
Metering Operator é uma ferramenta de análise de custos e relatórios que oferece responsabilização sobre como os recursos são usados em um cluster do Kubernetes. Os administradores de cluster podem agendar relatórios com base em dados históricos de uso por pod, namespace ou cluster inteiro.
Há muitas consultas de relatório prontas e disponíveis quando você instala o operador de medição. Por exemplo, se um administrador quiser medir o uso de CPU (ou memória) para os nós (ou pods) do cluster, tudo o que você precisa fazer é instalar o operador de medição e escrever um recurso personalizado Report para produzir um relatório (mensal, por hora, entre outros).
Casos de uso
Há alguns requisitos que ouço constantemente dos clientes:
- Os nós de trabalho em um cluster do OpenShift para ambientes que não são de produção talvez não estejam em execução o tempo todo. Por exemplo, imagine que um administrador quer desativar alguns nós de trabalho com base na capacidade disponível ou durante os fins de semana. Portanto, ele gostaria de medir o uso de CPU (ou memória) de um nó mensalmente. Assim, a equipe de infraestrutura pode analisar os custos dos usuários com base no uso real do nó.
- Os clientes têm um modelo de implantação em que implantam um cluster do OpenShift dedicado para equipes específicas. Eles podem instalar o operador de medição e obter o uso do nó. No entanto, eles querem incluir no relatório de análise de custos em qual equipe (ou linha de negócios) os nós de trabalho estão sendo usados. Esse caso de uso também pode ser estendido para casos em que um cluster dedicado compartilhado tem nós "rotulados", e cada rótulo identifica qual carga de trabalho da linha de negócios (LOB) ou equipe é executada nos nós.
- Em um cluster compartilhado, a equipe de operações gostaria de fazer análise de custos das equipes com base no tempo de execução dos pods (pode ser consumo de CPU ou memória). Mais uma vez, eles gostariam de simplificar o relatório para incluir a equipe (ou linha de negócio) a que os pods estão associados.
Esses requisitos levam à criação de alguns recursos personalizados no cluster, e aprenderemos como fazer isso facilmente neste artigo. Este artigo não inclui tudo o que envolve uma instalação de um operador de medição. Consulte a documentação de instalação aqui. Para saber mais sobre como usar os relatórios prontos, consulte a documentação aqui.
Como a medição funciona?
Vamos decifrar um pouco sobre como o OpenShift Metering funciona antes de prosseguirmos para a criação de novos recursos personalizados para nosso caso de uso, conforme mencionado na seção anterior. Há um total de seis recursos personalizados que o operador de medição cria após instalado. De seis, os itens a seguir precisam de um pouco mais de explicação.
- ReportDataSources (rds): rds é o mecanismo para definir quais dados estão disponíveis e podem ser usados pelos recursos personalizados ReportQuery ou Report. Ele também permite a busca de dados a partir de várias fontes. No OpenShift, os dados são extraídos do Prometheus e do recurso personalizado ReportQuery (rq).
- ReportQuery (rq): rq contém as consultas SQL para realizar análises de dados armazenados com rds. Se um objeto rq for referenciado por um objeto Report, o objeto rq também gerenciará o que relatará quando o relatório for executado. Se referenciado por um objeto rds, o objeto rq instruirá a medição a criar uma exibição nas tabelas do Presto (criadas como parte da instalação de medição) com base na consulta renderizada.
- Report: esse recurso personalizado faz com que relatórios sejam gerados usando o recurso ReportQuery configurado. Esse é o principal recurso com o qual um usuário final do Metering Operator interagiria. Report pode ser configurado para ser executado em um agendamento.
Há muitos rds e rq prontos para uso disponíveis. Como estamos nos concentrando na medição no nível do nó, mostrarei quais precisaríamos entender para escrever nossas próprias consultas personalizadas. Execute o seguinte comando no projeto "openshift-metering":
$ oc project openshift-metering $ oc get reportdatasources | grep node node-allocatable-cpu-cores node-allocatable-memory-bytes node-capacity-cpu-cores node-capacity-memory-bytes node-cpu-allocatable-raw node-cpu-capacity-raw node-memory-allocatable-raw node-memory-capacity-raw |
Gostaríamos de nos concentrar nos dois seguintes rds: "node-capacity-cpu-cores" e "node-cpu-capacity-raw", pois queremos medir o consumo de CPU. Vamos nos concentrar no node-capacity-cpu-cores e executar o seguinte comando para ver como ele está coletando dados do Prometheus:
$ oc get reportdatasource/node-capacity-cpu-cores -o yaml spec: prometheusMetricsImporter: query: | kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id) |
Veja a consulta do Prometheus usada para buscar dados do Prometheus e armazená-los em tabelas do Presto. Executemos a mesma consulta no console de métricas do OpenShift e ver o resultado. Tenho um cluster do OpenShift com 2 nós de trabalho (cada nó com 16 núcleos) e 3 nós mestres (cada um com 8 núcleos). A última coluna, "value", registra os núcleos atribuídos aos nós.
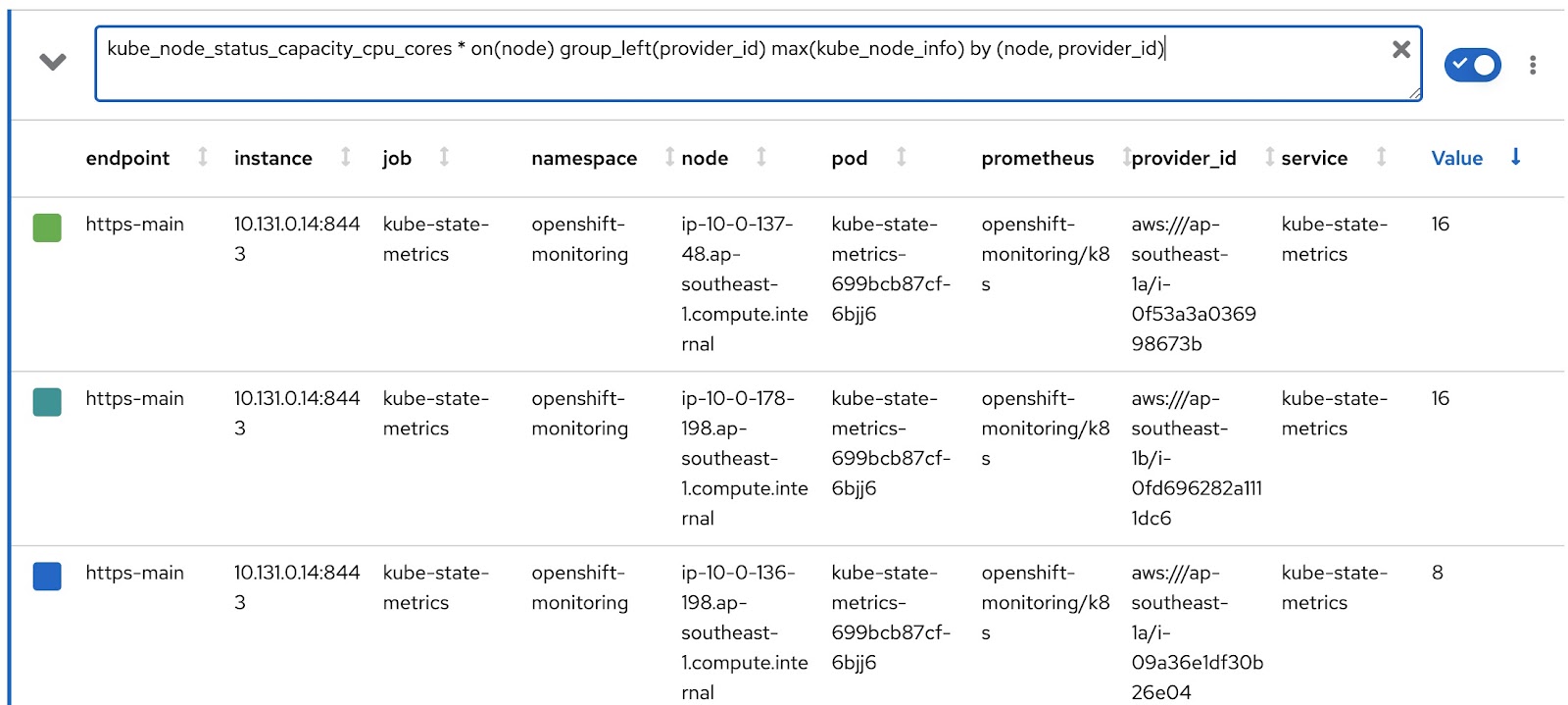
Portanto, os dados são coletados e armazenados nas tabelas do Presto. Agora, vamos nos concentrar em alguns recursos personalizados ReportQuery (rq):
$ oc project openshift-metering $ oc get reportqueries | grep node-cpu node-cpu-allocatable node-cpu-allocatable-raw node-cpu-capacity node-cpu-capacity-raw node-cpu-utilization |
Aqui, vamos nos concentrar nos rqs "node-cpu-capacity" e "node-cpu-capacity-raw". Você pode descrever essas reportqueries (consultas de relatório) e descobrir que elas estão computando dados (por quanto tempo o nó está ativo, quantas CPUs estão atribuídas etc.) e agregando dados.
Na verdade, o diagrama abaixo mostra a cadeia e como os dois rds e os dois rqs estão conectados.
node-cpu-capacity (rq) usa node-cpu-capacity-raw (rds) usa node-cpu-capacity-raw (rq) usa node-capacity-cpu-cores (rds)
Como personalizar relatórios
Vamos nos concentrar em escrever nossos rds e rq personalizados. Primeiro, precisamos alterar a consulta do Prometheus para definir se o nó funcionará como um nó mestre/de trabalho e, em seguida, incluir um rótulo de nó apropriado que identifique a qual equipe o nó pertence. A métrica do Prometheus "kube_node_role" tem função de nó de gravação de dados (como mestre ou de trabalho). Consulte a coluna "role":

A métrica do Prometheus "kube_node_labels" captura todos os rótulos aplicados a um nó. Todos os rótulos são capturados como "label_
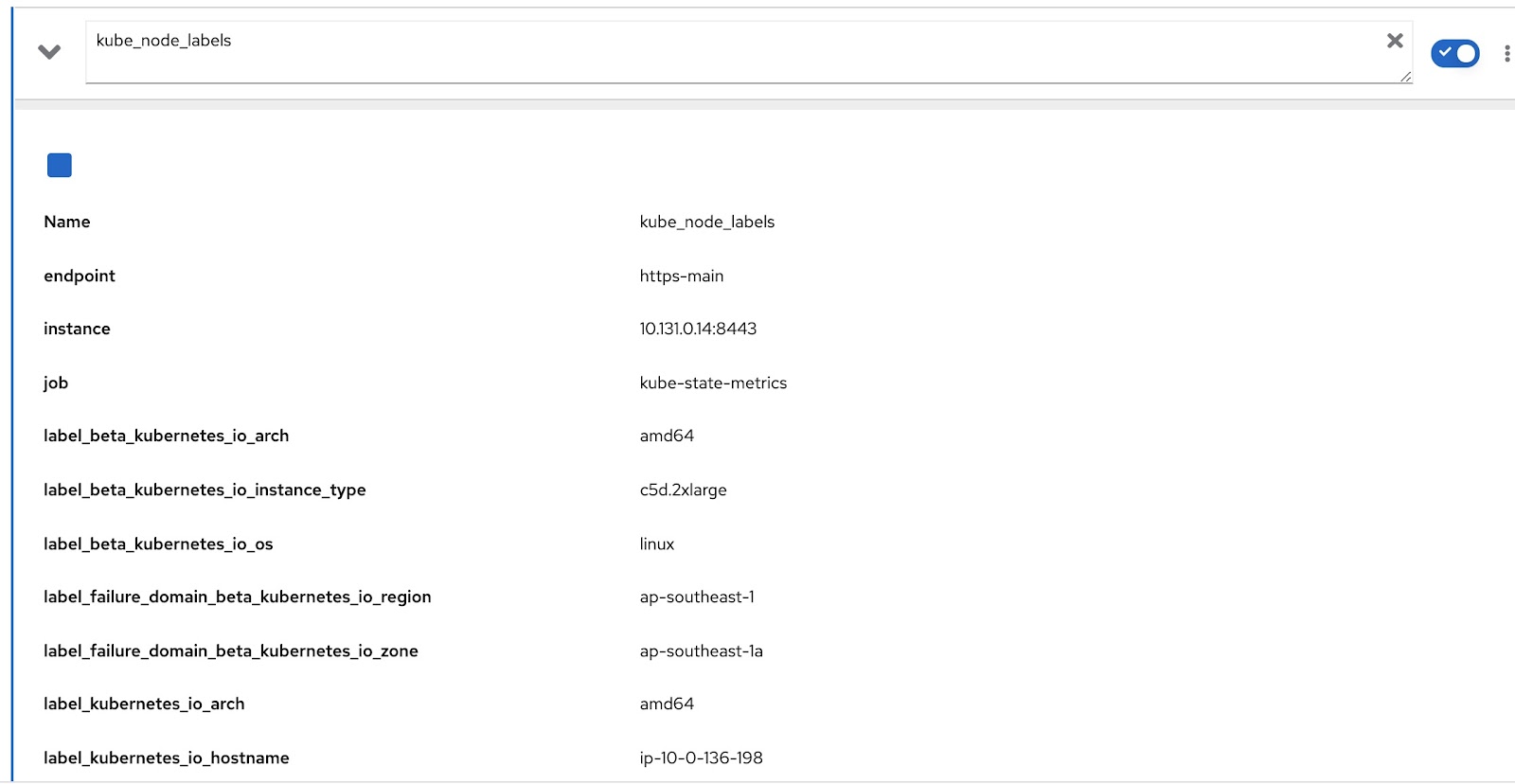
Agora, tudo o que precisamos fazer é modificar a consulta original com essas duas consultas adicionais do Prometheus para obter dados relevantes. Essa consulta fica assim:
((kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id)) * on(node) group_left (role) kube_node_role{role='worker'}) * on(node) group_right(provider_id, role) kube_node_labels
Vamos executar essa consulta no console de métricas do OpenShift e verificar se obtivemos as informações do rótulo (node_lob) e da função. Abaixo, temos label_node_lob como resultado, bem como uma função (você não pode ver as informações da função, pois a consulta gera muitas colunas, mas captura):
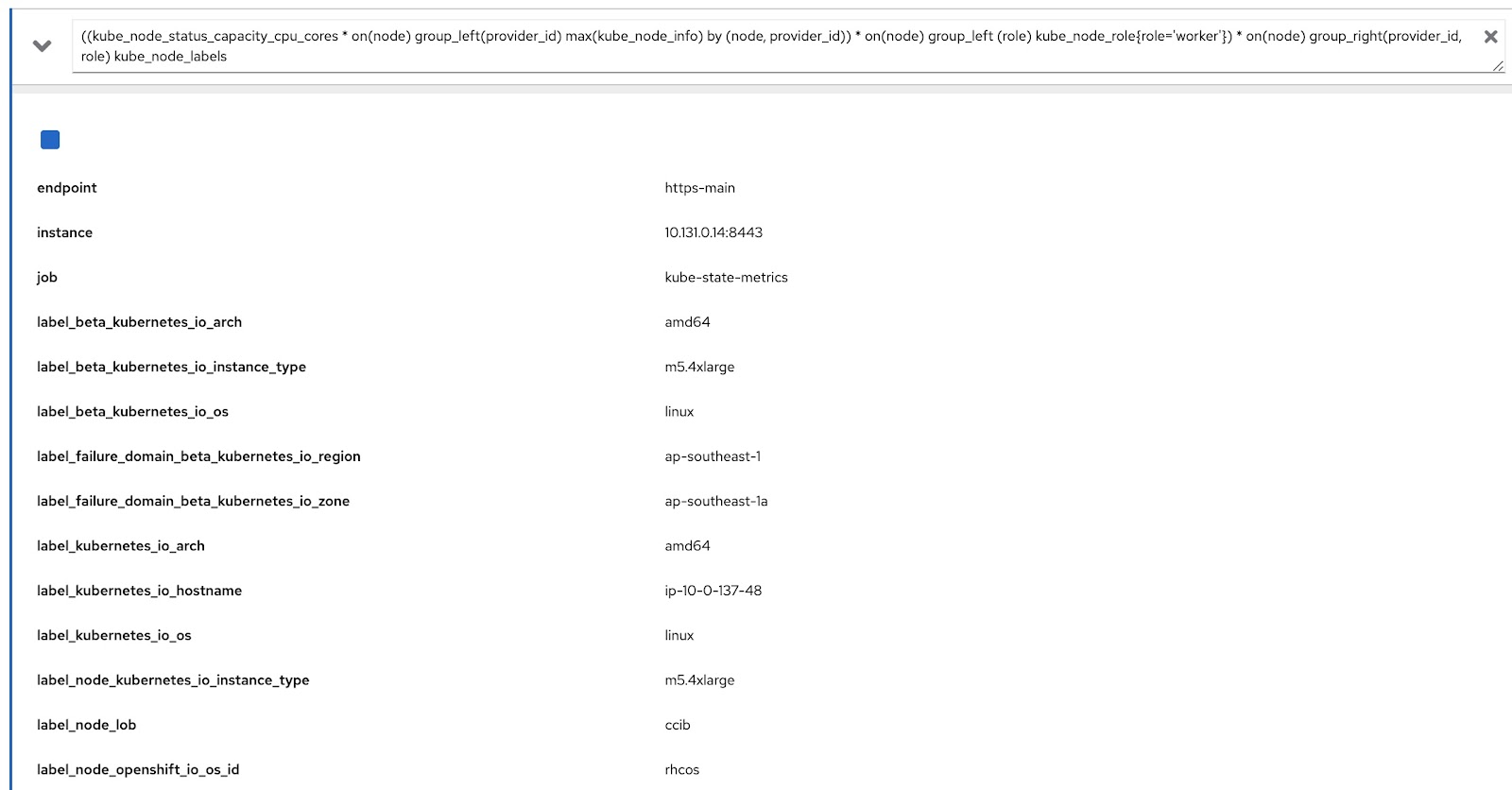
Portanto, escreveremos quatro recursos personalizados. Para simplificar, carreguei esses recursos personalizados aqui:
- rds-custom-node-capacity-cpu-cores.yaml: define a consulta do Prometheus
- rq-custom-node-cpu-capacity-raw.yaml: refere-se aos rds acima; computa dados brutos
- rds-custom-node-cpu-capacity-raw.yaml: refere-se ao rq acima e cria uma exibição no Presto
- rq-custom-node-cpu-capacity-with-cpus-labels.yaml: refere-se ao rds mencionado no nº 3 acima e computa dados com base em dados iniciais e finais de entrada. Além disso, esse é o arquivo no qual recuperamos as colunas role e node_label.
Após gravar esses arquivos YAML, acesse o projeto openshift-metering e execute os seguintes comandos:
$ oc project openshift-metering $ oc create -f rds-custom-node-capacity-cpu-cores.yaml $ oc create -f rq-custom-node-cpu-capacity-raw.yaml $ oc create -f rds-custom-node-cpu-capacity-raw.yaml $ oc create -f rq-custom-node-cpu-capacity-with-cpus-labels.yaml |
Por fim, tudo o que você precisa fazer agora é escrever um objeto personalizado Report que se refira ao último objeto rq criado acima. Você pode escrever um como mostrado abaixo. O relatório abaixo será executado imediatamente e mostrará os dados entre 15 e 30 de setembro.
$ cat report_immediate.yaml apiVersion: metering.openshift.io/v1 kind: Report metadata: name: custom-role-node-cpu-capacity-lables-immediate namespace: openshift-metering spec: query: custom-role-node-cpu-capacity-labels reportingStart: "2020-09-15T00:00:00Z" reportingEnd: "2020-09-30T00:00:00Z" runImmediately: true
$ oc create -f report-immediate.yaml |
Após executar esse relatório, você pode fazer o download do arquivo (em CSV ou JSON) por meio desta URL (altere o NOME DE DOMÍNIO conforme necessário):
O snapshot de CSV abaixo mostra os dados capturados que têm as colunas role e node_lob. A coluna "node_capacity_cpu_core_seconds" deve ser dividida por "node_capacity_cpu_cores" para chegar ao tempo de execução do nó em segundos:

Resumo
O operador de medição é muito interessante e pode ser executado em clusters do OpenShift onde quer que seja executado. Ele oferece um framework extensível para os clientes poderem escrever seus recursos personalizados para criar relatórios de acordo com suas necessidades. Todo o código usado acima está disponível aqui.
Sobre o autor
Mais como este
O paradoxo agêntico e o argumento a favor da IA híbrida
Pare de gerenciar o passado e comece a construir o futuro da TI
Scaling For Complexity With Container Adoption | Code Comments
Edge computing covered and diced | Technically Speaking
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem