

O InstructLab é um projeto orientado à comunidade criado para simplificar o processo de contribuição e aprimoramento de Large Language Models (LLMs) por meio da geração de dados sintéticos. Essa iniciativa lida com vários desafios enfrentados por desenvolvedores, como a complexidade da contribuição com LLMs, o problema de dispersão de modelos causado por modelos bifurcados e a falta de governança direta da comunidade. Com o suporte da Red Hat e da IBM Research, o InstructLab utiliza novos métodos de ajuste de alinhamento baseados em dados sintéticos para melhorar o desempenho e a acessibilidade de modelos. Aqui, abordaremos os problemas atuais e os desafios técnicos encontrados no ajuste fino tradicional de modelos e a abordagem do InstructLab para resolvê-los.
O desafio: dados de baixa qualidade e uso ineficiente de recursos computacionais
Conforme a concorrência no espaço de LLMs se intensifica, a abordagem é criar modelos cada vez maiores, treinados com grandes quantidades de informações da internet pública. No entanto, grande parte da internet inclui informações redundantes ou dados de linguagem não natural que não contribuem para a funcionalidade principal do modelo.
Por exemplo, 80% dos tokens usados para treinar o LLM GPT-3, tidos como base para criar as versões posteriores, têm como origem a Common Crawl, que inclui uma enorme variedade de páginas da web. Esse conjunto de dados é conhecido por conter uma combinação de texto de alta qualidade, texto de baixa qualidade, scripts e outros dados de linguagem não natural. Estima-se que uma parte significativa desses dados seja conteúdo inutilizável ou de baixa qualidade. (Análise sobre a Common Crawl)
Essa ampla rede de dados brutos leva ao uso ineficiente de recursos computacionais, aumentando os custos de treinamento, que elevam o preço final dos modelos e dificultam sua implementação em ambientes locais.
O que temos observado é um número crescente de modelos com menos parâmetros, onde a qualidade e a relevância dos dados são fatores mais críticos do que a quantidade. Modelos com uma curadoria de dados mais precisa e intencional conseguem ter melhor desempenho, demandar menos recursos computacionais e oferecer resultados de maior qualidade.
Solução do InstructLab: refinamento da geração de dados sintéticos
Uma característica exclusiva do InstructLab é a capacidade de gerar grandes volumes de dados que podem ser usados para treinamento, começando com somente um pequeno conjunto de dados. Ele utiliza a metodologia Large-scale Alignment for chatBots (LAB), que aprimora LLMs com o mínimo de dados gerados por humanos e de sobrecarga computacional. Isso simplifica a contribuição com dados relevantes, aprimorados usando a geração de dados sintéticos com um modelo para auxiliar durante o processo de geração.

Principais funcionalidades da abordagem do InstructLab:
Seleção de dados com base em taxonomia
A jornada começa com a criação de uma taxonomia — uma estrutura hierárquica que organiza várias habilidades e áreas do conhecimento. A taxonomia funciona como um roadmap para selecionar exemplos iniciais gerados por humanos, que atuam como dados iniciais no processo de geração de dados sintéticos. Esses dados são organizados em uma estrutura que simplifica a exploração do conhecimento existente do modelo e a localização de lacunas onde você pode contribuir, reduzindo informações redundantes e desorganizadas. Ao mesmo tempo, permitem o direcionamento específico de um modelo para um caso de uso ou necessidades específicas, usando apenas arquivos YAML com formatação simples no formato de pares de perguntas e respostas.

Processo de geração de dados sintéticos
A partir dos dados iniciais fundamentais, o InstructLab utiliza um modelo instrutor para gerar novos exemplos durante o processo de geração de dados. É importante observar que esse processo não usa o conhecimento armazenado pelo modelo instrutor, mas sim templates de prompt específicos que ampliam significativamente o conjunto de dados, garantindo que os novos exemplos mantenham a estrutura e a intenção dos dados originais selecionados por humanos. A metodologia LAB usa dois geradores de dados sintéticos específicos:
- Skills Synthetic Data Generator (Skills-SDG): usa templates de prompt para geração de instrução, avaliação, geração de resposta e avaliação final de pares.
- Knowledge-SDG: gera dados de instrução para domínios sem a cobertura do modelo instrutor, usando fontes de conhecimento externas para fundamentar os dados gerados
Felizmente, isso reduz significativamente a necessidade de grandes quantidades de dados anotados manualmente. Usar como referência exemplos pequenos, exclusivos e gerados por humanos permite a seleção de centenas, milhares ou milhões de pares de perguntas e respostas para influenciar os pesos e vieses do modelo.
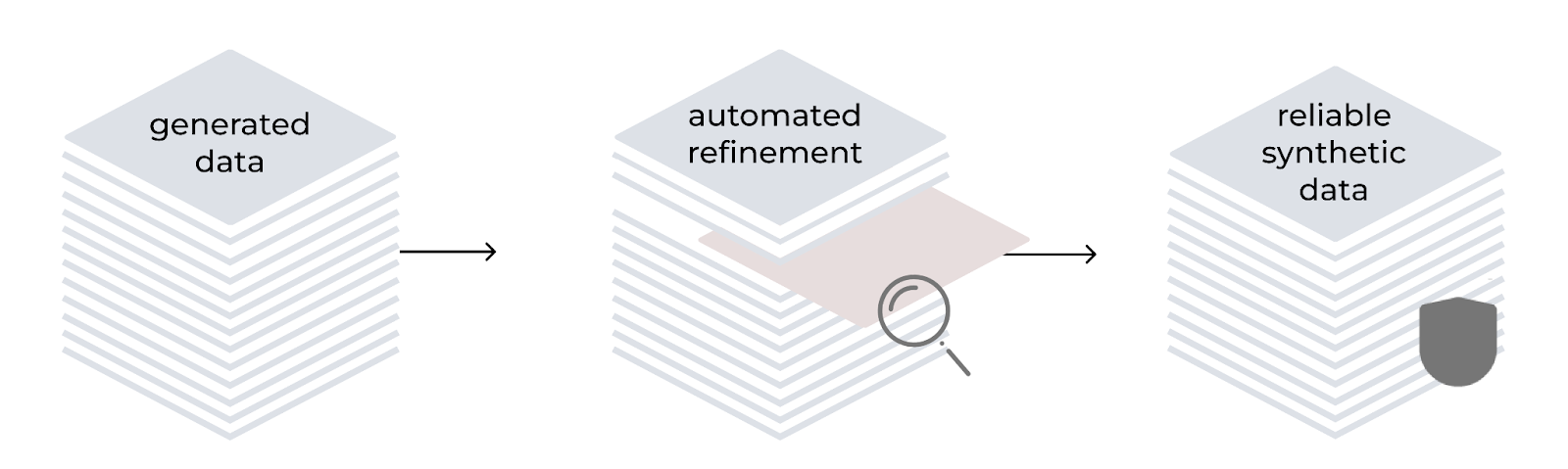
Refinamento automatizado
O método LAB incorpora um processo de refinamento automatizado para melhorar a qualidade e a confiabilidade dos dados de treinamento gerados sinteticamente. Guiado por uma taxonomia hierárquica, ele usa o modelo como um gerador e avaliador. O processo inclui geração de instruções, filtragem de conteúdo, geração de respostas e avaliação de pares usando um sistema de classificação de três pontos. Para tarefas baseadas em conhecimento, o conteúdo gerado é fundamentado em documentos de origem confiável, corrigindo possíveis imprecisões em domínios especializados.
Framework de ajuste em várias fases
O InstructLab implementa um processo de treinamento em várias fases para melhorar gradualmente o desempenho do modelo. Essa abordagem em fases ajuda a manter a estabilidade do treinamento e um buffer de repetição dos dados evita o esquecimento catastrófico, permitindo que o modelo aprenda e melhore continuamente. Os dados sintéticos gerados são utilizados em um processo de ajuste de duas fases:
- Ajuste do conhecimento: integra novas informações factuais, divididas em treinamentos de respostas curtas seguidos de respostas longas e habilidades fundamentais.
- Ajuste de habilidades: aprimora a capacidade do modelo de aplicar conhecimento em várias tarefas e contextos, com foco nas habilidades composicionais.

O framework usa pequenas taxas de aprendizado, períodos de aquecimento estendidos e um grande tamanho de lote efetivo para fins de estabilidade.
Ciclo de melhorias iterativas
O processo de geração de dados sintéticos foi desenvolvido para ser iterativo. As novas contribuições com a taxonomia podem ser usadas para gerar mais dados sintéticos, aprimorando ainda mais o modelo. Esse ciclo contínuo de melhorias ajuda a garantir que o modelo permaneça atualizado e relevante.
Resultados e importância do InstructLab
A importância do InstructLab está em sua capacidade de alcançar desempenho de ponta usando modelos instrutores disponíveis publicamente, em vez de depender de modelos proprietários. Nos benchmarks, a metodologia do InstructLab mostrou resultados promissores. Por exemplo, quando aplicados ao Llama-2-13b (resultando no Labradorite-13b) e ao Mistral-7B (resultando no Merlinite-7B), os modelos treinados com a metodologia LAB alcançaram melhor pontuação de MT-Bench em comparação com os melhores modelos atuais com ajuste fino dos respectivos modelos de base. Eles também tiveram desempenho robusto em outras métricas, como MMLU (teste de compreensão de linguagem multitarefa), ARC (avaliação de recursos de raciocínio) e HellaSwag (avaliação de inferência de senso comum).

Acessibilidade e colaboração baseadas na comunidade
Alguns dos benefícios significativos do InstructLab são sua natureza open source e o objetivo de democratizar a IA generativa para unir todas as pessoas para moldar o futuro dos modelos. A interface de linha de comando (CLI) foi desenvolvida para ser executada em hardware comum, como laptops pessoais, reduzindo o obstáculo à entrada de desenvolvedores e colaboradores. Além disso, o projeto InstructLab incentiva o envolvimento da comunidade. Ele permite que os membros colaborem com novos conhecimentos ou habilidades para um modelo principal desenvolvido regularmente e lançado no Hugging Face. Confira o modelo mais recente aqui.

O processo de geração de dados sintéticos do InstructLab, baseado na metodologia LAB, representa um avanço significativo no campo da IA generativa. Ao aprimorar LLMs com novos recursos e domínios do conhecimento, o InstructLab abre caminho para uma abordagem de desenvolvimento de IA mais colaborativa e eficaz. Se quiser ver mais informações sobre o projeto, recomendamos acessar instructlab.ai ou conferir este guia de primeiros passos para experimentar o InstructLab na sua máquina.
Sobre os autores
Cedric Clyburn (@cedricclyburn), Senior Developer Advocate at Red Hat, is an enthusiastic software technologist with a background in Kubernetes, DevOps, and container tools. He has experience speaking and organizing conferences including DevNexus, WeAreDevelopers, The Linux Foundation, KCD NYC, and more. Cedric loves all things open-source, and works to make developer's lives easier! Based out of New York.
Legare Kerrison is a Technical Marketing Manager and Developer Advocate working on Red Hat's Artificial Intelligence offerings. She is passionate about open source AI and making technical knowledge accessible to all. She is based out of Boston, MA.
Mais como este
Por que o aumento das vulnerabilidades de segurança impulsionadas pela IA exige a atuação técnica de especialistas
Avanço dos recursos pós-quânticos de SSH no Red Hat Enterprise Linux
Untangling Networks | Compiler
Technically Speaking | Defining sovereign AI with open source
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem