
La adopción y el desarrollo de la inteligencia artificial se han acelerado con la llegada masiva de la inteligencia artificial generativa y la inteligencia artificial con agentes. A medida que surgen nuevos mercados, las empresas tienen dificultades para aprovechar la inteligencia artificial y obtener un retorno de la inversión real. Si bien las GPU han dominado la infraestructura, el aumento de los costos y la disminución de la disponibilidad debido a la demanda han llevado a los líderes a buscar alternativas que cumplan con los requisitos de rendimiento y los estándares de satisfacción del cliente.
Mientras tanto, los desarrolladores y los ingenieros que trabajan en la inteligencia artificial se enfrentan a desafíos relacionados con la configuración de la infraestructura, que es compleja y lleva mucho tiempo, y a las dificultades para diseñar stacks y arquitecturas de software para la inferencia óptima de los modelos de lenguaje de gran tamaño (LLM) con la generación aumentada por recuperación (RAG). La facilidad de uso, la seguridad de los datos propietarios e incluso la manera de comenzar a diseñar la inteligencia artificial son desafíos técnicos que pueden impedir que los desarrolladores accedan a la inteligencia artificial.
La colaboración entre Intel y Red Hat combina el rendimiento de las CPU Xeon con la capacidad de ajuste de Red Hat OpenShift AI, lo cual ofrece una base protegida y flexible para implementar la inteligencia artificial con agentes en la empresa. En esta plataforma, los clientes pueden diseñar aplicaciones y modelos de inteligencia artificial y machine learning (aprendizaje automático) de manera más segura y según sea necesario en los entornos de nube híbrida.
Para simplificar el proceso de adopción, Intel creó una serie de guías de inicio rápido sobre inteligencia artificial. Los inicios rápidos de inteligencia artificial son ejemplos de casos prácticos empresariales reales que se pueden implementar rápidamente en Xeon con OpenShift, lo que agiliza el desarrollo y el tiempo de comercialización. Estas guías de inicio rápido están disponibles en el catálogo de guías de inicio rápido sobre inteligencia artificial.
¿Por qué usar la inteligencia artificial en Xeon?
Si bien las GPU han dominado el deep learning, la inteligencia artificial generativa y la inteligencia artificial con agentes, la inferencia puede utilizar plataformas informáticas más pequeñas y rentables para cumplir con los requisitos funcionales y de rendimiento. Históricamente, las CPU han sido la plataforma elegida para el procesamiento de datos, el análisis de datos y el machine learning clásico. Esto incluye la regresión, la clasificación, la agrupación en clústeres y los árboles de decisión con métodos como las máquinas de vectores de soporte, XGBoost y K-means. Los casos prácticos incluyen la previsión financiera y minorista, la detección de fraudes y la optimización de la cadena de suministro. Esto ayuda a gestionar los costos de la infraestructura de inteligencia artificial a largo plazo. Intel Xeon está bien posicionado como nodo principal para este tipo de plataformas más pequeñas.
Características del hardware de Intel Xeon
Las características del hardware son lo que distingue a Xeon como una plataforma de CPU viable para la inteligencia artificial. El conjunto de instrucciones Advanced Matrix Extensions (AMX) y el gran ancho de banda de memoria con los módulos de memoria dual en línea de rango multiplexado (MRDIMM) son los elementos más destacados que distinguen a Xeon.
AMX se introdujo en los procesadores escalables Intel® Xeon® de cuarta generación como un acelerador de inteligencia artificial integrado, un bloque de hardware exclusivo en los núcleos, para realizar cálculos matriciales en lugar de depender de un acelerador discreto. Admite tipos de datos de menor precisión, como Bfloat16 (BF16) e INT8. Una de las principales ventajas de BF16 es que mejora el rendimiento sin sacrificar la precisión en comparación con FP32. Las aceleraciones con AMX reducen el uso de energía y recursos, y disminuyen el tiempo de desarrollo con sus optimizaciones upstream a los marcos de inteligencia artificial, como PyTorch y TensorFlow.
Los sistemas de recomendación, el procesamiento del lenguaje natural, la inteligencia artificial generativa, la inteligencia artificial con agentes y los casos prácticos de visión artificial se benefician de AMX, lo que se traduce en un mayor valor para el usuario final y la empresa.

Figura 1: Intel® AMX cuenta con mosaicos de registros 2D con instrucciones de multiplicación de matriz de mosaicos TMUL para calcular matrices grandes en una sola operación.
En la inferencia de inteligencia artificial y LLM, el cuello de botella de la memoria es el almacenamiento en caché de clave-valor (KV) debido a la alta demanda de memoria. MRDIMMS aborda este problema al cambiar la complejidad informática de cuadrática a lineal, lo que ofrece un 37 % más de ancho de banda de memoria que las RDIMM. Esto mejora el rendimiento de la memoria y reduce la latencia cuando se gestionan tareas que utilizan muchos datos durante la inferencia de la inteligencia artificial. En los sistemas en los que la memoria de la GPU es limitada, las CPU Xeon pueden descargar los datos KV, lo que libera los recursos costosos de la GPU y mantiene un alto rendimiento.
Xeon tiene varios casos prácticos en la inteligencia artificial: la inferencia, la RAG, el procesamiento seguro de datos y la inteligencia artificial con agentes. Xeon es una plataforma funcional y de alto rendimiento con software de soporte para abordar las necesidades de la inteligencia artificial sin la necesidad de GPU.
Caso práctico #1 de Xeon: Inferencia de inteligencia artificial
La inferencia de los LLM impulsa las aplicaciones, como los chatbots empresariales, los resúmenes de documentos, los asistentes de código y los canales de RAG. Las empresas del mercado medio y aquellas que buscan inteligencia artificial generativa rentable sin grandes inversiones en GPU pueden encontrar en Xeon una opción más práctica. Xeon funciona mejor con LLM de tamaño pequeño a mediano y una combinación de especialistas (MOE) con parámetros de hasta 13 000 millones y, al mismo tiempo, cumple con los estándares, como el tiempo hasta el primer token (TTFT) de 3 segundos y el tiempo por token de salida de 100 ms.
Intel ha trabajado en estrecha colaboración con la comunidad open source para optimizar la inferencia de la inteligencia artificial, incluidos vLLM y SGLang. vLLM es un motor de inferencias que ofrece un alto rendimiento y una mayor eficiencia de la memoria. En el panel de vLLM para Xeon en Pytorch.org, encontrarás las cifras de rendimiento publicadas de los LLM más conocidos, como Llama-3.1-8B-Instruct en Xeon. Intel sigue mejorando el rendimiento y agregando soporte a una lista de modelos validados. SGLang es otro marco de distribución rápida en el que Intel está trabajando para integrarlo en Xeon.
Caso práctico #2 de Xeon: La RAG y el procesamiento seguro de los datos
La RAG es eficaz para obtener resultados precisos de los LLM sin volver a entrenar los modelos. La base de conocimientos se crea al preparar los datos mediante el análisis de documentos, la fragmentación y la extracción de metadatos para crear incrustaciones que luego se almacenan en una base de datos vectorial. Todas las operaciones se pueden realizar de forma segura con Intel® Trust Domain Extensions (TDX), una tecnología informática confidencial basada en hardware. TDX utiliza máquinas virtuales (VM) aisladas por hardware para proteger los datos y las aplicaciones del acceso no autorizado. Esto permite que las empresas aprovechen rápidamente los datos propietarios disponibles para la automatización del soporte al cliente, la recuperación de documentos y la investigación jurídica. La latencia de recuperación es baja y las consultas simultáneas se pueden gestionar con Xeon.

Figura 2: Intel® TDX utiliza extensiones de hardware para gestionar y cifrar la memoria con el fin de proteger la confidencialidad y la integridad de los datos.
Caso práctico #3 de Xeon: Inteligencia artificial con agentes
Los agentes de inteligencia artificial siguen una lógica secuencial de planificación, acción, observación y reflexión. Utiliza una carga de trabajo mixta que implica la inferencia de LLM y la ejecución de herramientas, desde consultas a bases de datos y llamadas a API hasta acceso a archivos. Xeon es compatible con los servidores del protocolo de contexto de modelo (MCP), las API con agentes de LlamaStack, LangChain y los marcos de trabajo de CrewAI. La automatización de las operaciones de TI, el soporte para la toma de decisiones financieras y los agentes de la cadena de suministro son algunos de los casos prácticos empresariales objetivo.
Xeon en OpenShift: Novedades
Red Hat OpenShift AI es una plataforma de inteligencia artificial empresarial que permite gestionar todo el ciclo de vida del diseño, el entrenamiento y la implementación de modelos y aplicaciones de inteligencia artificial según sea necesario en los entornos locales, de nube híbrida y del extremo de la red. Entre las tecnologías que se incluyen en OpenShift AI, se encuentra vLLM, que ofrece una distribución optimizada de modelos de alto rendimiento y baja latencia, a la vez que reduce los costos de hardware. Hay un conjunto de modelos de terceros validados, optimizados y listos para la producción que brindan a los equipos de desarrollo más control sobre la accesibilidad y la visibilidad de los modelos para cumplir con los requisitos de seguridad y políticas. Todo esto se puede implementar automáticamente con herramientas avanzadas para poner en marcha tus proyectos de inteligencia artificial y reducir la complejidad operativa. En general, las aplicaciones de inteligencia artificial se pueden llevar a la producción según sea necesario con mayor rapidez.
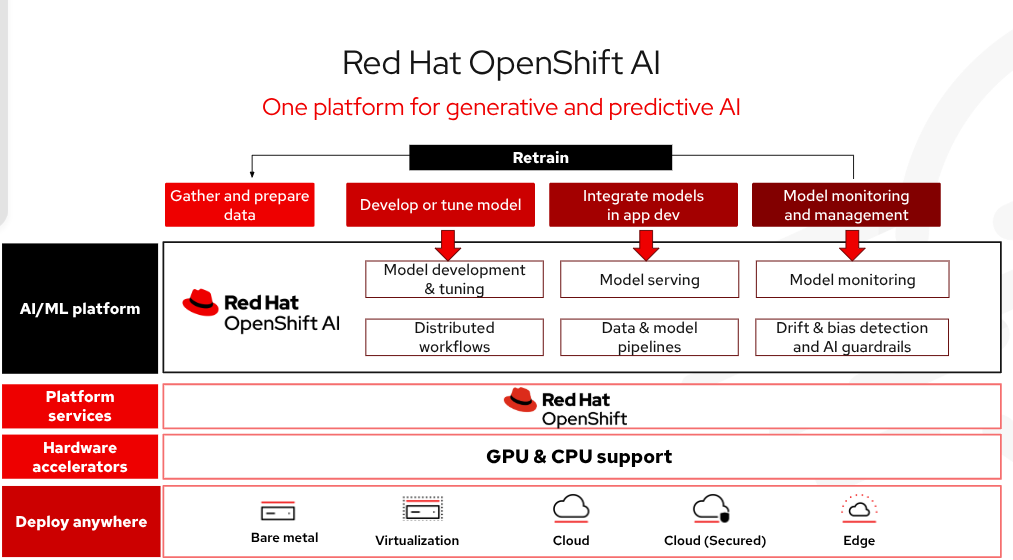
Figura 3: Red Hat OpenShift AI es una plataforma flexible y con capacidad de ajuste de inteligencia artificial (IA) y machine learning (ML) que permite que las empresas creen y distribuyan aplicaciones con inteligencia artificial según sea necesario en los entornos de nube híbrida.
Funciones
Se necesitará menos tiempo para gestionar la infraestructura de inteligencia artificial, ya que los modelos de alto rendimiento se pueden implementar fácilmente con los modelos como servicio (MaaS) y se puede acceder a ellos con los extremos de la API. Hay flexibilidad en toda la nube híbrida como software autogestionado flexible y protegido en servidores dedicados (bare metal), entornos virtuales o todas las principales plataformas de nube pública. Red Hat probó e integró la distribución de modelos y las herramientas comunes de inteligencia artificial y machine learning open source para que los desarrolladores puedan utilizarlas con facilidad. OpenShift AI también incluye llm-d, un marco open source para la inferencia de inteligencia artificial distribuida según sea necesario.
Imagen de CPU de vLLM
Intel puso a disposición una imagen vLLM para la CPU en Dockerhub diseñada a partir de la imagen base universal de Red Hat. La imagen se diseñó con AMX habilitado. Por lo tanto, se requieren procesadores Xeon® Scalable® de cuarta generación o más recientes para ejecutar esta imagen. En la actualidad, muchos modelos open source se pueden implementar rápidamente y ejecutar inferencias con alto rendimiento y baja latencia desde el primer momento.
Guías de inicio rápido sobre la inteligencia artificial
En el catálogo de inicio rápido sobre inteligencia artificial en redhat.com encontrarás ejemplos de casos prácticos empresariales listos para usar que ejecutan modelos de manera óptima con vLLM en Xeon, con la tecnología de OpenShift AI. Los desarrolladores pueden tomar estos ejemplos como puntos de partida y personalizarlos según sus necesidades o utilizarlos tal cual. Los primeros borradores de varias guías de inicio rápido sobre inteligencia artificial están disponibles en GitHub y se ejecutan de inmediato en Xeon. Todas las guías de inicio rápido finalizadas se publican a través del AI Quickstart Catalog.
- LlamaStack MCP Server: implementa los LLM con vLLM con servidores MCP, como los informes meteorológicos y las herramientas de recursos humanos.
- Servicio de CPU de los LLM: un asistente ligero de chat sobre estrategia y liderazgo de inteligencia artificial que se distribuye a un modelo de lenguaje pequeño.
- RAG: utiliza la generación aumentada por recuperación para mejorar los LLM con fuentes de datos especializadas y obtener respuestas más precisas y contextualizadas.
- Llamada de herramientas de vLLM: implementa los LLM mediante vLLM con llamadas a funciones.
Siguientes pasos
Red Hat OpenShift AI simplifica la inteligencia artificial en Xeon. El entorno gestionado y protegido establece la infraestructura de inteligencia artificial necesaria para el desarrollo, la implementación y la determinación del estado interno de los sistemas.
- Consulta el panel de control de vLLM para Xeon para conocer las cifras de rendimiento y la documentación de vLLM para diseñar o descargar las imágenes de vLLM para la CPU compatible con AMX.
- Utiliza el vLLM para la CPU basado en la imagen base universal de Red Hat de DockerHub.
- Revisa la lista de modelos compatibles para Xeon.
- Explora el catálogo de guías de inicio rápido sobre inteligencia artificial para ver ejemplos listos para ejecutarse y visita la página de inicio rápido de AI en Github para ver las guías de inicio rápido que aún están en desarrollo.
- Visita el sitio de Red Hat OpenShift AI.
Producto
Red Hat AI
Sobre el autor
Más como éste
Las amenazas de la inteligencia artificial se mueven rápido. Tus defensas también deberían hacerlo.
La inteligencia artificial con agentes es una evolución de las aplicaciones
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube