
Red Hat OpenShift Virtualization 4.19 mejora considerablemente el rendimiento y la velocidad de las cargas de trabajo con muchas operaciones de E/S, como las bases de datos. La nueva función Multiple IOThreads for Red Hat OpenShift Virtualization permite que las operaciones de E/S de disco de la máquina virtual (MV) se distribuyan entre varios subprocesos de trabajo en el host, los cuales, a su vez, se asignan a colas de discos dentro de la máquina virtual. Esto permite que la máquina virtual use de manera eficiente tanto la vCPU como la CPU host para las operaciones de E/S provenientes de múltiples flujos, lo que mejora el rendimiento.
Este artículo complementa la presentación de la función de mi colega Jenifer Abrams. Como continuación, ofrezco resultados sobre el rendimiento para que puedas ajustar tu máquina virtual y así mejorar el rendimiento de E/S.
Para las pruebas, utilicé fio con máquinas virtuales Linux como carga de trabajo de E/S sintética. Estamos realizando otras pruebas con aplicaciones y también en Microsoft Windows.
Para obtener más información sobre la implementación de esta función en una máquina virtual basada en el kernel (KVM), consulta este artículo sobre IOThread Virtqueue Mapping, además de este artículo complementario en el que se muestran las mejoras en el rendimiento para las cargas de trabajo de bases de datos en máquinas virtuales que se ejecutan en un entorno de Red Hat Enterprise Linux (RHEL).
Descripción de la prueba
Probé el rendimiento de operaciones de E/S con dos configuraciones:
- un clúster con almacenamiento local que utiliza el gestor de volúmenes lógicos que brinda el operador de almacenamiento local (LSO);
- un clúster independiente que utiliza OpenShift Data Foundation (ODF).
Las configuraciones son muy diferentes y no se pueden comparar.
Realizamos pruebas en pods (para obtener un nivel de referencia) y en máquinas virtuales. Se asignaron 16 núcleos y 8 GB de RAM a las máquinas virtuales. Usé archivos de prueba de 512 GB con una máquina virtual y de 256 GB con dos. Utilicé operaciones de E/S directas en todas las pruebas. Usé reclamaciones de volumen permanente (PVC) en modo de bloque y con el formato ext4 para las máquinas virtuales, y PVC en modo de sistema de archivos también con el formato ext4 para los pods. Todas las pruebas se ejecutaron con el motor de E/S libaio.
Probé la siguiente matriz:
Parámetro | Configuración |
Tipo de volumen de almacenamiento | Local (LSO), ODF |
Cantidad de pods o máquinas virtuales | 1, 2 |
Cantidad de subprocesos de E/S (solo máquinas virtuales) | Ninguna (nivel de referencia), 1, 2, 3, 4, 6, 8, 12, 16 |
Operaciones de E/S | Lecturas y escrituras secuenciales y aleatorias |
Tamaños de los bloques de E/S (bytes) | 2000, 4000, 32 000, 1 000 000 |
Trabajos simultáneos | 1, 4, 16 |
Largo de cola de operaciones de E/S (iodepth) | 1, 4, 16 |
Usé ClusterBuster para organizar las pruebas. Las máquinas virtuales usaron CentOS Stream 9. Los pods también usaron CentOS Stream como base de imágenes de contenedores.
Almacenamiento local
El clúster de almacenamiento local constaba de cinco nodos (tres maestros y dos de trabajo) Dell R740xd con dos CPU Intel Xeon Gold 6130, cada una con 16 núcleos y 2 subprocesos (32 CPU) para un total de 32 núcleos y 64 CPU. Cada nodo tenía 192 GB de RAM. El subsistema de operaciones de E/S incluía cuatro unidades Kioxia CM6 MU NVMe de 1,6 TB de Dell. Estas estaban configuradas como varios dispositivos (MD) fragmentados en bloques con RAID 0 con ajustes predeterminados. Las reclamaciones de volumen permanente se extrajeron de esta configuración de múltiples dispositivos con el operador lvmcluster. Desafortunadamente, esta configuración bastante modesta era todo lo que tenía disponible. Es muy posible que un sistema de operaciones de E/S más rápido tenga un desempeño aún mejor al usar varios subprocesos de E/S.
OpenShift Data Foundation
El clúster de OpenShift Data Foundation (ODF) constaba de seis nodos (tres maestros y tres de trabajo) Dell PowerEdge R7625 con dos CPU AMD EPYC 9534, cada una con 64 núcleos y 2 subprocesos (128 CPU) para un total de 128 núcleos y 256 CPU. Cada nodo tenía 512 GB de RAM. El subsistema de operaciones de E/S incluía dos unidades NVMe de 5,8 TB por nodo, con replicación tripartita a través de una red de pods predeterminada de 25 GbE. No tenía acceso a una red más rápida para esta prueba, pero es probable que, con un hardware de red más nuevo, hubiese conseguido un mejor resultado.
Resumen de los resultados
Esta prueba evalúa varios subprocesos de E/S con backends de E/S específicos, los cuales tal vez no sean representativos de tu caso práctico. Las diferentes características del almacenamiento pueden ser decisivas a la hora de elegir la cantidad de subprocesos de E/S.
Estos son los resultados de las pruebas.
- Rendimiento máximo para las operaciones de E/S: para el almacenamiento local, el rendimiento máximo fue de aproximadamente 7,3 GB/s para la lectura y 6,7 GB/s para la escritura, tanto para los pods como para las máquinas virtuales. Esto no tiene en cuenta el largo de la cola de operaciones de E/S ni la cantidad de trabajos en el almacenamiento local. Eso es mucho menos de lo que se esperaría del hardware. Los dispositivos (cada uno con cuatro carriles de PCIe de cuarta generación) ofrecen una velocidad de lectura de 6,9 GB/s y de escritura de 4,2 MB/s. No investigué el motivo, pero estaba realizando la prueba en hardware antiguo. El rendimiento máximo es evidentemente mejor que el que logra una sola unidad, lo que indica que la fragmentación estaba surtiendo efecto. Para ODF, el mejor resultado fue alrededor de 5 GB/s para la lectura y 2 GB/s para la escritura.
- Las operaciones de E/S en bloques grandes (1 MB) mostraron poca o ninguna mejora porque el rendimiento ya se veía limitado por el sistema.
- La elección óptima para la cantidad de subprocesos de E/S varía según las características de la carga de trabajo y el almacenamiento. Como era de esperar, las cargas de trabajo sin una simultaneidad de E/S significativa ofrecían pocos beneficios.
- Almacenamiento local: en el caso de las máquinas virtuales con una simultaneidad de E/S significativa, lo ideal es comenzar con entre 4 y 8 subprocesos. Para las cargas de trabajo que utilizan operaciones de E/S en bloques pequeños y una gran simultaneidad, puede ser beneficioso tener más.
- ODF: si se utilizaba más de un subproceso de E/S, rara vez se obtenían beneficios significativos y, en muchos casos, no se necesitaba ninguno. Esto puede deberse a que la red de pods es relativamente lenta; es probable que las redes más rápidas generen resultados diferentes.
- En esta prueba, el uso de varios subprocesos de E/S ofreció más mejoras de rendimiento con varios trabajos simultáneos que con muchas operaciones de E/S asincrónicas.
- No hubo mucha diferencia en el comportamiento entre una y dos máquinas virtuales simultáneas hasta que se alcanzó el rendimiento de E/S máximo total subyacente (como se mencionó antes).
- La existencia de varios subprocesos de E/S no superó los resultados obtenidos con los pods con menos trabajos o una cola de operaciones de E/S más corta. Con una gran cola de operaciones de E/S con bloques pequeños, las máquinas virtuales tuvieron un desempeño considerablemente mejor que los pods en las operaciones de escritura.
En cifras
Este es el rendimiento general de las operaciones de E/S que se obtiene con varios subprocesos de E/S en mi sistema basado en el almacenamiento local. Como puedes ver, se pueden obtener muy buenos resultados con cargas de trabajo que impliquen bloques más pequeños de operaciones de E/S y mucho paralelismo con un sistema de E/S rápido. A continuación, presento otros descubrimientos sobre los beneficios que obtuve de las diferentes cantidades de subprocesos de E/S. Solo observé una leve mejora con un bloque de 1 MB porque el rendimiento ya estaba muy cerca del límite del sistema fundamental. Con un hardware aún más rápido, es posible que los subprocesos de E/S adicionales generen mejoras incluso con bloques grandes.
La mejora más importante con respecto al nivel de referencia de la máquina virtual con subprocesos de E/S adicionales | ||||||||||
(Almacenamiento local) | trabajos | iodepth | ||||||||
1 | 4 | 16 | ||||||||
tamaño | operación | 1 | 4 | 16 | 1 | 4 | 16 | 1 | 4 | 16 |
2048 | lectura aleatoria | 18 % | 31 % | 30 % | 30 % | 103 % | 192 % | 151 % | 432 % | 494 % |
escritura aleatoria | 81 % | 59 % | 24 % | 153 % | 199 % | 187 % | 458 % | 433 % | 353 % | |
lectura | 67 % | 58 % | 25 % | 64 % | 71 % | 103 % | 252 % | 241 % | 287 % | |
escritura | 103 % | 64 % | 0 % | 143 % | 99 % | 84 % | 410 % | 250 % | 203 % | |
2048 Total | 67 % | 53 % | 20 % | 97 % | 118 % | 141 % | 318 % | 339 % | 334 % | |
4096 | lectura aleatoria | 18 % | 34 % | 28 % | 33 % | 101 % | 208 % | 156 % | 432 % | 492 % |
escritura aleatoria | 95 % | 69 % | 20 % | 149 % | 200 % | 187 % | 471 % | 543 % | 481 % | |
lectura | 26 % | 53 % | 27 % | 24 % | 46 % | 66 % | 142 % | 155 % | 165 % | |
escritura | 103 % | 69 % | 0 % | 144 % | 86 % | 48 % | 438 % | 256 % | 161 % | |
4096 Total | 60 % | 56 % | 19 % | 87 % | 108 % | 127 % | 302 % | 346 % | 325 % | |
32 768 | lectura aleatoria | 16 % | 23 % | 26 % | 23 % | 71 % | 124 % | 99 % | 160 % | 129 % |
escritura aleatoria | 75 % | 71 % | 28 % | 108 % | 132 % | 116 % | 203 % | 123 % | 115 % | |
lectura | 21 % | 57 % | 25 % | 21 % | 42 % | 32 % | 77 % | 54 % | 32 % | |
escritura | 79 % | 64 % | 26 % | 104 % | 59 % | 24 % | 195 % | 45 % | 27 % | |
32 768 Total | 48 % | 53 % | 26 % | 64 % | 76 % | 74 % | 143 % | 96 % | 76 % | |
1 048 576 | lectura aleatoria | 5 % | 2 % | 0 % | 9 % | 0 % | 0 % | 17 % | 0 % | 0 % |
escritura aleatoria | 10 % | 0 % | 1 % | 6 % | 0 % | 2 % | 9 % | 0 % | 2 % | |
lectura | 12 % | 18 % | 0 % | 9 % | 0 % | 0 % | 16 % | 0 % | 0 % | |
escritura | 19 % | 0 % | 0 % | 7 % | 0 % | 0 % | 9 % | 0 % | 0 % | |
1 048 576 Total | 11 % | 5 % | 0 % | 8 % | 0 % | 1 % | 13 % | 0 % | 0 % | |
A continuación, se muestra la cantidad de subprocesos de E/S necesarios para lograr el 90 % del mejor resultado posible con un máximo de 16 subprocesos de E/S. Por ejemplo, si el mejor resultado en mi prueba con una combinación particular de operación, tamaño de bloque, trabajos y largo de la cola de operaciones de E/S fue de 1 GB/s, el indicador aquí sería la menor cantidad de subprocesos necesarios para alcanzar los 900 MB/s. Esto permite establecer una cantidad moderada de subprocesos sin dejar de lograr un buen rendimiento.
Cantidad mínima de subprocesos de E/S necesarios para alcanzar el 90 % del mejor rendimiento | ||||||||||
(Almacenamiento local) | trabajos | iodepth | ||||||||
1 | 4 | 16 | ||||||||
tamaño | operación | 1 | 4 | 16 | 1 | 4 | 16 | 1 | 4 | 16 |
2048 | lectura aleatoria | 1 | 1 | 1 | 1 | 4 | 8 | 3 | 12 | 12 |
escritura aleatoria | 1 | 1 | 1 | 3 | 16 | 12 | 8 | 12 | 12 | |
lectura | 1 | 1 | 1 | 1 | 4 | 4 | 4 | 6 | 8 | |
escritura | 1 | 1 | 0 | 2 | 12 | 6 | 8 | 6 | 6 | |
2048 Total | 1 | 1 | 1 | 2 | 9 | 8 | 6 | 9 | 10 | |
4096 | lectura aleatoria | 1 | 1 | 1 | 1 | 4 | 8 | 3 | 12 | 12 |
escritura aleatoria | 1 | 1 | 1 | 3 | 16 | 12 | 8 | 12 | 12 | |
lectura | 1 | 1 | 1 | 1 | 2 | 3 | 3 | 6 | 8 | |
escritura | 1 | 1 | 0 | 3 | 12 | 4 | 8 | 6 | 4 | |
4096 Total | 1 | 1 | 1 | 2 | 9 | 7 | 6 | 9 | 9 | |
32 768 | lectura aleatoria | 1 | 1 | 1 | 1 | 3 | 6 | 2 | 4 | 3 |
escritura aleatoria | 1 | 1 | 1 | 2 | 12 | 6 | 4 | 3 | 3 | |
lectura | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | |
escritura | 1 | 1 | 1 | 2 | 6 | 2 | 4 | 2 | 1 | |
32 768 Total | 1 | 1 | 1 | 2 | 6 | 4 | 3 | 3 | 2 | |
1 048 576 | lectura aleatoria | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
escritura aleatoria | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
lectura | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
escritura | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
1 048 576 Total | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
Resultados detallados
Para cada caso evaluado, calculé los siguientes factores de mérito:
- medición del rendimiento de E/S;
- mejor rendimiento de las máquinas virtuales (no informado directamente);
- cantidad mínima de subprocesos de E/S necesarios para lograr el 90 % del mejor rendimiento de las máquinas virtuales;
- relación entre el mejor rendimiento de las máquinas virtuales y el rendimiento de los pods;
- superación del mejor rendimiento de las máquinas virtuales en comparación con su rendimiento de referencia.
No informo la cantidad de subprocesos necesarios para obtener el mejor rendimiento porque, en muchos casos, las diferencias fueron muy pequeñas, inferiores a la variación normal en los informes de rendimiento de operaciones de E/S.
Como las características del almacenamiento local y ODF son muy diferentes, brindo resúmenes independientes para los resultados.
Todos los gráficos de rendimiento que aparecen a continuación muestran los resultados de los pods (pod), una máquina virtual de referencia sin subprocesos de E/S (0) y la cantidad especificada de subprocesos de E/S en el eje X.
Almacenamiento local
Si analizamos el rendimiento bruto, vemos que, al menos en algunos casos, el uso de varios subprocesos de E/S ofrece beneficios considerables. Por ejemplo, en un almacenamiento local con 16 trabajos y operaciones de E/S asincrónicas con un valor iodepth de 1, los subprocesos de E/S adicionales pueden producir resultados muy interesantes:
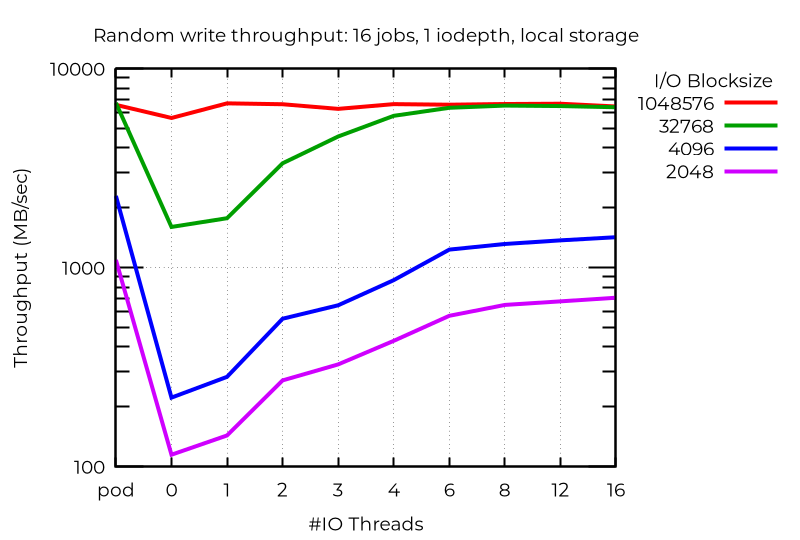
Incluso con un solo flujo de operaciones de E/S, el uso de un subproceso de E/S adicional puede generar beneficios. No es sorprendente que más de uno no ayude:

Hay casos anómalos en los que los subprocesos de E/S adicionales en realidad perjudican el rendimiento. En este caso, cuando se utilizan muchas operaciones de E/S asincrónicas con bloques pequeños, el mejor rendimiento (incluso mejor que el de los pods) se logra en realidad con las máquinas virtuales sin subprocesos de E/S exclusivos. No descubrí el motivo de esto.
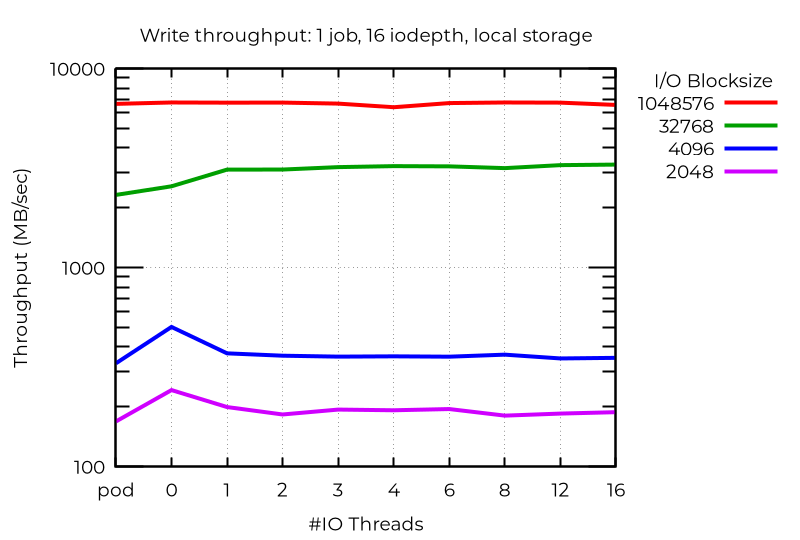
Todo esto demuestra que, para obtener el mejor rendimiento de varios subprocesos de E/S, debes experimentar con tu carga de trabajo particular.
Resultados del clúster de ODF
A diferencia del almacenamiento local, donde la escritura aleatoria de bloques pequeños demostró una mejora drástica con varios subprocesos de E/S, con ODF observé una mejora mínima, incluso con una gran cantidad de trabajos. Es probable que las redes más rápidas o con menor latencia generen mayores beneficios. Las operaciones de lectura, en especial las de lectura aleatoria, demostraron una mejora modesta, pero los beneficios de las operaciones de escritura y aquellas con menor número de trabajos fueron mínimos o inexistentes.
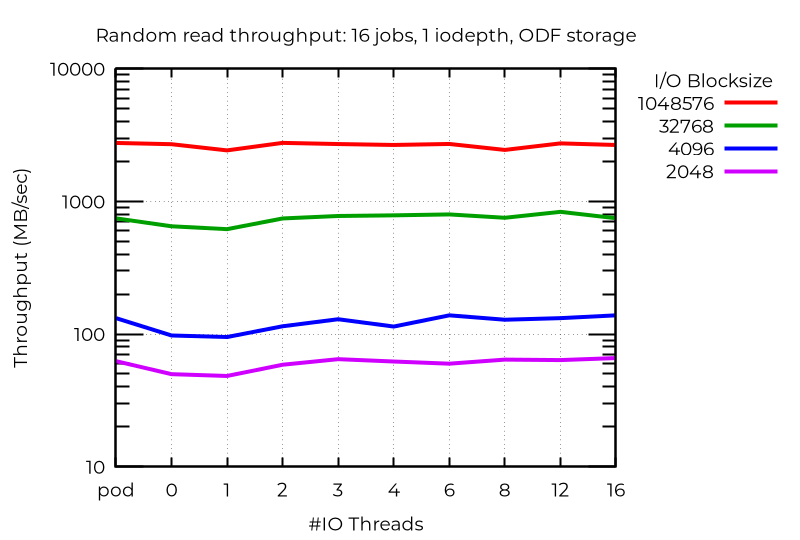
Conclusiones
Multiple IOThreads for OpenShift Virtualization es una función nueva e interesante de OpenShift 4.19 que ofrece posibles mejoras considerables en el rendimiento de las operaciones de E/S para las cargas de trabajo con E/S simultáneas, particularmente con sistemas de E/S rápidos, como el almacenamiento NVMe local utilizado en mis pruebas. Es probable que los subsistemas de E/S más rápidos sean los que más se beneficien del uso de varios subprocesos de E/S, ya que se necesitan más CPU para garantizar el buen funcionamiento de las operaciones de E/S de servidor dedicado (bare metal). Como siempre ocurre con las operaciones de E/S, las diferencias en los sistemas de E/S y las cargas de trabajo en general pueden tener efectos significativos en el rendimiento. Por ello, recomiendo poner a prueba tus propias cargas de trabajo para aprovechar al máximo esta nueva función. Espero que los resultados de mis pruebas te ayuden a tomar buenas decisiones para los subprocesos de E/S.
Prueba del producto
Red Hat OpenShift Virtualization Engine | Versión de prueba
Sobre el autor
Más como éste
Deja de administrar el pasado y comienza a forjar el futuro de TI
OpenShift: Integración consistente para la empresa híbrida
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube