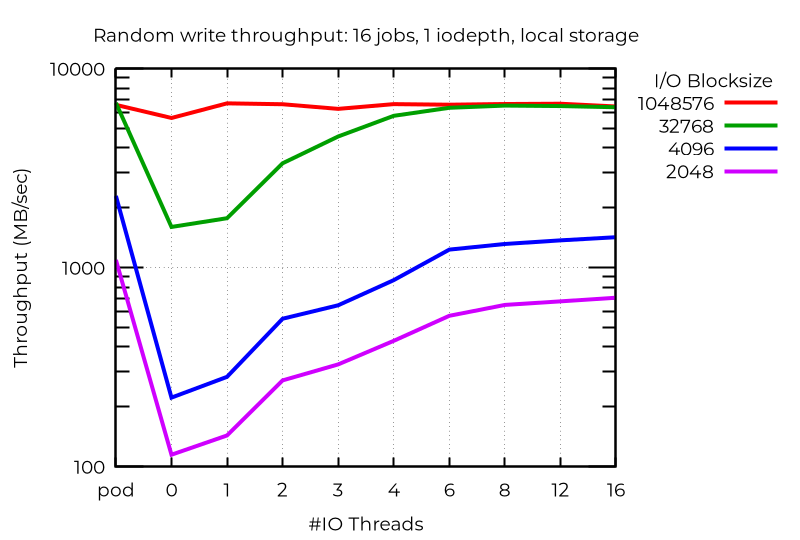
Mesmo com um único fluxo de E/S, o uso de uma linha extra pode proporcionar um ganho. Como esperado, mais de uma não ajuda:

Em alguns casos anômalos, as linhas extras na verdade prejudicam o desempenho. Nesse caso, o melhor desempenho alcançado para as operações muito assíncronas de E/S com blocos pequenos foi nas VMs que não usavam linhas dedicadas (o desempenho foi melhor até mesmo do que nos pods). Não descobri o motivo disso.
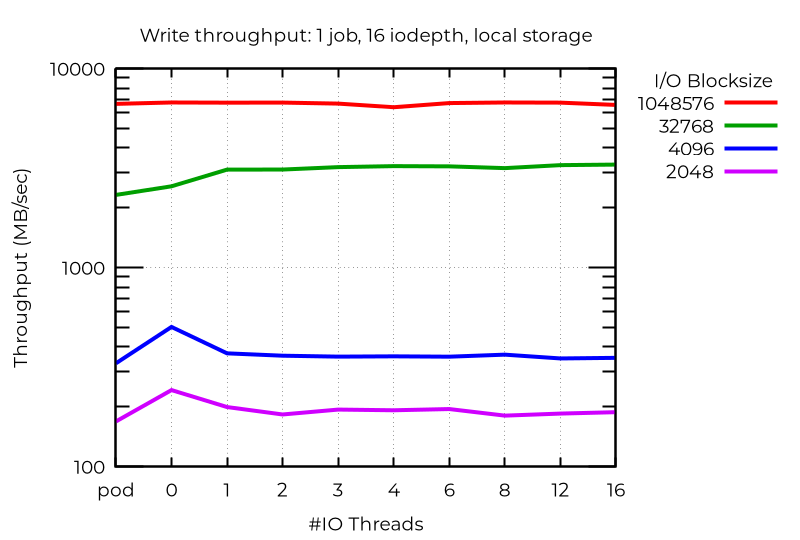
Tudo isso demonstra que, para obter o melhor desempenho com o uso de várias linhas de E/S, é necessário fazer experimentos com a carga de trabalho específica.
Resultados do cluster do ODF
Ao contrário da configuração com armazenamento local, onde a gravação aleatória em pequenos blocos teve melhorias significativas ao usar várias linhas de E/S, observei benefícios mínimos no ODF, mesmo com uma alta contagem de tarefas. É provável que o resultado seja melhor com uma rede mais rápida ou de menor latência. As operações de leitura, principalmente de leitura aleatória, apresentaram uma melhoria modesta. Mas, no caso das gravações e das contagens baixas de tarefas, os benefícios foram poucos ou inexistentes.
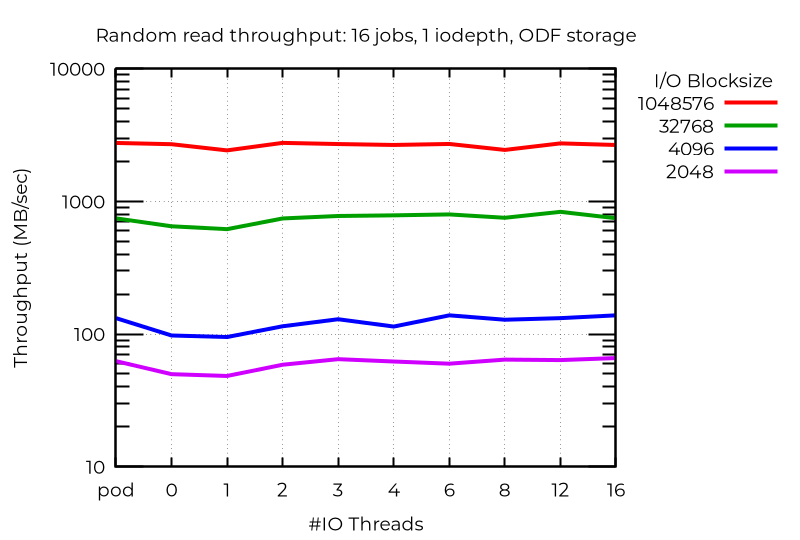
Conclusões
O uso de várias linhas de E/S para OpenShift Virtualization é uma nova funcionalidade incrível do OpenShift 4.19. Ela tem o potencial de proporcionar melhorias significativas no desempenho de E/S para cargas de trabalho com operações simultâneas, principalmente em sistemas velozes, como a configuração com armazenamento NVMe local que usei nos meus testes. É provável que os subsistemas de E/S mais velozes sejam os que mais se beneficiam do uso de várias linhas, pois mais CPUs são necessárias para extrair o máximo do bare metal. Como sempre acontece com operações de E/S, as diferenças nos sistemas e nas cargas de trabalho em geral podem afetar bastante o desempenho. Portanto, recomendo testar suas próprias cargas de trabalho para aproveitar ao máximo essa nova funcionalidade. Espero que os resultados do meu teste ajudem você a tomar a melhor decisão com relação ao uso de linhas de E/S.
Teste de produto
Red Hat OpenShift Virtualization Engine | Teste de solução
Sobre o autor
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem