Introduction
I was recently asked to help a customer with their app containerization. They had a number of existing applications that used Kerberos to authenticate with external services, for example, using the Microsoft ODBC Driver for SQL Server.
The challenge facing this team was how best to implement the Kerberos client for processes running in containers, and how to ensure that the authentication remained valid for long running processes.
For those not familiar with Kerberos, it is essentially a protocol for authentication, commonly used to allow users or systems to connect to other systems. Tickets are used to authenticate, avoiding the storing, or sending, of passwords, and it is based on symmetric key cryptography.
Software systems can use Kerberos to authenticate themselves and gain access to other systems and services. A Kerberos user, or service account, is referred to as a principal, which is authenticated against a particular realm. For example, {account}@{realm}.
To support automated logins Kerberos clients use keytab files, combinations of principals and encrypted keys, that allow systems to authenticate without human interaction. Establishing an authenticated session requires an authentication request to a Key Distribution Center (KDC), typically performed with the kinit command line tool. If successful, the authentication request will result in an authentication token, with an expiry date and time, and that needs to be refreshed at regular intervals.
The containerized application will require a mechanism for authenticating the service with a KDC, obtaining a valid token, and then refreshing valid token at regular intervals within the current token expiry window. We might express this requirement as a user story:
As a developer, I would like to maintain a valid Kerberos authentication token within an application’s container namespace, so that applications’ may access services that require Kerberos authentication.
Assuming a valid keytab file is provided, this should be a simple process of running kinit at scheduled intervals, however, how do I ensure that the solution is straightforward to maintain and can scale to many applications, potentially being developed and managed by many teams?
There are a number of approaches that may be taken for refreshing the kerberos token for a containerized application. These include:
- Embedded - have the container refresh the token itself
- Externalized - have an external service refresh the token in the container
- Sidecar - Refresh the token in a sidecar container, and share with the application container
Embedded
In order for the embedded technique to work, the container’s entry point must be able to manage more than one sub-process: the primary application, and the process responsible for periodically refreshing the kerberos token.
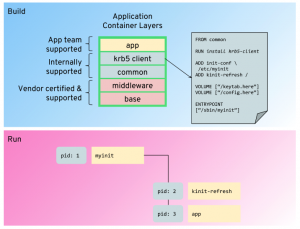
A number of 3rd party libraries exist that can help with this type of pattern, for example, supervisord, and it is certainly one of the quickest ways to implement this design. However, it may not be the most suitable approach for the following reasons:
- Running multiple processes within a container is akin to a lift-and-shift containerization approach, whereby the container is treated as a mini-Virtual Machine; the approach does not provide a clear separation between the container’s various processes.
- All applications that require these additional features will have to have their associated libraries, binaries and support scripts incorporated into the container image; meaning there is a lack of encapsulation between the application and the Kerberos token refresh logic.
- To some extent, containerized init processes are duplicating Kubernetes features, in particular maintaining the running state of the container. We should be choosing architectures which do not add this duplication.
Externalized
The externalized approach requires a separate system to be run, ideally another container, that can obtain a new token, and make this available to the application container.
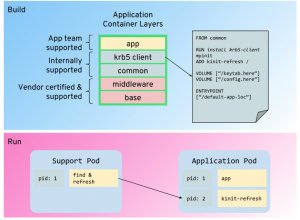
There are a number of challenges with this approach:
- Passing a token into a running container is a non-trivial bit of engineering. A simple approach may be to simply remote execute the refresh command within the target container, but then this would require that container to include all of the client scripts and binaries necessary to obtain a token.
- The approach does not scale well; if we scale out our application to many instances, we require this service to refresh the token in all of the scaled-out application instances.
While the logic for obtaining the new token is separated, this is at the cost of increased architectural complexity.
Sidecar
Placing the token refresh code in a sidecar container allows for the authentication and refresh logic to be self-contained and separated from the application container. The container’s single purpose is to refresh the application token, and once obtained it can be shared with the application container using common namespaces, for example, shared memory. The application does not require any special additional logic or libraries, just the bare minimum to support Kerberos authentication via a token.
The sidecar container can be maintained wholly separately from the main application, providing clear separation of concerns, and enabling it to have its own release cadence and management. For example, rolling out a patch to the sidecar does not require all application containers to be rebuilt, just that the applications are redeployed with the newly released sidecar image.
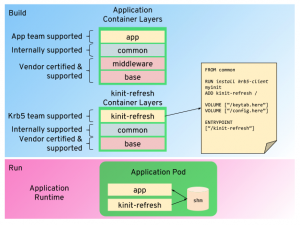
The sidecar pattern naturally scales with the application; as applications adopt this pattern, or are horizontally scaled, the sidecar container is always present and matching the applications’ deployments.
Building a Kerberos Workstation Sidecar Image
The main architectural feature of the Kerberos sidecar image is the mechanism it uses to share the authentication token with the application. When containers are deployed together in Pods using this pattern, they retain their own filesystem but do share some container namespaces. Namespaces include IPC, networking, and shared memory.
The simplest method for sharing file-based information is using a shared memory device; a file can be written to a shared memory location by one container and read from the same location by another.
When a Kerberos token is obtained, it is written to a token cache, the default location is a file in the /tmp directory. By modifying the default Kerberos configuration /etc/krb5.conf it is possible to set an alternative location, which in this case will be the shared memory device.
Before we obtain a token it is necessary to have a means of authenticating we do not want to pass a username and password to the system. The Kerberos method for automatic authentication is to use a keytab file, this file contains a set of principal (users) and key pairs. When authenticating with the Key Distribution Center (KDC) the keytab can be used instead of providing a password. As such, the keytab should be treated as a private key and managed with appropriate security.
When logging in, the Kerberos client needs to know about the KDCs providing authentication, typically one or more hostnames and, if non-standard, ports. Information about available KDCs, and other aspects of the Kerberos infrastructure can be configured on a per-realm basis, and included in the krb5.conf configuration.
Therefore there are two items that needed to be provided to the Kerberos Workstation Sidecar image:
- A krb5.conf file to configure specific properties for Kerberos authentication, and the realm’s KDC infrastructure.
- A keytab file for automatic login.
Kerberos Configuration
It is best to keep the sidecar container image relatively generic, allowing it to be reused for a number of different Kerberos environments. If the organization has standardized on a single Kerberos realm, it is preferable to retain this level of flexibility as it allows for test environments to be created with an alternative configuration.
The challenge is allowing a set of common defaults to be applied across all instances of the container while supporting specific runtime configuration for each instance.
A common technique employed to do this is to have the container’s Entrypoint perform some initialization based on passed variables, generating the configuration. In this instance, it is possible to avoid this as krb5.conf supports an included directive, allow for configuration to be extended by providing additional configuration files in a named directory.
In order to configure the appropriate Kerberos realm with KDC and domain settings, configuration extension files can be created and dropped into the named directory, which in this instance was set to /etc/krb5.conf.d. Kubernetes provides a straightforward mechanism for implementing this type of configuration via ConfigMaps. A ConfigMap can include a set of keys and data representing a filename and associated contents. The ConfigMap can then be mounted to a specific directory, which results in the files being rendered to this location as the container is started.
Common configuration was added to the built-in krb5.conf file, the settings included:
- default_ccache_name - the method and location of the token cache, configured to the shared memory location.
- default_client_keytab_name - the path and filename of the default client keytab
- default_keytab_name - the path and filename of the default keytab
Logging was configured to use STDERR by default as this is the standard mechanism for consuming container logs, and when implemented on OpenShift will allow log entries to be automatically aggregated into an ElasticSearch database.
Providing the keytab
The ConfigMap approach used for the additional configuration files would not be appropriate for the keytab; the file should be protected like a password. The alternative approach would be to use a Kubernetes Secret, in OpenShift the backing store for Secrets can be encrypted, meaning the keytab contents are protected until rendered into the container. The approach used to create the keytab file within the container uses a temporary file system, these are in-memory file systems which means that the actual file contents are never at-rest on the underlying container host.
The approach for providing the keytab file would be to create a new Secret from an original file. We then use this Secret to mount the file into the default location, as specified in the krb5.conf configuration.
Refreshing the Token
Given a container with appropriate Kerberos configuration, and a valid keytab file, it is now possible to construct a simple method of periodically refreshing the Kerberos token. In simple terms the container process must execute something similar to the following:
kinit -k
The principal needs to be provided as it is not possible to infer this information from the container’s runtime environment. Typically it would be derived from the username and hostname, neither of which are particularly helpful in a Kubernetes environment.
For example:
kinit -k myuser@EXAMPLE.COM
It is best to refresh this token at a set interval, this allows for the Entrypoint for the container could be a very simple shell script which loops the kinit request, sleeping for a designated period during each loop. There is no need for anything more sophisticated, as Kubernetes will handle any container errors that result in the init script failing or exiting.
The following script was created to provide this logic:
rekinit.sh
#!/bin/sh
allow the period to be configurable, the default is 1 hour
[[ "$PERIOD_SECONDS" == "" ]] && PERIOD_SECONDS=3600
allow for specific kinit options to be provided, but if not these are inferred based on provided keytab files
if [[ "$OPTIONS" == "" ]]; then[[ -e /krb5/krb5.keytab ]] && OPTIONS="-k" && echo "*** using host keytab"
[[ -e /krb5/client.keytab ]] && OPTIONS="-k -i" && echo "*** using client keytab"
fi
Warn if no default keytab is found
if [[ -z "$(ls -A /krb5)" ]]; then
echo "*** Warning default keytab (/krb5/krb5.keytab) or default client keytab (/krb5/client.keytab) not found"
fi
The refresh logic
while true
do
# report to stdout the time the kinit was being run
echo "*** kinit at "+$(date -I)# run kinit with passed options, note APPEND_OPTIONS allows for
# additional parameters to be configured. The verbose option is always set
kinit -V $OPTIONS $APPEND_OPTIONS# report the valid tokens
klist -c /dev/shm/ccache
# sleep for the defined period, then repeat
echo "*** Waiting for $PERIOD_SECONDS seconds"
sleep $PERIOD_SECONDS
done
Creating the Sidecar Container
The sidecar image was created from a Dockerfile. The Centos base image was used, but the general approach would be applicated to other base images. A RHEL7 image is recommended to provide a certified and supported base image.
Dockerfile
FROM centos:centos7MAINTAINER eseymour@redhat.com
install the kerberos client tools
RUN yum install -y krb5-workstation && \
mkdir /krb5 && chmod 755 /krb5# add resources, the kinit script and the default krb5 configuration
ADD rekinit.sh /
ADD krb5.conf /etc/krb5.conf
# configure the exported volumes
# /krb5 - default keytab location
# /dev/shm - shared memory location used to write token cache
# /etc/krb5.conf.d - directory for additional kerberos configuration
VOLUME ["/krb5","/dev/shm","/etc/krb5.conf.d"]
Reset current user to non-privileged to avoid ‘runing as root’ warning in OpenShift
USER 1001
Set the entry point for this container
ENTRYPOINT ["/rekinit.sh"]
Building the Sidecar Container
Naturally, the container can be built at the command line with a simple docker build command. However, I wanted to automated the creation of this image and push to my docker.io repository, therefore I created build configuration in my OpenShift cluster.
# oc create secret docker-registry dockerhub --docker-server=docker.io \
--docker-username=myaccountid \
--docker-password=********** \
--docker-email=myemail@mycompany.com
# oc new-build --name=kinit-sidecar --strategy=docker \
--to=docker.io/edseymour/kinit-sidecar --to-docker=true \
--build-secret=dockerhub https://github.com/edseymour/kinit-sidecar
Using this approach I can request a new build (either manually or automated via a webhook), and the resulting image will be automatically pushed to docker.io.
Testing
Testing introduces an interesting challenge. In order to authenticate I need a Key Distribution Center (KDC). Ideally, I should test this system in isolation, and not rely on any external dependencies, this means I really should have a containerized KDC.
Creating an Example KDC Server
There are quite a few Kerberos server images available from docker.io, however, I found many of them designed around running with docker run or docker-compose. Whilst this approach is great for running applications on a local laptop, it does tend to push developers towards a single-container architectural pattern.
A KDC server will typically run at least two services:
- kdc - the main authentication service
- kadmind - the administration and password service
For testing purposes a single container design is probably OK, but since we’ve been looking at the sidecar pattern, wouldn’t it be better to adopt this pattern for our KDC server?

Despite my preferred architecture, I did review some existing alternatives and particularly liked the approach implemented by gcavalcante8808, which I used to as a basis for my entry point script.
As this was a test environment, the Kerberos configuration can be generated by passing a few environment variables, but also supports ConfigMaps and Secrets methods.
We have three key pieces of information that need to be generated or provided:
- krb5.conf - kerberos client configuration
- krb5kdc.conf - KDC server configuration
- principal database - the KDC database containing its principals
The principal database is written to by the kadmind process, and read by the kdc process. The location of the database needs to be shared between these two processes, so if running both independently within two containers, would ideally be placed in shared memory.
The remaining configuration once created is static, and therefore copies can be made within each container. The approach I adopted was, if generating the configuration, was for the kdc process to copy the configuration to shared memory, and the kadmin process to copy from the shared memory into default locations. An alternative approach would be to simply set the environment variables used to control the default configuration locations to the shared memory, however, this would only be necessary when the configuration was being generated, so wasn’t adopted in this design.
A number of ports are opened by the various services:
- kdc - listens on 88/udp and 88/tcp
- kadmind - listens on 464/udp (password service), 749/tcp and 749/udp
For security reasons OpenShift restricts access to these ports for normal applications, therefore the default configuration adopts accepted values as:
- kdc - 8888
- kadmind - 8464, and 8749
To avoid clients requiring to specify these non-standard ports, we can create a Kubernetes Service that maps standard ports to our container ports:
88 -> 8888 (for udp and tcp)
464 -> 8464 (for udp)
749 -> 8749 (for udp and tcp)
Only a single container image is required as the Kerberos Service package includes all the required binaries. The runtime configuration, however, is for two containers running side-by-side, one providing the KDC the other the Admin service. Therefore there needed to be a mechanism of controlling the running process of the container when initialized, this was implemented by reading an environment variable: RUN_MODE.
A script was created for the container Entrypoint, which performs the following:
Identifies if running as KDC or Kadmind.
If running KDC, the script determines if an existing principal database exists, if not, one is created.
- Generates a random password for the admin user
- Generates default krb5 configuration
- Generates KDC ACL configuration
- Generates realm configuration for KDC and Kerberos clients
- Runs local kadmin process to create an admin principal for the generated realm
- Copies configuration to the shared memory location
If running Kadmind
- Wait for configuration to be shared
- Start kadmind process
Note: the default admin principal’s password is logged to stdout, meaning that anyone with access to the container’s console will be able to read this password and access the KDC server.
Using the Example KDC with kinit-sidecar
In order to test our kinit-sidecar using the example KDC we will need to add a test principal to the principle database and obtain its keytab. As the kinit sidecar image includes the Kerberos client tools, we can use the kadmin command line utility to access the KDC and perform these changes.
The following process is required:
- Login to KDC admin service using kadmin and the example admin principal
- Add a new principal to the database
- Obtain the keytab for this principal

A demo script was created in edseymour/kinit-sidecar git repository to show this working in practice. The script performs the following actions:
- Creates a new test project for the example
- Provisions the kdc server application
- Provisions an example kinit-sidecar application
- Runs the kadmin command line to create a new example principal and obtain its keytab
- Show the logs of the example application, which is defined to list active tokens. If the process works, a new active token should be displayed within a few seconds.
Example output from demo-auth.sh script
The script creates a unique project to run the test
rand_name=$(head /dev/urandom | tr -dc a-z0-9 | head -c 4 ; echo '')
project_name=krb-ex-$rand_name
oc new-project $project_name
Now using project krb-ex-j1at on server https://127.0.0.1:8443.
You can add applications to this project with the new-app command. For example, try:
oc new-app centos/ruby-22-centos7~https://github.com/openshift/ruby-ex.git
to build a new example application in Ruby. Next, the KDC server application is provisioned using krb5-server-deploy.yaml template
oc new-app -f krb5-server-deploy.yaml -p NAME=test
--> Deploying template "krb-ex-j1at/krb5-server" for "krb5-server-deploy.yaml" to project krb-ex-j1at* With parameters:
* Name=test
* Image=edseymour/kdc-server
* Kerberos Realm=EXAMPLE.COM
--> Creating resources ...
imagestream "test" created
deploymentconfig "test" created
service "test" created
--> Success
Application is not exposed. You can expose services to the outside world by executing one or more of the commands below:
'oc expose svc/test'
Run 'oc status' to view your app.
The example application is deployed using the example-client-deploy.yaml template
oc new-app -f example-client-deploy.yaml -p PREFIX=test -p KDC_SERVER=test
--> Deploying template "krb-ex-j1at/client" for "example-client-deploy.yaml" to project krb-ex-j1at* With parameters:
* Prefix=test
* KInit Sidecar Image=edseymour/kinit-sidecar
* KDC Server=test
* Kerberos Realm=EXAMPLE.COM
--> Creating resources ...
imagestream "test-kinit-sidecar" created
deploymentconfig "test-example-app" created
configmap "test-krb5-client" created
--> Success
Run 'oc status' to view your app.
The script waits for the KDC server and example application Pods to be in a Running state
wait for Pods to start and be running
watch_deploy test $project_name
watch_deploy test-example-app $project_name
*** Looking for a pod for test in krb-ex-j1at
*** Looking for a pod for test in krb-ex-j1at
*** Waiting for pods/test-1-b8tff in krb-ex-j1at to be ready
*** Waiting for pods/test-1-b8tff in krb-ex-j1at to be ready
*** Waiting for pods/test-1-b8tff in krb-ex-j1at to be ready
The kinit-sidecar container in the example application Pod is used to create a new example principal
server_pod=$(oc get pod -l app=krb5-server -o name)
admin_pwd=$(oc logs -c kdc $server_pod | head -n 1 | sed 's/.*Your\ KDC\ password\ is\ //')app_pod=$(oc get pods -l app=client -o name)
principal=$(oc env $app_pod --list | grep OPTIONS | grep -o "[a-z]*\@[A-Z\.]*")
realm=$(echo $principal | sed 's/[a-z]*\@//')
create principal
echo $admin_pwd | oc rsh -c kinit-sidecar $app_pod kadmin -r $realm -p admin/admin@$realm -q "addprinc -pw redhat -requires_preauth $principal"
create keytab
echo $admin_pwd | oc rsh -c kinit-sidecar $app_pod kadmin -r $realm -p admin/admin@$realm -q "ktadd $principal"
Authenticating as principal admin/admin@EXAMPLE.COM with the password.
Password for admin/admin@EXAMPLE.COM: WARNING: no policy specified for example@EXAMPLE.COM; defaulting to no policy
Principal example@EXAMPLE.COM created.
Authenticating as principal admin/admin@EXAMPLE.COM with the password.
Password for admin/admin@EXAMPLE.COM:
Entry for principal example@EXAMPLE.COM with kvno 2, encryption type aes256-cts-hmac-sha1-96 added to keytab FILE:/krb5/krb5.keytab.
Entry for principal example@EXAMPLE.COM with kvno 2, encryption type aes128-cts-hmac-sha1-96 added to keytab FILE:/krb5/krb5.keytab.
Finally, the log from the example application (which is just a loop running klist) is output. After a few seconds, the kinit-sidecar attempts a login with the new principal and keytab, and the results should be displayed in the example application.
oc logs -f $app_pod -c example-app
*** checking if authenticated
klist: No credentials cache found (filename: /dev/shm/ccache)
*** checking if authenticated
klist: No credentials cache found (filename: /dev/shm/ccache)
*** checking if authenticated
klist: No credentials cache found (filename: /dev/shm/ccache)
*** checking if authenticated
klist: No credentials cache found (filename: /dev/shm/ccache)
*** checking if authenticated
klist: No credentials cache found (filename: /dev/shm/ccache)
*** checking if authenticated
Ticket cache: FILE:/dev/shm/ccache
Default principal: example@EXAMPLE.COM
Valid starting Expires Service principal
03/13/18 12:49:09 03/14/18 00:49:09 krbtgt/EXAMPLE.COM@EXAMPLE.COM
renew until 03/14/18 12:49:09
Summary
A frequent pattern I see with application containers is a design based on running the container locally on a single container runtime, such as Docker. The approach tends to lead developers down the path of treating the container like a small Virtual Machine, running multiple processes within the container, and breaking common design principles such as separation of concerns. While this works perfectly well within an isolated environment, it can be difficult to scale the design, support reuse and standardize.
Within this post, while considering a specific example of migrating a Kerberos-based authentication requirement to containers, we looked at the design choices and principles available to many different types of application and hopefully demonstrate an efficient and scalable choice, that supports reuse and standardization.
Sobre o autor
Ed Seymour has over 20 years of experience working in software development and IT automation. Seymour’s career started with a small software startup. He later moved on to work at a global IT services company, where he gained experience promoting and effecting organisational change and adoption of agile methods and automation. At Red Hat, Seymour works with customers and partners on driving software delivery improvements through a combination of changes in technology, ways of working and organisational approaches. In particular, Seymour focuses on supporting and enabling shifts to cloud-native development.
Mais como este
Quatro motivos para começar a usar o image mode para Red Hat Enterprise Linux agora mesmo
Reforçada, pronta e sem custo: a segurança para containers evoluiu
Container Roundup | Compiler
Kubernetes and the quest for a control plane | Technically Speaking
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem