Overview
In this blog we look at how to realize a cluster landing zone for the hybrid cloud architecture that was introduced in the previous blog. We will extend the multi-tenanted operating model underpinning our solution so that it can run both stateless and stateful workloads in a "cloud agnostic" manner. To this end we will make use of various capabilities within the Red Hat Advanced Cluster Management for Kubernetes (RHACM) toolbox.
Extending the Cluster Landing Zone
In the previous blog we described a multi-tenancy operating model, implemented on the hub, whereby centralized management functions for cluster administrators (SREs) and application teams could occur independently and securely of each other. We now extend the personas to include DBAs who will use the hub to provision stateful backend workloads for the application team. The revised cluster landing zone is depicted in the following diagram.
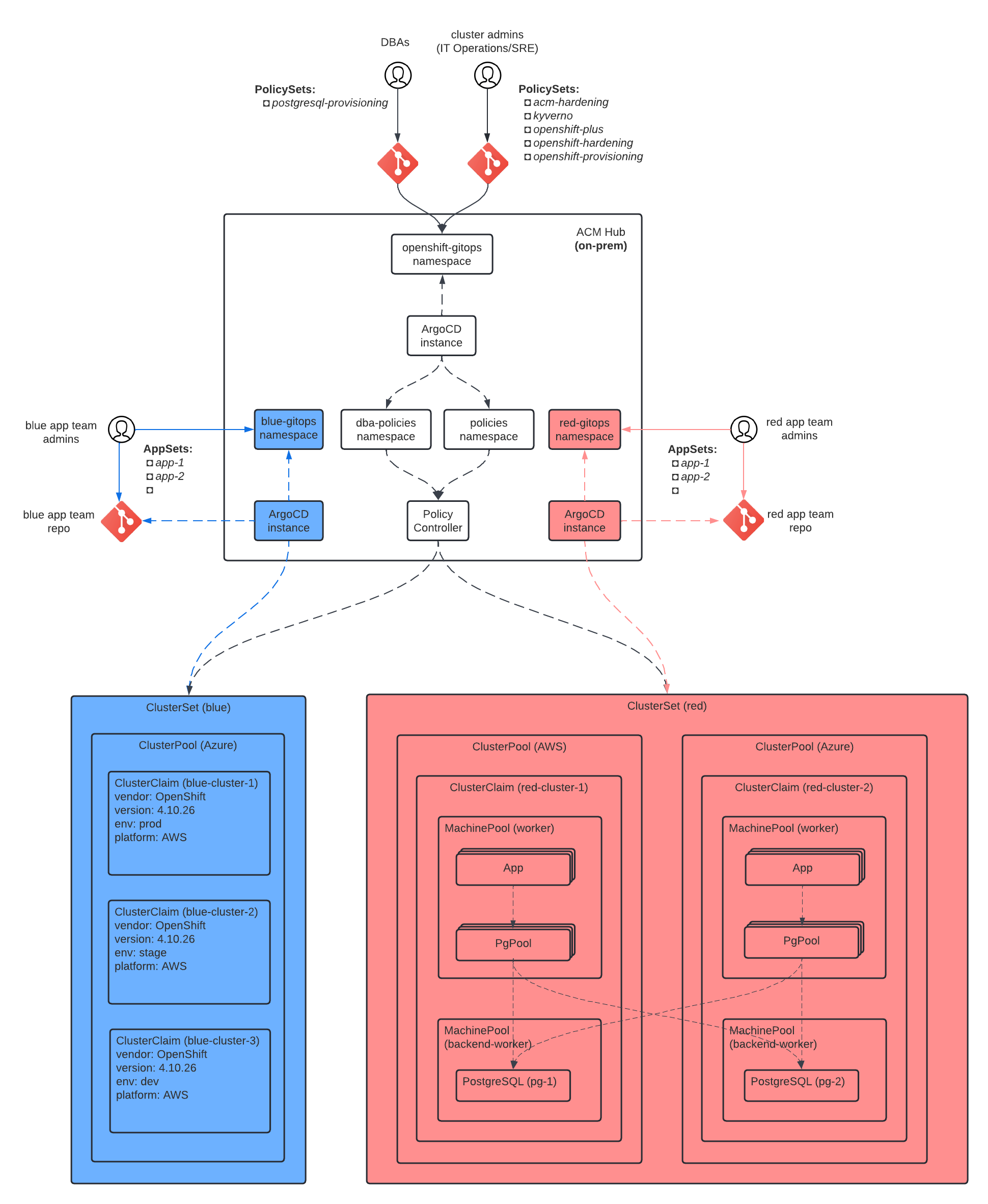 Diagram 1. Cluster landing zone operating model for a hybrid cloud architecture
Diagram 1. Cluster landing zone operating model for a hybrid cloud architecture
In order to share the default GitOps server located on the hub, SREs will need to configure AppProjects within ArgoCD to restrict DBAs to specific namespaces (dba-policies) and include restrictions on the type of resources (Policies and Placements) that can be deployed.
The diagram above shows how MachineSets on spoke clusters are aggregated into MachinePools which can be scaled either manually or automatically from the RHACM console. We will be using the default MachinePool for running stateless frontend workloads and a separate MachinePool for running stateful backend workloads. A PostgreSQL server will be deployed to each backend MachinePool in an active/standby configuration with the primary on AWS and the standby on GCP; streaming replication will be enabled for data protection. PgPool will also be deployed on the nodes in the default MachinePool for client-side load-balancing and connection pooling.
Deploying the Cluster Landing Zone
The following set of instructions which pertain to cluster provisioning and configuration are intended to be executed by SREs. The YAML manifests shown are intended to be applied using Policies which will be explained in more detail later.
We start by defining an empty ManagedClusterSet that serves as a logical container for clusters created from a public or private cloud provider infrastructure.
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: ManagedClusterSet
metadata:
name: red-cluster-set
spec: {}
We bind the dba-policies namespace to the newly created ManagedClusterSet (red-cluster-set) so that any policies written to here can only be executed against clusters bound to it. For more details on how ManagedClusterSets and namespace bindings work together please refer to this. Because we also need to generate configuration information that will be shared across all spoke clusters, this needs to be centrally stored on the hub as a ConfigMap in the dba-policies namespace from where it will be referenced later by another policy. This is why the dba-policies namespace is also bound to the default ManagedClusterSet which references the hub itself.
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: ManagedClusterSetBinding
metadata:
name: red-cluster-set
namespace: dba-policies
spec:
clusterSet: red-cluster-set
---
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: ManagedClusterSetBinding
metadata:
name: default
namespace: dba-policies
spec:
clusterSet: default
ClusterPools abstract cloud provider infrastructure details and map any clusters created to the ManagedClusterSet (red-cluster-set). The example shown here is for AWS and the contents of the install-config.yaml have been omitted for brevity. A corresponding ClusterPool resource for GCP must also be defined with a non-overlapping CIDR space so that both clusters can join a Submariner network.
apiVersion: hive.openshift.io/v1
kind: ClusterPool
metadata:
name: 'red-cluster-pool-aws-1'
namespace: 'red-cluster-pool'
labels:
cloud: 'AWS'
region: 'ap-southeast-1'
vendor: OpenShift
cluster.open-cluster-management.io/clusterset: 'red-cluster-set'
spec:
size: 0
runningCount: 0
skipMachinePools: false
baseDomain: # your domain name
installConfigSecretTemplateRef:
name: red-cluster-pool-aws-install-config-1
imageSetRef:
name: img4.11.2-x86-64-appsub
pullSecretRef:
name: red-cluster-pool-aws-pull-secret
platform:
aws:
credentialsSecretRef:
name: red-cluster-pool-aws-creds
region: ap-southeast-1
To create a new spoke cluster from our ClusterPool we need to submit a ClusterClaim resource. The following ClusterClaims are submitted with custom labels which will help when placing workloads later.
apiVersion: hive.openshift.io/v1
kind: ClusterClaim
metadata:
name: red-cluster-1
namespace: red-cluster-pool
labels:
env: dev
postgresql: pg-1
spec:
clusterPoolName: red-cluster-pool-aws-1
---
apiVersion: hive.openshift.io/v1
kind: ClusterClaim
metadata:
name: red-cluster-2
namespace: red-cluster-pool
labels:
env: dev
postgresql: pg-2
spec:
clusterPoolName: red-cluster-pool-gcp-1
The resulting set of spoke clusters is as follows.
$ oc get managedclusters -A
NAME HUB ACCEPTED MANAGED CLUSTER URLS JOINED AVAILABLE AGE
local-cluster true https://api.hub-cluster-1.aws.jwilms.net:6443 True True 5h38m
red-cluster-pool-aws-1-4thqz true https://api.red-cluster-pool-aws-1-4thqz.aws.jwilms.net:6443 True True 4h37m
red-cluster-pool-gcp-1-8chvh true https://api.red-cluster-pool-gcp-1-8chvh.gcp.jwilms.net:6443 True True 4h45m
Note that cluster names are dynamically generated as part of this process. This should not be an issue provided applications are being published using a domain name that does not include the cluster name. In the event that the cluster is recreated it will spin up with a different name even if the same ClusterClaim is submitted. To address this consider using the appsDomain feature or a secondary ingress controller with a custom domain name to separate cluster administration endpoints from application delivery.
By default each cluster spins up with three worker nodes which will be used to host stateless frontend workloads such as PgPool. To also host a stateful backend workload (PostgreSQL) we need to add a MachinePoolwith a specific machine configuration to match expected workload characteristics and isolation requirements.
apiVersion: hive.openshift.io/v1
kind: MachinePool
metadata:
name: '{{ (lookup "hive.openshift.io/v1" "ClusterClaim" "red-cluster-pool" "red-cluster-1").spec.namespace }}-backend-worker'
namespace: '{{ (lookup "hive.openshift.io/v1" "ClusterClaim" "red-cluster-pool" "red-cluster-1").spec.namespace }}'
spec:
clusterDeploymentRef:
name: '{{ (lookup "hive.openshift.io/v1" "ClusterClaim" "red-cluster-pool" "red-cluster-1").spec.namespace }}'
name: backend-worker
labels:
node-role.kubernetes.io/backend: ""
taints:
- effect: NoSchedule
key: postgresql
platform:
aws:
rootVolume:
iops: 100
size: 120
type: gp3
type: m6i.xlarge
replicas: 1
This YAML manifest makes use of Go templating to map a known quantity (static ClusterClaim name) to an unknown quantity (dynamic cluster name). See the following blog for more details, and this blog which explains how the Policy Generator tool processes templates.
The resulting MachinePools for each spoke cluster is shown in the following output.
$ oc get machinepools -A
NAMESPACE NAME POOLNAME CLUSTERDEPLOYMENT REPLICAS
red-cluster-pool-aws-1-4thqz red-cluster-pool-aws-1-4thqz-backend-worker backend-worker red-cluster-pool-aws-1-4thqz 1
red-cluster-pool-aws-1-4thqz red-cluster-pool-aws-1-4thqz-worker worker red-cluster-pool-aws-1-4thqz 3
red-cluster-pool-gcp-1-8chvh red-cluster-pool-gcp-1-8chvh-backend-worker backend-worker red-cluster-pool-gcp-1-8chvh 1
red-cluster-pool-gcp-1-8chvh red-cluster-pool-gcp-1-8chvh-worker worker red-cluster-pool-gcp-1-8chvh 3
We now turn our attention to establishing a cross-cluster network so that the PostgreSQL server hosted in one cluster can communicate to the PostgreSQL server hosted in another cluster. A "flattening" of the network between spoke clusters is required so that services and pods in one cluster have direct line-of-sight access to services and pods in other clusters. Submariner establishes hybrid network connectivity at layer-3 of the OSI model and supports both TCP and UDP protocols using IPsec tunnels. Please refer to the documentation for more details on Submariner and prerequisites.
To configure Submariner we submit the following YAML manifest as per this example for AWS, again using templates to derive cluster names.
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ManagedClusterAddOn
metadata:
name: submariner
namespace: '{{ (lookup "hive.openshift.io/v1" "ClusterClaim" "red-cluster-pool" "red-cluster-1").spec.namespace }}'
spec:
installNamespace: submariner-operator
---
apiVersion: submariner.io/v1alpha1
kind: Broker
metadata:
name: submariner-broker
namespace: red-cluster-set-broker
spec:
globalnetEnabled: false
---
apiVersion: submarineraddon.open-cluster-management.io/v1alpha1
kind: SubmarinerConfig
metadata:
name: submariner
namespace: '{{ (lookup "hive.openshift.io/v1" "ClusterClaim" "red-cluster-pool" "red-cluster-1").spec.namespace }}'
spec:
gatewayConfig:
gateways: 2
aws:
instanceType: c5d.large
IPSecNATTPort: 4500
NATTEnable: true
cableDriver: libreswan
credentialsSecret:
name: '{{ (lookup "hive.openshift.io/v1" "ClusterClaim" "red-cluster-pool" "red-cluster-1").spec.namespace }}-aws-creds'
Before proceeding to setup PostgreSQL check the status of the Submariner network from the RHACM console.
 Diagram 2. Submariner setup for two spoke clusters spanning two cloud providers
Diagram 2. Submariner setup for two spoke clusters spanning two cloud providers
Deploying PostgreSQL
The following steps are intended to be executed by DBAs using Policies which are written to the dba-policies namespace by the OpenShift GitOps engine running on the hub cluster. From here they will be picked up by the Policy Controller and applied to all spoke clusters selected via Placement resources.
Depending on whether you are using Operators or Helm charts to install PostgreSQL, the steps may vary and are well-covered by the respective providers. The main considerations for deploying PostgreSQL in a hybrid cloud environment include tuning of network-related timeouts and choosing the correct high-performance storage. Other factors related to a production setup are discussed later. In our setup we will be focusing on deploying PostgreSQL in an active/standby configuration with connectivity provided by the hybrid network established by Submariner. The active primary PostgreSQL server runs on a cluster in AWS and the passive standby PostgreSQL server runs on a cluster in GCP. Both PostgreSQL servers are part of a replication cluster and fronted by PgPool for load-balancing and connection pooling.
To complete the integration of PostgreSQL with the hybrid network requires specifying the endpoint hostnames of the PostgreSQL servers which in turn will be hosted on the clusterset.local domain instead of the usual cluster.local domain. The endpoint hostnames are created by Submariner when we submit a ServiceExport which references the name of the StatefulSet headless service created for us by the PostgreSQL installation. Note that we distinguish between PostgreSQL server instances running on different cloud providers using pg-1 and pg-2 prefixes (see ClusterClaim above) and link to these here.
apiVersion: multicluster.x-k8s.io/v1alpha1
kind: ServiceExport
metadata:
name: pg-1-postgresql-ha-postgresql-headless
namespace: database
---
apiVersion: multicluster.x-k8s.io/v1alpha1
kind: ServiceExport
metadata:
name: pg-2-postgresql-ha-postgresql-headless
namespace: database
We also need to define some configuration details on the hub that will be referenced later when configuring the respective PostgreSQL servers for replication.
apiVersion: v1
kind: ConfigMap
metadata:
name: pg-config
namespace: dba-policies
data:
nodeid0: '1000'
nodeid1: '1001'
nodename0: 'pg-1-postgresql-ha-postgresql-0'
nodename1: 'pg-2-postgresql-ha-postgresql-0'
hostname0: 'pg-1-postgresql-ha-postgresql-0.{{- (lookup "hive.openshift.io/v1" "ClusterClaim" "red-cluster-pool" "red-cluster-1").spec.namespace -}}.pg-1-postgresql-ha-postgresql-headless.database.svc.clusterset.local'
hostname1: 'pg-2-postgresql-ha-postgresql-0.{{- (lookup "hive.openshift.io/v1" "ClusterClaim" "red-cluster-pool" "red-cluster-2").spec.namespace -}}.pg-2-postgresql-ha-postgresql-headless.database.svc.clusterset.local'
The following YAML manifest references the aforementioned ConfigMap and copies values into environment variables used by the PostgreSQL container image.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: pg-1-postgresql-ha-postgresql
namespace: database
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/component: postgresql
app.kubernetes.io/instance: pg-1
template:
metadata:
labels:
app.kubernetes.io/component: postgresql
app.kubernetes.io/instance: pg-1
spec:
containers:
- env:
- name: REPMGR_NODE_ID
value: '{{hub fromConfigMap "" "pg-config" (printf "nodeid0") hub}}'
- name: REPMGR_NODE_NAME
value: '{{hub fromConfigMap "" "pg-config" (printf "nodename0") hub}}'
- name: REPMGR_PARTNER_NODES
value: '{{hub fromConfigMap "" "pg-config" (printf "hostname0") hub}},{{hub fromConfigMap "" "pg-config" (printf "hostname1") hub}}'
- name: REPMGR_PRIMARY_HOST
value: '{{hub fromConfigMap "" "pg-config" (printf "hostname0") hub}}'
- name: REPMGR_NODE_NETWORK_NAME
value: '{{hub fromConfigMap "" "pg-config" (printf "hostname0") hub}}'
image: # set this to your postgresql container image
name: postgresql
initContainers:
- image: # set this to your postgresql container image
name: init-chmod-data
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: pg-1-postgresql-ha-pgpool
namespace: database
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/component: pgpool
app.kubernetes.io/instance: pg-1
spec:
template:
metadata:
labels:
app.kubernetes.io/component: pgpool
app.kubernetes.io/instance: pg-1
spec:
containers:
- env:
- name: PGPOOL_BACKEND_NODES
value: '0:{{hub fromConfigMap "" "pg-config" (printf "hostname0") hub}}:5432,1:{{hub fromConfigMap "" "pg-config" (printf "hostname1") hub}}:5432'
image: # set this to you pgpool container image
name: pgpool
Note that the StatefulSet pertaining to pg-2 should use nodeid1 and hostname1 for the value of REPMGR_NODE_ID and REPMGR_NODE_NETWORK_NAME.
Here is the contents of the Policy Generator manifest that will be used to ingest all of the prior manifests and translate them into Policies that the Policy Controller can apply to the spoke clusters. Note that all Policies are loaded in a disabled state first, as they should only be enabled by the DBA after the PostgreSQL software has been installed.
apiVersion: policy.open-cluster-management.io/v1
kind: PolicyGenerator
metadata:
name: policy-postgresql-provisioning
placementBindingDefaults:
name: binding-policy-postgresql-provisioning
policyDefaults:
namespace: dba-policies
complianceType: musthave
remediationAction: enforce
severity: low
policies:
- name: policy-generate-postgresql-config-hub
manifests:
- path: input-hub-clusters/postgresql/
disabled: true
policySets:
- policyset-postgresql-hub-clusters
- name: policy-patch-postgresql-red-clusters-aws-1
manifests:
- path: input-standalone-clusters/red/aws-1/postgresql/
policySets:
- policyset-postgresql-red-standalone-clusters-aws-1
disabled: true
- name: policy-patch-postgresql-red-clusters-gcp-1
manifests:
- path: input-standalone-clusters/red/gcp-1/postgresql/
policySets:
- policyset-postgresql-red-standalone-clusters-gcp-1
disabled: true
policySets:
- description: This policy set is focused on PostgreSQL components for the ACM hub.
name: policyset-postgresql-hub-clusters
placement:
placementPath: input/placement-hub-clusters.yaml
- description: This policy set is focused on PostgreSQL components for managed OpenShift clusters on AWS.
name: policyset-postgresql-red-standalone-clusters-aws-1
placement:
placementPath: input/placement-red-standalone-clusters-aws-1.yaml
- description: This policy set is focused on PostgreSQL components for managed OpenShift clusters on GCP.
name: policyset-postgresql-red-standalone-clusters-gcp-1
placement:
placementPath: input/placement-red-standalone-clusters-gcp-1.yaml
The Policy Generator leverages Placement resources to map Policies to spoke clusters. An example Placement resource is as follows.
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: Placement
metadata:
name: placement-red-standalone-clusters-aws-1
namespace: dba-policies
spec:
clusterSets:
- red-cluster-set
predicates:
- requiredClusterSelector:
labelSelector:
matchExpressions:
- {key: vendor, operator: In, values: ["OpenShift"]}
- {key: name, operator: NotIn, values: ["local-cluster"]}
- {key: env, operator: In, values: ["dev"]}
- {key: postgresql, operator: In, values: ["pg-1"]}
Here we are using a mix of custom and auto-generated labels to identify spoke clusters in scope. At no point do we ever refer to the dynamically generated name of the cluster given that this name will change whenever the cluster is rebuilt. Also note that we include a filter for clusterSets as it is possible that our DBA may be managing clusters for multiple teams using similar labels.
Simulating Cloud Provider Failure
Once our policies have been enabled this will trigger the Policy Controller to patch the PostgreSQL StatefulSet and PgPool Deployment and spin up replicas on each spoke cluster. In our setup we have limited the number of PostgreSQL and PgPool replicas to one for simplicity. In a production setup the number of PgPool replicas should match the scaling and uptime SLA requirements of the service.
At this stage the resources deployed to the AWS cluster are as follows.
$ oc get all,pvc,endpointslices
NAME READY STATUS RESTARTS AGE
pod/pg-1-postgresql-ha-pgpool-bf5b69cbb-h6pfl 1/1 Running 0 24m
pod/pg-1-postgresql-ha-postgresql-0 1/1 Running 0 24m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/pg-1-postgresql-ha-pgpool ClusterIP 172.30.81.120 <none> 5432/TCP 24m
service/pg-1-postgresql-ha-postgresql ClusterIP 172.30.48.22 <none> 5432/TCP 24m
service/pg-1-postgresql-ha-postgresql-headless ClusterIP None <none> 5432/TCP 24m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/pg-1-postgresql-ha-pgpool 1/1 1 1 24m
NAME DESIRED CURRENT READY AGE
replicaset.apps/pg-1-postgresql-ha-pgpool-bf5b69cbb 1 1 1 24m
NAME READY AGE
statefulset.apps/pg-1-postgresql-ha-postgresql 1/1 24m
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/data-pg-1-postgresql-ha-postgresql-0 Bound pvc-66b68308-5e44-49a1-94e8-655fa0c8475d 8Gi RWO gp3-csi 24m
NAME ADDRESSTYPE PORTS ENDPOINTS AGE
endpointslice.discovery.k8s.io/pg-1-postgresql-ha-pgpool-75wjr IPv4 5432 10.128.2.28 24m
endpointslice.discovery.k8s.io/pg-1-postgresql-ha-postgresql-d2rhs IPv4 5432 10.130.2.6 24m
endpointslice.discovery.k8s.io/pg-1-postgresql-ha-postgresql-headless-4fbxh IPv4 5432 10.130.2.6 24m
endpointslice.discovery.k8s.io/pg-1-postgresql-ha-postgresql-headless-red-cluster-pool-aws-1-4thqz IPv4 5432 10.130.2.6 24m
endpointslice.discovery.k8s.io/pg-2-postgresql-ha-postgresql-headless-red-cluster-pool-gcp-1-8chvh IPv4 5432 10.134.2.6 24m
The last two endpointslices in the output identify the IP addresses of the local and remote PostgreSQL server pods and are the result of the ServiceExport resources created earlier.
The next step is to test for a catastrophic loss of a cloud provider which can happen due to a cascading failure, misconfiguration error, or a vulnerability exploit that affects critical control plane functions. This can be simulated using the hibernate function in RHACM which will stop a cluster resulting in the loss of network connectivity between the primary and standby PostgreSQL servers. After a number of failed re-connection attempts, the decision logic within the PostgreSQL replication manager will promote the surviving standby server into a primary role. Before we do this let's take a look at how the replication manager and PgPool view the current status.
$ repmgr -f /opt/bitnami/repmgr/conf/repmgr.conf service status
ID | Name | Role | Status | Upstream | repmgrd | PID | Paused? | Upstream last seen
-----+---------------------------------+---------+-----------+---------------------------------+---------+-----+---------+--------------------
1000 | pg-1-postgresql-ha-postgresql-0 | primary | * running | | running | 1 | no | n/a
1001 | pg-2-postgresql-ha-postgresql-0 | standby | running | pg-1-postgresql-ha-postgresql-0 | running | 1 | no | 0 second(s) ago
postgres=# show pool_nodes;
-[ RECORD 1 ]----------+----------------------------------------------------------------------------------------------------------------------------------
node_id | 0
hostname | pg-1-postgresql-ha-postgresql-0.red-cluster-pool-aws-1-4thqz.pg-1-postgresql-ha-postgresql-headless.database.svc.clusterset.local
port | 5432
status | up
pg_status | up
lb_weight | 0.500000
role | primary
pg_role | primary
select_cnt | 111
load_balance_node | true
replication_delay | 0
replication_state |
replication_sync_state |
last_status_change | 2022-10-26 00:55:34
-[ RECORD 2 ]----------+----------------------------------------------------------------------------------------------------------------------------------
node_id | 1
hostname | pg-2-postgresql-ha-postgresql-0.red-cluster-pool-gcp-1-8chvh.pg-2-postgresql-ha-postgresql-headless.database.svc.clusterset.local
port | 5432
status | up
pg_status | up
lb_weight | 0.500000
role | standby
pg_role | standby
select_cnt | 113
load_balance_node | false
replication_delay | 0
replication_state |
replication_sync_state |
last_status_change | 2022-10-26 00:55:44
Everything looks good and we can login to the RHAC console and hibernate the cluster running the primary PostgreSQL server.
 Diagram 3. Hibernating a cluster to simulate the catastrophic loss of a cloud provider
Diagram 3. Hibernating a cluster to simulate the catastrophic loss of a cloud provider
After a short while the standby PostgreSQL server is automatically promoted to a primary role which can be seen in the following output.
$ repmgr -f /opt/bitnami/repmgr/conf/repmgr.conf service status
ID | Name | Role | Status | Upstream | repmgrd | PID | Paused? | Upstream last seen
-----+---------------------------------+---------+-----------+----------+---------+-----+---------+--------------------
1000 | pg-1-postgresql-ha-postgresql-0 | primary | - failed | ? | n/a | n/a | n/a | n/a
1001 | pg-2-postgresql-ha-postgresql-0 | primary | * running | | running | 1 | no | n/a
WARNING: following issues were detected
- unable to connect to node "pg-1-postgresql-ha-postgresql-0" (ID: 1000)
Assuming our cloud provider does not stay offline indefinitely we need to prepare for the eventual restoration of the server. In the configuration above we defined an environment variable to identify the primary server.
- name: REPMGR_PRIMARY_HOST
value: '{{hub fromConfigMap "" "pg-config" (printf "hostname0") hub}}'
If we bring back online the cluster hosting the downed server without changing this configuration, it will continue to think that it still is the primary server even though the standby has been promoted. This will result in a split-brain situation which is undesirable. To avoid this we must first update our YAML manifest to reflect the new order of things and let the Policy Controller propagate these changes. The changes required to the StatefulSet configuration which must be applied to both PostgreSQL servers is as follows.
- name: REPMGR_PRIMARY_HOST
value: '{{hub fromConfigMap "" "pg-config" (printf "hostname1") hub}}'
After making these changes the next step is to resume the cluster from the RHACM console. Note that there is no need to update the PgPool deployment configuration.
The output of the replication manager after both the primary (old standby) and standby (old primary) servers have been updated shows that they are now both running with their correct roles.
$ repmgr -f /opt/bitnami/repmgr/conf/repmgr.conf service status
ID | Name | Role | Status | Upstream | repmgrd | PID | Paused? | Upstream last seen
-----+---------------------------------+---------+-----------+---------------------------------+---------+-----+---------+--------------------
1000 | pg-1-postgresql-ha-postgresql-0 | standby | running | pg-2-postgresql-ha-postgresql-0 | running | 1 | no | 1 second(s) ago
1001 | pg-2-postgresql-ha-postgresql-0 | primary | * running | | running | 1 | no | n/a
The output for PgPool is as follows. Note that there is a discrepancy between the roles from PgPool and PostgreSQL perspectives. Whilst this has no material bearing on reads or writes it is misleading and can be fixed by simply restarting the PgPool deployment which will then show the correct status values.
postgres=# show pool_nodes;
-[ RECORD 1 ]----------+----------------------------------------------------------------------------------------------------------------------------------
node_id | 0
hostname | pg-1-postgresql-ha-postgresql-0.red-cluster-pool-aws-1-4thqz.pg-1-postgresql-ha-postgresql-headless.database.svc.clusterset.local
port | 5432
status | up
pg_status | up
lb_weight | 0.500000
role | primary
pg_role | standby
select_cnt | 14
load_balance_node | false
replication_delay | 0
replication_state |
replication_sync_state |
last_status_change | 2022-10-26 02:22:34
-[ RECORD 2 ]----------+----------------------------------------------------------------------------------------------------------------------------------
node_id | 1
hostname | pg-2-postgresql-ha-postgresql-0.red-cluster-pool-gcp-1-8chvh.pg-2-postgresql-ha-postgresql-headless.database.svc.clusterset.local
port | 5432
status | up
pg_status | up
lb_weight | 0.500000
role | standby
pg_role | primary
select_cnt | 11
load_balance_node | true
replication_delay | 83914888
replication_state |
replication_sync_state |
last_status_change | 2022-10-26 02:22:34
Some parting thoughts:
-
For a production environment we could add a third standby (on a separate cloud provider) as part of a scale-out solution, or a witness node (on a HyperShift cluster) to establish quorum so as to avoid other split-brain scenarios and for strong fencing. Doing so would help to achieve a lower RTO than the current solution.
-
We can make use of the fact that cloud providers located in the same region typically have a network latency of under 10 milliseconds. Thus our local PostgreSQL clusters could be configured for synchronous replication which will enable a RPO of zero. This could be augmented with asynchronous replication to a remote set of PostgreSQL clusters located in other regions for disaster recovery purposes.
-
Deploy a global load-balancer that spans multiple ingress endpoints and is itself not dependent on the infrastructure of any of the underlying cloud providers so as to avoid a share fate scenario.
Conclusion
In this blog we have shown how the tools within the RHACM toolbox can be used together to realize an open hybrid cloud architecture. The benefits of doing so include higher levels of availability and scalability, and minimize dependency on cloud vendors APIs. Combining the open hybrid cloud architecture with a centralized multi-tenancy operating model caters to the evolving needs of an adaptive enterprise and keeps operating costs down.
Sobre o autor

Mais como este
Pare de gerenciar o passado e comece a construir o futuro da TI
O próximo ponto de inflexão da IA: transformando agentes em superusuários corporativos
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem