
Parece que todos los modelos de lenguaje de gran tamaño (LLM) crecen más con cada versión. Esto requiere una gran cantidad de unidades de procesamiento gráfico (GPU) para entrenar el modelo, y se necesitan más recursos durante su ciclo de vida para el perfeccionamiento, la inferencia, etc. Hay una nueva ley de Moore para estos LLM: el tamaño del modelo (que se mide según la cantidad de parámetros) se duplica cada cuatro meses.
Los LLM son costosos
El entrenamiento y la operación de un LLM son aspectos costosos en términos de recursos, tiempo y dinero. Los requisitos afectan de forma directa a las empresas que implementan esos modelos, ya sea en su propia infraestructura o utilizando uno de los proveedores principales. Además, son cada vez más grandes.
Como mencionamos, el funcionamiento de un LLM requiere una gran cantidad de recursos. Los modelos Llama 3.1 tienen 405 000 millones de parámetros y requieren 810 GB de memoria (FP16) solo para la inferencia. Se entrenaron con 15 billones de tokens en un clúster de GPU con un total de 39 millones de horas de procesamiento. Con el aumento exponencial del tamaño de los LLM, también se incrementan los requisitos informáticos y de memoria para el entrenamiento y la operación. El perfeccionamiento de Llama 3.1 requiere 3,25 TB de memoria.
El año pasado, hubo una gran escasez de GPU, y a medida que se acorta la brecha entre la oferta y la demanda, se espera que el próximo obstáculo sea la energía. Debido a que más centros de datos se ponen en funcionamiento y el consumo de electricidad de cada uno de ellos se duplica a casi 150 MW, es fácil entender el motivo por el que esto sería un problema para el sector de la inteligencia artificial.
Formas para reducir los costos de los LLM
Antes de analizar la forma de reducir los costos de los LLM, veamos un ejemplo que conozcamos. Las cámaras mejoran constantemente, y los modelos nuevos toman fotografías con mayor resolución que nunca. Sin embargo, los archivos de imágenes sin procesar pueden pesar hasta 40 MB (o más) cada uno. A menos que seas un especialista en contenido multimedia que necesite manipular estas imágenes, la mayoría de las personas están satisfechas con una versión JPEG, lo que reduce el tamaño del archivo en un 80 %. Es cierto que la compresión que utiliza el formato JPEG disminuye la calidad de la imagen en comparación con el archivo sin procesar, pero esto es suficiente para la mayoría de los casos. Además, suele ser necesario utilizar aplicaciones especiales para procesar y ver esos archivos. Por lo tanto, trabajar con ellos tiene un costo informático más alto en comparación con una imagen JPEG.
Ahora, volvamos a hablar sobre los LLM. El tamaño del modelo depende de la cantidad de parámetros, por lo que una de las estrategias posibles es utilizar uno con menos de ellos. Todos los modelos open source conocidos vienen con una variedad de parámetros, lo que te permite elegir los que mejor se adapten a las aplicaciones específicas.

Sin embargo, un LLM con una mayor cantidad de parámetros suele demostrar un mejor rendimiento que uno más pequeño en la mayoría de los indicadores. Para reducir los requisitos de recursos, puede ser mejor usar un modelo con una gran cantidad de parámetros y comprimirlo a un tamaño más pequeño. Las pruebas demostraron que la compresión con redes generativas antagónicas (GAN) puede reducir los procesos informáticos casi 20 veces.
Hay muchos enfoques para comprimir un LLM, como la cuantización, la poda, la destilación del conocimiento y la reducción de capas.
Cuantización
La cuantización cambia los valores numéricos de un modelo del formato de coma flotante de 32 bits a un tipo de datos de menor precisión. Puede ser coma flotante de 16 bits, entero de 8 bits, entero de 4 bits o incluso entero de 2 bits. Al reducir el tipo de datos de precisión, el modelo necesita menos bits durante las operaciones, lo que reduce la memoria y la capacidad informática. La cuantización se puede llevar a cabo durante el entrenamiento del modelo o después de este.
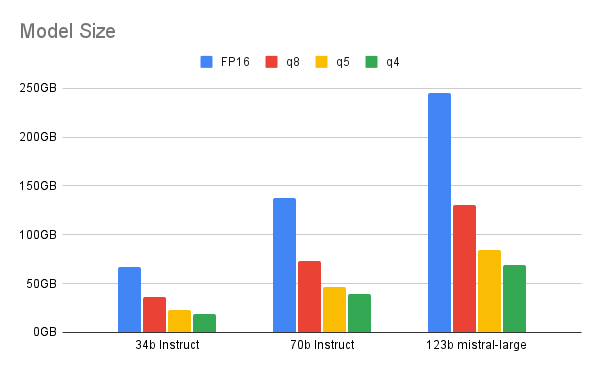
A medida que disminuimos la cantidad de bits, hay que buscar un equilibrio entre la cuantización y el rendimiento. En este informe, se destaca el rango ideal que ofrece la cuantización de 4 bits para los modelos más grandes (de al menos 70 000 millones de parámetros). Cualquier valor inferior evidencia una discrepancia notable entre el rendimiento del LLM y el de su contraparte cuantizada. Para un modelo más pequeño, la cuantización de 6 u 8 bits puede ser una mejor opción.
Gracias a este proceso, se puede ejecutar esta demostración de un LLM con generación aumentada por recuperación (RAG) en una computadora portátil.
Poda
La poda reduce el tamaño del modelo al eliminar los pesos o las neuronas menos importantes. Debe haber un equilibrio entre la reducción del tamaño y el mantenimiento de la precisión. Se puede llevar a cabo durante el entrenamiento, o antes o después de este. La poda de capas lleva esta idea más allá y elimina bloques completos. En este artículo, los autores afirman que se puede eliminar hasta el 50 % de las capas con una disminución mínima del rendimiento.
Destilación del conocimiento
Transfiere el conocimiento de un modelo grande (maestro) a un modelo más pequeño (estudiante). El modelo más pequeño se entrena a partir de los resultados del modelo de mayor tamaño en lugar de hacerlo con datos de entrenamiento más grandes.
En este informe, se explica la forma en que DistilBERT, la destilación del modelo BERT de Google, redujo el tamaño del modelo en un 40 %, aumentó la velocidad de inferencia en un 60 % y, al mismo tiempo, conservó el 97 % de sus funciones de comprensión del lenguaje.
Enfoque híbrido
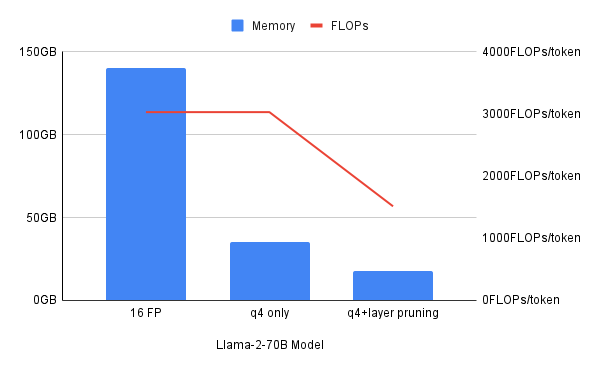
Si bien cada una de estas técnicas de compresión es útil, a veces un enfoque híbrido que las combina funciona mejor. En este informe, se señala que la cuantización de 4 bits reduce las necesidades de memoria 4 veces, pero no los recursos informáticos que se miden en operaciones de coma flotante por segundo (FLOPS). Si se combina la cuantización con la poda de capas, se podrán reducir la memoria y los recursos informáticos.
Ventajas de un modelo más pequeño
El uso de modelos más pequeños reduce considerablemente los requisitos informáticos y, al mismo tiempo, mantiene un alto nivel de rendimiento y precisión.
- Menores costos informáticos: los modelos más pequeños reducen los requisitos de CPU y GPU, lo cual puede generar ahorros significativos. Si se tiene en cuenta que las GPU de alta gama pueden costar hasta USD 30 000 cada una, cualquier reducción en el costo informático es una buena noticia.
- Menor uso de la memoria: los modelos más pequeños requieren menos memoria en comparación con sus versiones más grandes. Esto ayuda con las implementaciones de modelos en sistemas con recursos limitados, como los dispositivos del Internet de las cosas (IoT) o los teléfonos móviles.
- Inferencias más rápidas: los modelos más pequeños pueden cargarse y ejecutarse con rapidez, lo cual reduce la latencia de las inferencias. Esto puede ser muy significativo para las aplicaciones en tiempo real, como los vehículos autónomos.
- Reducción de la huella de carbono: la reducción de los requisitos informáticos de los modelos más pequeños mejora la eficiencia energética y, por lo tanto, disminuye el impacto ambiental.
- Flexibilidad de implementación: la reducción de los requisitos informáticos aumenta la flexibilidad para implementar los modelos donde se necesitan. Se pueden ejecutar para adaptarse a los cambios dinámicos en las necesidades de los usuarios o las limitaciones del sistema, que incluye el extremo de la red.
Los modelos más pequeños y menos costosos son cada vez más populares, como lo demuestran los lanzamientos recientes de ChatGPT-4o mini (un 60 % más económico que GPT-3.5 Turbo) y las innovaciones open source de SmolLM y Mistral NeMo:
- Hugging Face SmolLM: es un conjunto de modelos pequeños con 135 millones, 360 millones y 1700 millones de parámetros.
- Mistral NeMo: es un modelo pequeño con 12 000 millones de parámetros, diseñado en colaboración con Nvidia.
Esta tendencia hacia los modelos de lenguaje pequeños (SLM) se debe a las ventajas que se mencionaron más arriba. Hay muchas formas de implementarlos. Puedes utilizar un modelo diseñado previamente o técnicas de compresión para reducir un LLM que poseas. El enfoque que adoptes al elegir un modelo pequeño dependerá de tu caso práctico, así que analiza las opciones con cuidado.
Sobre el autor
Ishu Verma is an AI Solution Architect at Red Hat dabbling in emerging technologies like AI Ops, AI safety and security. He, along with fellow open source hackers, works on building enterprise focused solutions with open source technologies. Prior to Red Hat, Ishu worked in technical marketing at Intel on IoT Gateways and building end-to-end IoT solutions with partners.
Más como éste
Fortaleciendo la capa de defensa del código abierto: Red Hat se une a NVIDIA en la Open Secure AI Alliance
Acelerando el tiempo hacia el descubrimiento científico para los CDC y los NIH
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube