
Recently, I stumbled upon a StackOverflow question around StatefulSets which made me wonder how well understood they are at large. So I decided to put together a simple stateful app that can be used to experiment with a StatefulSet. In this blog post we will have a closer look at this app and see it in action.
If you're not familiar with StatefulSets, now is a good time for a refresher, consulting the official docs concerning their usage and guarantees they provide.
Meet mehdb, the Kubernetes-native key-value store
The stateful app I wrote is called mehdb and you can think of it as a naive distributed key-value store, supporting permanent read and write operations. In mehdb there is one leader and one or more followers: a leader accepts both read and write operations and a follower only serves read operations. If you attempt a write operation on a follower, it will redirect the request to the leader.

Both the leader and the followers are themselves stateless, the state is entirely kept and managed through the StatefulSet which is responsible for launching the pods in order and the persistent volumes, guaranteeing data being available across pod or node re-starts. Each follower periodically queries the leader for new data and syncs it.
Three exemplary interactions are shown in the architecture diagram above:
- Shows a
WRITEoperation using the/set/$KEYendpoint which is directly handled by the leader shard. - Shows a
READoperation using the/get/$KEYendpoint which is directly handled by a follower shard. - Shows a
WRITEoperation issued against a follower shard using the/set/$KEYendpoint and which is redirected, using the HTTP status code307, to the leader shard and handled there.
To ensure that followers have time to sync data before they serve reads readiness probes are used: the /status?level=full endpoint returns a HTTP 200 status code and the number of keys it can serve or a 500 otherwise.
StatefulSet In Action
In order to try out the following, you'll need a Kubernetes 1.9 (or higher) cluster. Also, the default setup defined in app.yaml assumes that a storage class ebs is defined.
Let's deploy mehdb first. The following brings up the StatefulSet including two pods (a leader and a follower), binds the persistent volumes to each pod as well as creates a headless service for it:
$ kubectl create ns mehdb
$ kubectl -n=mehdb apply -f app.yaml
First, let's verify that StatefulSet has created the leader (mehdb-0) and follower pod (mehdb-1) and that the persistent volumes are in place:
$ kubectl -n=mehdb get sts,po,pvc -o wide
NAME DESIRED CURRENT AGE CONTAINERS IMAGES
statefulsets/mehdb 2 2 28m shard quay.io/mhausenblas/mehdb:0.6NAME READY STATUS RESTARTS AGE IP NODE
po/mehdb-0 1/1 Running 0 28m 10.131.9.180 ip-172-31-59-148.ec2.internal
po/mehdb-1 1/1 Running 0 25m 10.130.4.99 ip-172-31-59-74.ec2.internal
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
pvc/data-mehdb-0 Bound pvc-f464d0c3-7527-11e8-8993-123713f594ec 1Gi RWO ebs 28m
pvc/data-mehdb-1 Bound pvc-6e448695-7528-11e8-8993-123713f594ec 1Gi RWO ebs 25m
When I inspect the StatefulSet in the OpenShift web console, it looks like this:
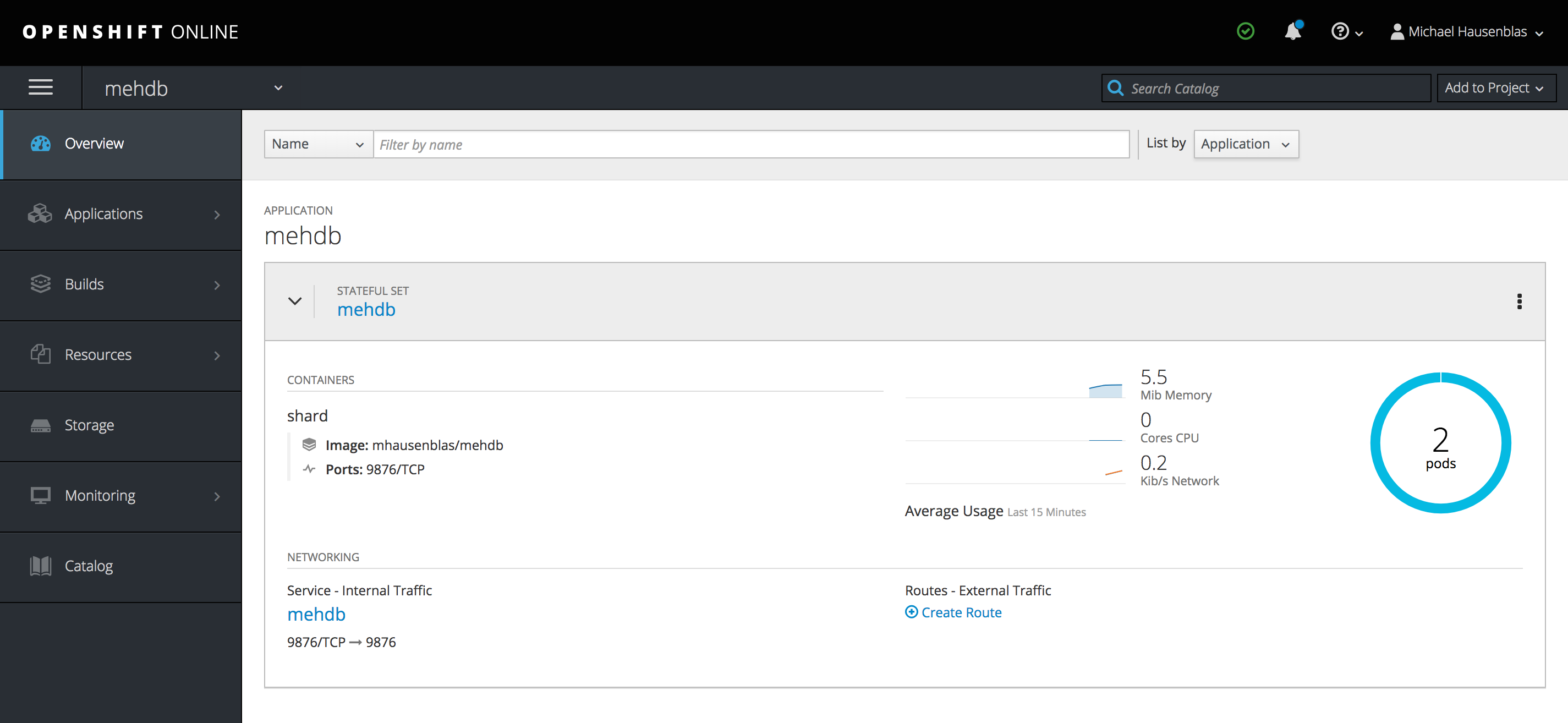
That looks all good so far, now let's check the service:
$ kubectl -n=mehdb describe svc/mehdb
Name: mehdb
Namespace: mehdb
Labels: app=mehdb
Annotations: kubectl.kubernetes.io/last-applied-configuration={"apiVersion":"v1","kind":"Service","metadata":{"annotations":{},"labels":{"app":"mehdb"},"name":"mehdb","namespace":"mehdb"},"spec":{"clusterIP":"None...
Selector: app=mehdb
Type: ClusterIP
IP: None
Port: <unset> 9876/TCP
TargetPort: 9876/TCP
Endpoints: 10.130.4.99:9876,10.131.9.180:9876
Session Affinity: None
Events: <none>
As expected, the headless service itself has no cluster IP and created two endpoints for the pods mehdb-0 and mehdb-1 respectively. Also, the DNS configuration should be updated now to return A record entries for the pods, let's check that:
$ kubectl -n=mehdb run -i -t --rm dnscheck --restart=Never --image=quay.io/mhausenblas/jump:0.2 -- nslookup mehdb
nslookup: can't resolve '(null)': Name does not resolve
Name: mehdb
Address 1: 10.130.4.99 mehdb-1.mehdb.mehdb.svc.cluster.local
Address 2: 10.131.9.180 mehdb-0.mehdb.mehdb.svc.cluster.local
Great, we're all set to use mehdb now. Let's first write some data, in our case, we store test data under the key test:
$ kubectl -n=mehdb run -i -t --rm jumpod --restart=Never --image=quay.io/mhausenblas/jump:0.2 -- sh
If you don't see a command prompt, try pressing enter.
/ $ echo "test data" > /tmp/test
/ $ curl -sL -XPUT -T /tmp/test mehdb:9876/set/test
WRITE completed/ $
Note that the -L option in above curl command makes sure that if we happen to hit the follower shard we get redirected to the leader shard and the write goes through.
We should now be able to read the data from any shard, so let's try to get it directly from the follower shard:
$ kubectl -n=mehdb run -i -t --rm mehdbclient --restart=Never --image=quay.io/mhausenblas/jump:0.2 -- curl mehdb-1.mehdb:9876/get/test
test data
OK, now that we know we can write and read data, let's see what happens when we scale the StatefulSet, creating two more followers (note that this can take several minutes until the readiness probes pass):
$ kubectl -n=mehdb scale sts mehdb --replicas=4
$ kubectl -n=mehdb get sts
NAME DESIRED CURRENT AGE
mehdb 4 4 43m
Looks like that worked out fine. But what happens if we simulate a failure, for example by deleting one of the pods, let's say mehdb-1?
$ kubectl -n=mehdb get po/mehdb-1 -o=wide
NAME READY STATUS RESTARTS AGE IP NODE
mehdb-1 1/1 Running 0 42m 10.130.4.99 ip-172-31-59-74.ec2.internal$ kubectl -n=mehdb delete po/mehdb-1
pod "mehdb-1" deleted
$ kubectl -n=mehdb get po/mehdb-1 -o=wide
NAME READY STATUS RESTARTS AGE IP NODE
mehdb-1 1/1 Running 0 2m 10.131.34.198 ip-172-31-50-211.ec2.internal
We can see that the StatefulSet detected that mehdb-1 is gone, created a replacement for it with a new IP address (on a different node) and we can still get the data from this shard via curl mehdb-1.mehdb:9876/get/test thanks to the persistent volume.
When you're done, remember to clean up. The default behavior of the StatefulSet is to remove its pods as well (if you want to keep them around, use --cascade=false):
$ kubectl -n=mehdb delete sts/mehdb
statefulset "mehdb" deleted
When you delete the StatefulSet, it does not touch the persistent volumes nor the service, so we have to take care of that ourselves:
$ for i in 0 1 2 3; do kubectl -n=mehdb delete pvc/data-mehdb-$i; done
persistentvolumeclaim "data-mehdb-0" deleted
persistentvolumeclaim "data-mehdb-1" deleted
persistentvolumeclaim "data-mehdb-2" deleted
persistentvolumeclaim "data-mehdb-3" deleted
$ kubectl -n=mehdb delete svc/mehdb
With this we conclude the exploration of StatefulSets in action and if you're interested to learn more about the topic, make sure to check out the following resources:
- Orchestrating Stateful Apps with Kubernetes StatefulSets (2018)
- Technical Dive into StatefulSets and Deployments in Kubernetes (2017)
- How to Run a MongoDb Replica Set on Kubernetes PetSet or StatefulSet (2017)
- Kubernetes: State and Storage (2017)
- This Hacker News thread (2016)
I've been using OpenShift Online for the experiment and would love to hear from others using it in a different environment (just make sure you have Kubernetes 1.9 or above). If you want to extend mehdb you need a little working knowledge of Go: the source clocks in at some 230 lines of code and it also shows how awesome the primitives Kubernetes provides are, allowing us to build custom systems on top of a well-designed API.
Sobre o autor
Mais como este
Quatro motivos para começar a usar o image mode para Red Hat Enterprise Linux agora mesmo
Reforçada, pronta e sem custo: a segurança para containers evoluiu
Scaling with Orchestrators | Compiler
Container Roundup | Compiler
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem