
With OpenShift GitOps, it is easy to declaratively manage applications, even operators, from Git repositories. You may have gone beyond YAML with Christian Hernandez’s blog about GitOps through Helm charts. You may find yourself looking forward to the next step of your GitOps journey. What is next? With OpenShift Virtualization and OpenShift GitOps together, you can now bring your virtual machine infrastructure into the GitOps model, and define VMs as code. In this article, you will learn how to handle several common use cases for managing VMs in Git.
Prerequisites
This blog is written for OpenShift Virtualization 4.8.0 and OpenShift GitOps 1.2.0. The example cluster used is OpenShift 4.8.0 on bare metal, and the only prerequisites are to install OpenShift GitOps from the Operator Catalog and ensure a supported storage class is available for automated PVC provisioning.
The Git repository used is https://github.com/RHsyseng/kubevirt-gitops. Make a fork of this repository if you would like to follow along and make customizations:
git clone https://github.com/{ your github ID }/kubevirt-gitops.git
cd kubevirt-gitops
Within the example kubevirt-gitops repository, applications are divided into subdirectories for easy use with ArgoCD. There is also a setup directory with scripts, including an install.sh that prepares the cluster for the following examples, and even substitutes the current git repo URL into all the ArgoCD applications.
ArgoCD Custom Health Checks
ArgoCD considers the health of resources as it deploys applications. For default resource types like Pods and Deployments, ArgoCD provides translations between the resources’ status fields and ArgoCD’s health states of healthy, progressing towards healthy, or failed. For custom resources like VirtualMachines and DataVolumes, we need to provide ArgoCD a semantic translation from the resources’ status fields to ArgoCD's set of states. For more information about this feature, see Custom Health Checks in the ArgoCD documentation. Three Lua scripts are provided to inform ArgoCD about DataVolumes, VirtualMachines, and VirtualMachineInstances. Install them by running either the install.sh script in the setup directory or the following:
setup/build-resourcecustomizations.sh | oc apply -f -
It is worth noting that in parallel to this article, the custom health checks mentioned here are being submitted as a feature to the upstream ArgoCD project to make KubeVirt resources known to ArgoCD without needing this extra step.
Use Case: Installing OpenShift Virtualization
OpenShift Virtualization is simple to install through the Operator Hub, but there are benefits to installing it via OpenShift GitOps. Placing the OpenShift Virtualization configuration under revision control could prove valuable. In addition, using an ArgoCD application to install OpenShift Virtualization allows us to define role bindings so ArgoCD can manage the custom resources provided by OpenShift Virtualization.
The following YAML directs ArgoCD to create an OpenShift Virtualization deployment on the cluster based on the kustomization.yaml manifest in the same directory. Important features to note are:
- The destination namespace is set to default. This has no effect on where the operator installs because all the YAML manifests include .metadata.namespace.
- repoURL should be replaced with your own fork of the repo if you ran setup/install.sh
- The application here is set to automatically synchronize. This means once the YAML is applied to the cluster, ArgoCD will start reconciling it immediately. We will discuss later why sometimes it is better to adopt a manual synchronization process.
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: openshift-virtualization
namespace: openshift-gitops
spec:
destination:
namespace: default
server: https://kubernetes.default.svc
project: default
source:
path: virtualization
repoURL: https://github.com/RHsyseng/kubevirt-gitops.git
targetRevision: HEAD
syncPolicy:
automated: {}
syncOptions:
- CreateNamespace=true
ignoreDifferences:
- kind: HyperConverged
namespace: openshift-cnv
jsonPointers:
- /spec/version
To apply the OpenShift GitOps Application that installs OpenShift Virtualization, run:
oc apply -f virtualization/application.yaml
You can follow the installation’s progress from any one of the following interfaces:
- ArgoCD Web console (Getting Started Guide)
- ArgoCD Command Line Interface
- OpenShift Web Console, under Installed Operators
- OpenShift Command Line Interface
- oc -n openshift-cnv get kubevirt
Use Case: Creating DataVolumes
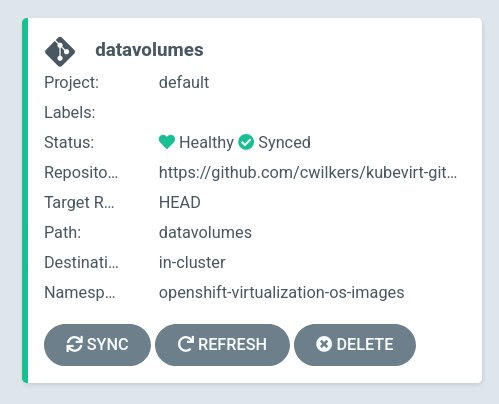
One of the most straightforward ways to create VMs in OpenShift Virtualization is by uploading cloud-ready disk images of supported operating systems as boot source images. A number of different operating systems are available for download as cloud images, including Red Hat Enterprise Linux (RHEL), Fedora, and CentOS. In the kubevirt-gitops repository, the datavolumes subdirectory contains two example DataVolumes which can be managed by OpenShift GitOps. Both CentOS and Fedora cloud images are represented here, as their download URLs are published and well-known.
To install the CentOS and Fedora DataVolumes, add the application under the datavolumes directory in the kubevirt-gitops repository:
oc apply -f datavolumes/application.yaml
Thanks to the DataVolume custom health check mentioned above, following the status of the datavolumes application will allow you to keep track of the CentOS and Fedora templates’ readiness.
In the case of RHEL and, as will be outlined later, a Microsoft Windows installation ISO, there are interactive requirements to download the desired operating system images. One useful technique to add these images to the cluster is to interactively download and host them locally for the cluster’s use. If a cluster-local web server is not available, images may be served from a workstation reachable by the cluster using a httpd container image. For example, suppose the images have been downloaded to /home/kni/images on a RHEL8 workstation. Install podman, open port 8080 in the firewall, and run:
podman run -d \
--name vm_images \
-v /home/kni/images/:/var/www/html:Z \
-p 8080:8080/tcp \
quay.io/centos7/httpd-24-centos7:latest
Now you can adjust the URLs to point to the local image, commit the changes to Git, and OpenShift GitOps will handle the download.
Use Case: Creating VirtualMachines
Now that the CentOS and Fedora DataVolumes are populated, the next step is to create Virtual Machines from them. OpenShift Virtualization uses an OpenShift specific Custom Resource called Template to easily create virtual machines for its supported operating systems. The VirtualMachine YAML definitions “centos.yaml” and “fedora.yaml” under the vms directory in the kubevirt-gitops repository were created by using the oc process command:.
oc process openshift//centos8-server-small NAME=centos-gitops1
The above example processes the “centos8-server-small” template (included by OpenShift Virtualization) from the “openshift” namespace. NAME is a parameter used to create and uniquely identify the VirtualMachine. The output of the command is a YAML definition of a VirtualMachine called “centos-gitops1” ready to be added to the cluster.
Check the YAML of the centos8-server-small template to see what other parameters are available:
oc -n openshift get template centos8-server-small -o yaml
To create the virtual machines, apply the application in the vms subdirectory of the kubevirt-gitops repository:
oc apply -f vms/application.yaml
One necessary tweak has been applied to the VMs in the repository; spec.running must be set true. If it is set to the default, false, OpenShift GitOps will continually work to shut down the VMs if they are found running.
As above, you can follow the progress from the ArgoCD console. The VirtualMachine instances will become Healthy once they are up and running.

Use Case: Creating a Custom Windows VM
Although there are cloud images of various Microsoft Windows OS versions available for download, it can be a manual process to install VirtIO drivers and guest tools required to work with the KVM engine that underlies OpenShift Virtualization. In a previous blog, Automatic Installation of a Windows VM Using OpenShift Virtualization, Eran Ifrach demonstrates that the best way of procuring cloud images with all the right drivers is to build them in cluster by downloading the latest version of the Windows installer ISO and running the installation with an autounattend.xml setup.
In the kubevirt-gitops repository, the win2k19 directory demonstrates just such an installation. Setup for this example requires more work on the user’s part than the previous ones, so we will handle them more in depth.
Taking a look at the kustomization.yaml, the first element is the install ISO itself. Download an appropriate Microsoft Windows Server 2019 installation ISO and host it locally, replacing the url value in install-iso.yaml with your own URL.
Next is the windows-install-scripts.yaml, which is a ConfigMap containing the set of files in the config subdirectory. This includes a job script, install.sh, a VirtualMachine manifest in YAML, the autounattend.xml and post-install.ps1 scripts to effect the automated Windows Server installation, and a DataVolume that clones the VirtualMachine’s root disk to create a boot source for use with the Microsoft Windows Server 2019 OS template in OpenShift Virtualization. The job script handles the tasks of creating the virtual machine, waiting for the installation to finish (signalled by the VM shutting down), cloning the root disk, and cleaning up the VM when everything is finished.
Because the job must create and delete a VirtualMachine, then create a DataVolume in another managed namespace for the boot source image clone, we create a special service account called windows-install and assign it the required roles within the local (kubevirt-gitops) and OpenShift Virtualization OS images namespaces.
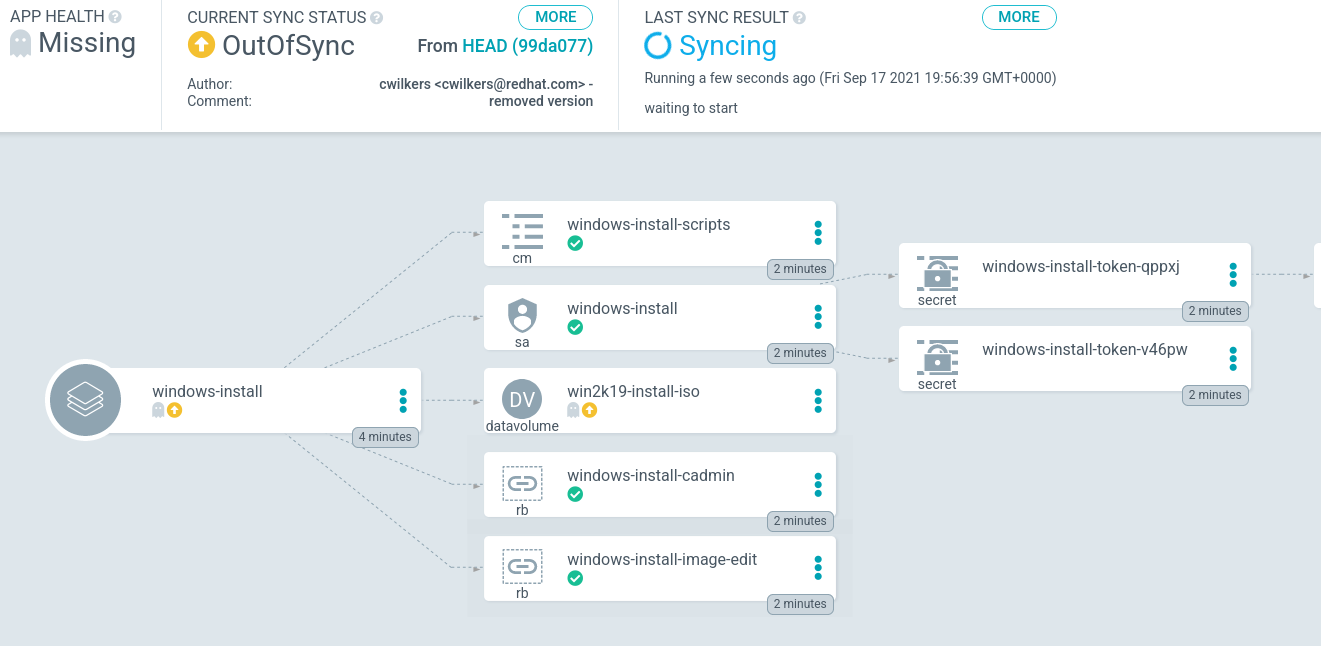
Order of operations is important as well. The job must not run before the resources it relies upon are created, and it should run only once and not be continually restarted. To enforce this order, two important settings are required. First, an annotation is added to the job’s metadata so ArgoCD can recognize it as a PostSync hook. This ensures that it is not created until the rest of the application is synchronized and healthy. Second, unlike the other examples in this article, the win2k19 application does not automatically synchronize. This prevents the job from running multiple times.
To create a Windows 2k19 boot source image, first apply the application:
oc apply -f win2k19/application.yaml

This will add the application to OpenShift GitOps, but it will remain in the OutOfSync state. To synchronize, either click the SYNC button in the ArgoCD Applications view or use the argocd command:
argocd app sync win2k19
The Windows Server 2019 installation may take upwards of 20 minutes, during which time you can check on its progress using the OpenShift Virtualization console or by watching the logs of the windows-install job:
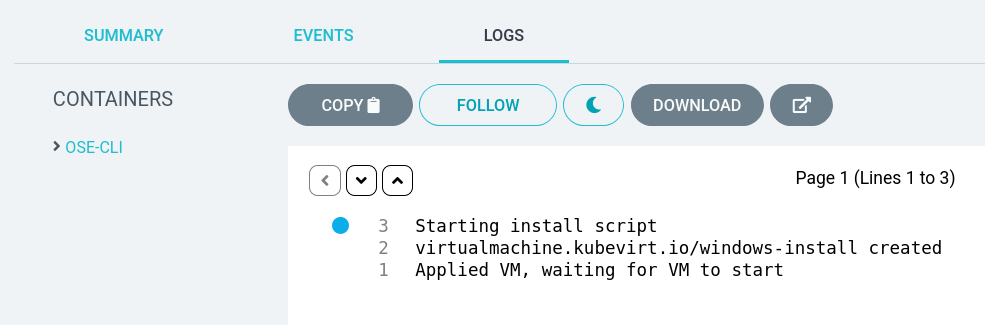
Once the job finishes, check the Virtualization Templates menu to see the newly created boot source image under Microsoft Windows Server 2019:

Conclusion
This article has covered some of the most basic use cases for combining OpenShift Virtualization and OpenShift GitOps. The ability to define virtual machines as code in a Git repository takes the infrastructure as code concept a step further. Hopefully we have inspired you to try integrating your virtual infrastructure with OpenShift GitOps and Openshift Virtualization.
Sobre el autor
Más como éste
La paradoja agéntica y los argumentos a favor de la IA híbrida
Deja de administrar el pasado y comienza a forjar el futuro de TI
SREs on a plane | Technically Speaking
DevSecOps decoded | Technically Speaking
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube