이전 블로그에서는 도메인별 맞춤화를 통해 대규모 언어 모델(LLM)을 범용 툴에서 연구용 툴로 전환하는 기능을 중점적으로 살펴보았습니다. 미세 조정된 모델은 연구 팀이 도메인 전문 지식, 기관 연구 및 추론 패턴을 시스템에 인코딩하여 단순히 발견을 보조하는 수준을 넘어 가속화할 수 있게 하는 방식입니다.
하지만 맞춤형 모델은 전체 과정의 절반에 불과합니다. 이러한 모델이 기관 규모에서 유용하게 활용되려면 모델을 학습시키고, 서비스를 제공하며, 액세스를 제어하고, 더 광범위한 연구 컴퓨팅 환경에 통합할 수 있는 플랫폼이 필요합니다. 이 플랫폼은 연구자들이 이미 사용 중인 환경인 Slurm 워크로드 관리자를 실행하는 기존 고성능 컴퓨팅(HPC) 클러스터와 쿠버네티스 기반으로 빠르게 확장 중인 클라우드 네이티브 AI 에코시스템을 연결해야 합니다.
이 블로그에서는 연구 기관이 HPC와 클라우드 네이티브 워크로드를 통합하고, 맞춤형 모델을 공유 서비스로 운영하며, 거버넌스, 재현성 또는 비용 제어를 유지하면서 조직 전체에 생성형 AI(gen AI) 기능을 제공할 수 있게 하는 플랫폼 아키텍처의 구성 방식을 살펴봅니다.
플랫폼 아키텍처: 구성 요소의 결합 방식
맞춤화 사례를 확인했으므로 이제 전체 플랫폼이 어떻게 결합되는지 살펴보겠습니다. 이 아키텍처는 일반화되어 있으므로 연구 중심 대학, 연방 정부 지원 R&D 센터, 교육 병원, 에너지 기업 또는 금융 서비스 연구 그룹 등 구축 환경에 관계없이 적용됩니다. 구성 요소는 동일하지만 각 도메인에 따른 설정은 다릅니다.
기반이 되는 Red Hat OpenShift는 플랫폼 엔지니어가 기관 규모의 공유 AI 인프라를 운영하는 데 필요한 컨테이너 오케스트레이션, 네임스페이스 거버넌스, 역할 기반 액세스 제어(RBAC), 퍼시스턴트 스토리지 통합 및 운영 툴링을 제공하는 쿠버네티스 배포판입니다.
OpenShift 상단에서 Red Hat OpenShift AI는 모델 서빙, 모델 맞춤화, 파이프라인 오케스트레이션, 데이터 사이언티스트를 위한 노트북 환경 및 AI 워크로드에 대한 관측성 등 AI 전용 기능을 제공합니다. OpenShift AI는 각 팀이 자체 머신 러닝(ML) 인프라를 관리할 필요 없이, 연구자가 관리형 셀프 서비스 인터페이스를 통해 모델을 학습, 미세 조정, 평가, 배포 및 모니터링할 수 있는 환경으로 기본 쿠버네티스 플랫폼을 전환합니다.
추론 엔진은 vLLM이며 OpenShift AI의 모델 서빙 레이어를 통해 제공됩니다. vLLM의 연속 배치 처리 및 메모리 효율적인 어텐션 메커니즘은 여러 연구 팀이 모델 엔드포인트를 동시에 사용하는 공유 추론 환경에 적합한 선택입니다. 대부분의 연구 기관과 같이 리소스가 제한된 환경에서 효율적인 추론과 비효율적인 추론의 차이는 GPU 예산의 상당한 비중을 결정합니다.
Red Hat AI Factory with NVIDIA 하드웨어 레이어는 Red Hat과 NVIDIA의 협업이 직접적으로 관련되는 부분입니다. Red Hat AI Factory with NVIDIA는 NVIDIA의 GPU 하드웨어 및 NVIDIA Inference Microservices(NIM) 프레임워크를 OpenShift AI 오케스트레이션 및 거버넌스 기능과 결합합니다. NIM 컨테이너는 NVIDIA 하드웨어에서 즉시 서비스할 수 있도록 최적화 및 검증된 모델 구성을 패키징하며, OpenShift에서 실행되므로 플랫폼의 네임스페이스 거버넌스, RBAC 및 관측성 스택을 상속합니다.
NVIDIA GPU 인프라를 도입하는 대부분의 연구 기관에 Red Hat AI Factory with NVIDIA 레퍼런스 아키텍처는 하드웨어부터 추론 서비스 실행까지 검증되고 지원되는 경로를 제공하여 수개월의 통합 작업을 줄여줍니다. NVIDIA의 NIM 카탈로그에는 주요 모델 제품군 전반의 기본 모델이 포함되어 있으며, OpenShift AI의 맞춤화 파이프라인은 도메인별 미세 조정을 통해 이러한 기본 모델을 확장합니다. 이러한 결합은 "GPU 보유" 단계에서 "연구원들에게 서비스를 제공하는 미세 조정된 임상 모델 보유" 단계로 나아가는 실질적인 경로가 됩니다.
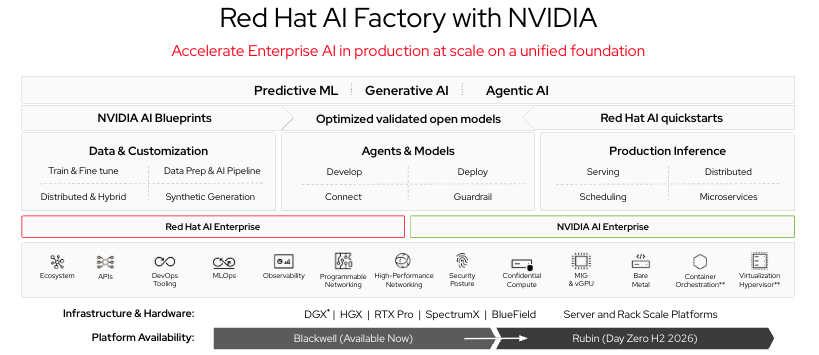
그림 1: Red Hat AI Factory with NVIDIA
HPC와 클라우드 네이티브 연결: Slinky 오퍼레이터
Slurm은 세계 유수의 슈퍼컴퓨터 다수를 구동하며 연구 기관에서 HPC 작업 제출을 위한 표준 인터페이스로 사용됩니다. 독점적인 GPU 예약, 예측 가능한 성능, 성숙한 우선순위 큐잉, 병렬 파일 시스템 및 메시지 전달 인터페이스(MPI) 스타일 워크로드와의 긴밀한 통합 등 Slurm의 강점은 매우 확실합니다. 대부분의 연구 기관 HPC 사용자는 Slurm을 잘 알고 있으며, 이들의 파이프라인은 일반적으로 Slurm용으로 작성됩니다.
지금까지의 과제는 두 개의 스케줄러, 두 개의 리소스 어카운팅 시스템, 두 가지 GPU 요청 방법, 두 개의 운영 팀으로 나뉜 Slurm 환경과 쿠버네티스 환경 간의 격차였습니다. 데이터 아티팩트는 환경 간에 수동으로 이동하며, 쿠버네티스 환경에서 작업을 대기열에 추가하는 동안 활용도가 낮은 기간에는 GPU 용량이 HPC 클러스터에서 유휴 상태로 남는 경우가 많습니다.
Slinky 오퍼레이터는 이러한 격차를 해소합니다. OpenShift에서 Slurm 워크로드를 실행하는 방법에 대한 이 블로그에서 설명한 대로, Slinky는 slurmctld 및 slurmd를 포함한 Slurm 구성 요소를 OpenShift 내부의 컨테이너화된 워크로드로 배포하고 관리하는 쿠버네티스 오퍼레이터입니다. 이는 Slurm 클러스터의 배포, 확장 및 라이프사이클 관리를 자동화하여 동일한 하드웨어에서 쿠버네티스 네이티브 워크로드와 공존할 수 있도록 지원합니다.
리서치 플랫폼 엔지니어에게 이것이 실제로 의미하는 바는 다음과 같습니다.
- 통합 리소스 스케줄링: Slurm 배치 작업과 쿠버네티스 네이티브 AI 워크로드는 동일한 GPU 풀을 공유합니다. 대규모 시뮬레이션 작업 사이의 유휴 용량은 수동 개입이나 하드웨어 재할당 없이 추론 또는 미세 조정 워크로드에 할당될 수 있습니다.
- 연구원 워크플로우 보존: sbatch를 통해 작업을 제출하는 HPC 연구원은 워크플로우를 변경할 필요가 없습니다. 연구원들에게 익숙한 Slurm 인터페이스는 그대로 유지되면서, 이제 OpenShift 내에서도 실행되어 쿠버네티스가 제공하는 모든 관측성, 라이프사이클 관리 및 거버넌스를 활용할 수 있습니다.
- 재현 가능한 환경: Slurm 작업은 컨테이너로 실행됩니다. 즉, 환경은 컴퓨트 노드에 설치된 환경이 아니라 컨테이너 이미지에 의해 정의됩니다. 이는 재현성을 획기적으로 개선하고 파이프라인을 공유하려는 기관 간의 협업을 간소화합니다.
- 단일 운영 환경(surface): 플랫폼 엔지니어는 단일 클러스터, 단일 관측성 스택 및 단일 RBAC 모델만 유지 관리하면 됩니다. Slinky는 별도의 인프라를 요구하거나 생성하지 않고, 이미 사용 중인 플랫폼에 HPC 스케줄링을 통합합니다.
Slurm의 주요 개발사인 SchedMD를 NVIDIA가 인수한 것은 이러한 융합이 업계 수준에서 지향하는 바를 잘 보여줍니다. HPC 스케줄링, 쿠버네티스 오케스트레이션 및 AI 인프라 간의 경계가 의도적으로 허물어지고 있습니다. Slinky는 이러한 융합에 대한 Red Hat의 기여이며, 현재 프로덕션 환경에서 바로 사용할 수 있습니다.
예를 들어 계산 과학을 위한 HPC 클러스터와 AI 연구를 위한 OpenShift 환경을 동시에 운영하는 연구 중심 대학의 경우, Slinky는 이 두 가지 투자를 하나의 통합된 환경처럼 활용할 수 있도록 지원합니다.
서비스형 모델(Models-as-a-Service, MaaS): 연구 기관을 위한 공유 AI 플랫폼 모델
플랫폼 융합은 인프라 문제를 해결하지만, 그만큼 중요하면서도 덜 논의되는 또 다른 문제가 있습니다. 바로 대부분의 연구 팀에 인프라 엔지니어가 없다는 점입니다. 의료 형평성 챗봇을 구축하는 임상 정보학 팀은 쿠버네티스 네임스페이스까지 직접 관리하기를 원하지 않습니다. 변이 주석을 위해 미세 조정된 모델이 필요한 유전체학 연구소는 vLLM 배포 구성을 직접 처리하고 싶어 하지 않습니다. LLM 기반 문서 분석을 실행하려는 전산 사회 과학 부서는 Helm 차트를 직접 작성하는 것을 원하지 않습니다.
이러한 문제를 해결하는 운영 모델이 바로 서비스형 모델(Models-as-a-Service, MaaS)입니다.
MaaS란 무엇입니까?
MaaS는 플랫폼 엔지니어가 AI 모델을 공유 서비스로 배포, 관리 및 운영하여 API를 통해 사용자에게 제공하는 접근 방식입니다. 연구 기관의 관점에서 보면, 이는 연구 컴퓨팅 플랫폼 팀이 GPU 클러스터를 운영하고 모델 라이프사이클을 관리하며 버전 관리, 업데이트 및 서빙 인프라를 유지 관리하는 것을 의미합니다. 반면 연구 팀은 컴퓨팅 할당이나 스토리지 마운트를 사용하는 것과 동일한 방식으로 모델 엔드포인트를 서비스로 사용합니다.
이는 연구 생산성에 상당한 영향을 미칩니다. 현재의 워크플로우와 MaaS 모델을 적용한 워크플로우를 비교해 보십시오.
현재, MaaS 없이 운영하는 경우
연구 팀에 프로젝트를 위한 미세 조정 모델이 필요합니다. 이들은 GPU 환경을 설정하고, 종속성을 설치하고, 서빙 프레임워크를 구성하며 인프라 문제를 디버깅하는 데 몇 주를 소비합니다. 인프라가 마침내 작동해야 실제 연구를 시작할 수 있으며, 이때는 이미 프로젝트를 시작한 지 몇 달이 지난 후일 수 있습니다. 작업이 완료되면 모델은 한 개인의 워크스테이션이나 회수 예정인 임시 클러스터 할당지에 남게 됩니다.
OpenShift AI 기반 MaaS를 사용하는 경우
연구 팀은 데이터세트와 도메인 요구 사항을 플랫폼 팀에 전달합니다. 연구 팀은 플랫폼 엔지니어와 협력하여 Red Hat OpenShift AI의 Training Hub를 통해 미세 조정 작업을 구성하고 실행합니다. 그 결과 생성된 모델은 공유 클러스터에서 버전이 관리되고 거버넌스가 적용된 API 엔드포인트로 제공됩니다. 유사한 요구 사항이 있는 다른 연구 팀도 동일한 엔드포인트에 액세스할 수 있습니다. 새로운 데이터로 모델을 업데이트해야 하는 경우, 교육 파이프라인을 다시 실행하고 동일한 거버넌스 프로세스를 통해 새 버전을 승인합니다.
플랫폼 팀은 인프라를 관리하고 연구 팀은 연구 본연의 업무에 집중합니다. 이러한 분업은 기관 전체에서 AI 역량을 확장하는 데 도움이 됩니다.

그림 2: 과학 연구를 위한 HPC, 클라우드 네이티브 및 MaaS(Models-as-a-Service)의 융합
플랫폼 엔지니어에게 Red Hat OpenShift AI 기반 MaaS(일명 "서비스로서의 연구")는 필요한 운영 제어 기능을 제공합니다. 여기에는 특정 연구 프로젝트가 GPU 용량을 독점하지 못하도록 방지하는 네임스페이스 수준의 리소스 쿼터, 레지스트리를 통한 모델 버전 관리, 배포 권한과 사용 권한을 제어하는 RBAC, 통합 대시보드를 통한 모든 서빙 워크로드의 관측성 등이 포함됩니다.
의과대학, 계산 생물학과, 정보 대학, 데이터 과학 연구소 등 여러 연구 그룹이 동일한 플랫폼에서 실행되는 연구 기관의 경우, MaaS는 플랫폼 팀이 연구 프로젝트 수에 따라 인력을 선형적으로 늘리지 않고도 수요에 대응할 수 있게 해줍니다.
데이터 중력: 연구 현장에 AI 도입
연구 분야에는 데이터 중력 문제가 존재합니다. 임상 기록, 게놈 서열, 시뮬레이션 결과와 같은 가장 가치 있는 데이터세트는 이미 규모가 방대하고 분산되어 있으며, 비용, 지연 시간 또는 거버넌스 제약으로 인해 이동이 불가능한 경우가 많습니다. 페타바이트급 데이터를 클라우드 엔드포인트로 이동하는 것은 비효율적이며 불가능할 때가 많습니다.
여기서 논의하는 플랫폼은 데이터를 AI로 가져오는 것이 아니라, AI를 데이터가 있는 곳으로 가져옵니다. 데이터가 이미 존재하는 위치(온프레미스, 실험실, 보안 연구 환경 등)에서 모델 교육, 미세 조정 및 추론을 실행함으로써 성능과 컴플라이언스를 유지하면서 불필요한 데이터 이동을 방지할 수 있습니다.
결론적으로 이는 단순한 최적화가 아니라 아키텍처상의 필수 요구 사항입니다. 모델이 데이터에 가까울수록 반복 루프가 빨라지고 비용이 절감되며, 대규모 연구 워크플로우 전반에서 AI를 운영화하는 것이 더욱 실용적입니다.
이 아키텍처가 적용되는 분야: 다양한 산업의 연구 환경
물론 이 플랫폼은 학술 연구에만 국한되지 않습니다. 이 아키텍처는 도메인 전문성이 중요하고, 데이터 거버넌스로 인해 클라우드 네이티브 배포가 제한되며, 연구 워크로드가 HPC에서 클라우드 네이티브 스펙트럼에 걸쳐 있는 모든 기관에 범용적으로 적용됩니다.
- 연구 중심 대학교 및 연방 정부 지원 연구 개발 센터(FFRDC): 국립 연구소와 같은 대학교 및 연방 정부 지원 연구 개발 센터에는 일반적으로 이 아키텍처가 해결하는 인프라가 구축되어 있습니다. 여기에는 시뮬레이션 중심 연구를 위한 HPC 클러스터, 데이터 사이언스 그룹의 증가하는 클라우드 네이티브 AI 수요, 그리고 서로 다른 컴퓨팅 요구 사항을 가진 수십 개의 연구 그룹을 지원하려는 플랫폼 엔지니어링 팀이 포함됩니다.
- 의료 기관 및 수련 병원: 임상 AI는 연구 투자가 가장 빠르게 성장하는 분야 중 하나이며, 모델 정확도, 데이터 거버넌스 및 안전 요구 사항 측면에서 가장 까다로운 분야 중 하나입니다. 범용 클라우드 모델은 환자 데이터 프라이버시 보호 의무로 인해 도입이 불가능한 경우가 많습니다. 이러한 조직에는 온프레미스에서 실행되고 감사 로깅 및 액세스 제어 기능을 갖추었으며 관리형 기관 플랫폼을 통해 제공되는 미세 조정된 모델이 필요합니다.
- 국방 및 정보 연구: 기밀 또는 통제된 환경에서 운영되는 FFRDC 및 방산 업체는 임상 연구와 동일한 데이터 거버넌스 요구 사항을 공유하며, 클라우드 API 사용을 금지하는 보안 분류 요구 사항으로 인해 상황이 더욱 복잡합니다. 이러한 환경에서는 온프레미스 모델 서빙, 폐쇄망 운영, 그리고 내부적으로 기밀 도메인 지식을 포함하는 미세 조정된 모델이 필요합니다.
- 금융 서비스 및 퀀트 연구: 금융 서비스 연구 그룹(예: 퀀트 연구, 리스크 모델링, 규제 분석)은 독점 데이터를 사용하며 외부 API로 전송할 수 있는 데이터를 제한하는 규제 제약에 따라 운영됩니다. 이러한 그룹에는 내부 연구 데이터를 기반으로 학습되고, MaaS를 통해 온프레미스에서 제공되며, 기존 연구 워크플로우와 통합되는 관리형 API를 통해 액세스할 수 있는 미세 조정된 모델이 필요합니다.
- 에너지 및 산업 연구: 석유 및 가스, 유틸리티, 산업 연구 조직은 재료 연구, 예측 유지 보수 및 지구 물리 분석을 위해 증가하는 ML 파이프라인과 함께 컴퓨팅 집약적인 시뮬레이션 워크로드를 실행합니다. Slinky는 이 부문에서 특히 유용합니다. Slurm 기반 시뮬레이션 워크플로우가 표준이며, 이러한 시뮬레이션의 다운스트림에서 ML 기반 분석이 점점 더 많이 요구되기 때문입니다.
이러한 모든 맥락에서 아키텍처 패턴은 일관됩니다. 즉, HPC와 클라우드 네이티브 스케줄링을 통합하고, 도메인 특성에 맞게 모델을 맞춤화하며, 공유 MaaS 플랫폼을 통해 효율적으로 제공하고, 기관 수준에서 액세스를 관리하는 것입니다.
통합된 플랫폼이 제공하는 기능
예를 들어, 전체 아키텍처를 배포한 연구 기관은 다음과 같은 기능을 활용할 수 있습니다.
계산 유전체학(computational genomics) 연구자는 수년 동안 HPC 작업을 제출해 온 방식 그대로 Slurm을 통해 대규모 변이 호출 작업을 제출합니다. Slinky 오퍼레이터는 미세 조정된 추론 엔드포인트를 제공하는 동일한 GPU 노드에서 해당 작업을 OpenShift의 컨테이너화된 워크로드로 스케줄링합니다. 작업이 완료되면 출력 결과는 HPC 및 쿠버네티스 환경 모두에서 액세스할 수 있는 공유 오브젝트 저장소에 저장됩니다.
의과대학의 임상 NLP 연구자는 개체명 인식(NER) 작업을 위해 비식별화된 임상 기록으로 미세 조정된 모델이 필요합니다. 연구원은 플랫폼 팀과 협력하여 NVIDIA NIM 카탈로그의 기본 모델을 사용하고, OpenShift AI의 Training Hub를 통해 LoRA(Low-Rank Adaptation) 미세 조정 작업을 실행합니다. 생성된 모델은 버전 관리되며 MaaS 엔드포인트로 제공됩니다. 유사한 NLP 태스크를 수행하는 다른 2개의 연구 팀이 즉시 동일한 엔드포인트를 사용하기 시작하면서, 미세 조정 비용이 기관 전체에 분산됩니다.
FFRDC의 사이버 보안 연구 그룹은 LLM을 사용하여 위협 인텔리전스 리포트를 대규모로 분석해야 합니다. 데이터에 클라우드 API 사용을 금지하는 민감도 제약 조건이 있으므로, 모델은 OpenShift 클러스터의 온프레미스 환경에서 전적으로 실행됩니다. 이 모델은 부족한 레이블 지정 데이터세트를 보강하기 위해 InstructLab 합성 데이터 생성을 사용하여 분류된 데이터세트를 기반으로 미세 조정되었습니다. 엔드포인트는 적절한 RBAC 바인딩이 있는 네임스페이스에서만 액세스할 수 있습니다.
동일한 클러스터에서 이러한 모든 워크로드를 관리하는 플랫폼 엔지니어는 단일 관측성 대시보드를 통해 Slurm 및 쿠버네티스 워크로드 전반의 GPU 사용률, 엔드포인트별 모델 서빙 대기 시간, 학습 작업 대기열 깊이, 네임스페이스별 리소스 할당량 사용률을 확인합니다. 워크로드 간의 리소스 경합은 수동 개입 없이 통합 스케줄러를 통해 해결됩니다.
이러한 각 기능은 현재 Red Hat AI 및 OpenShift AI에서 사용할 수 있습니다. 또한 NVIDIA 참조 아키텍처가 포함된 Red Hat AI Factory를 통해 NVIDIA 하드웨어와 통합되며, Slinky 오퍼레이터를 통해 HPC 워크플로우로 확장됩니다.
맺음말
차세대 혁신을 주도할 연구원들은 LLM을 기존 방법의 보완책이 아닌 연구 워크플로우의 핵심이자 주요 도구로 사용할 것입니다.
연구원들이 플랫폼에 요구하는 것은 인프라 엔지니어가 아니어도 사용할 수 있는 기능입니다. 연구원들에게는 해당 도메인을 정확히 파악하는 미세 조정된 모델, 빠르고 신뢰할 수 있는 추론, 다른 클러스터로 컨텍스트를 전환할 필요가 없는 HPC 워크플로우, 그리고 거버넌스 서비스가 적용된 공유 액세스 권한이 필요합니다.
Red Hat OpenShift, Red Hat AI, NVIDIA, 그리고 Slinky 오퍼레이터가 결합되어 이러한 플랫폼을 제공할 수 있습니다.
리소스
엔터프라이즈를 위한 AI 시작하기: 입문자용 가이드
저자 소개

I build real-world GenAI solutions for organizations that can’t afford to get it wrong.
My career spans national security, enterprise software, and next-generation AI platforms, with more than a decade focused on solving complex problems at the intersection of data, intelligence, and technology. I began in the intelligence community, serving eight years with the NSA and across the IC in intrusion defense, intelligence analysis, and mission-critical cyber operations. That experience in high-stakes security, pattern recognition, and adversarial thinking continues to shape how I approach GenAI strategy and deployment today.
Since then, I’ve led product and platform initiatives in digital ecosystems, advised startups, and worked across the data science landscape helping organizations move from experimentation to production. Much of my work focuses on making generative AI models more knowledgeable and reliable by grounding them in domain-specific data, mission context, and real operational constraints across national security, research, and healthcare.
Today, as an AI Solutions Advisor at Red Hat and IBM, I partner with government agencies, research institutions, and enterprises across North America to design scalable GenAI systems that work in the real world. The goal is never novelty — it’s better decisions, faster execution, and durable advantage.

O'Neill Joseph is a Sr AI Solutions Architect in Red Hat focused on specialized AI deployments, has over 20 experience in IT Infrastructure, from telecommunications to cloud native infrastructure with a Degree in Cybersecurity and IT Networking from University of Maryland.

Working with customers to build IT solutions for over 25 years, Wes has experience integrating various technologies and approaches to produce outcomes and achieve mission objectives. Serving highly regulated industries such as healthcare and defense, Wes understands how to approach IT challenges with a secure, compliant end state in mind.
At Red Hat, Wes focuses on helping customers build cloud-native platforms where they can run AI/ML workloads, integrate heterogeneous data and facilitate outcomes anywhere in the world.
Prior to joining Red Hat, Wes was the CTO at a small technology company in DC helping build solutions for a variety of government customers.
Wes has managed global engineering teams, built services to help customers scale their missions, and designed software solutions to meet the needs of growing organizations.
유사한 검색 결과
과거의 운영 방식에서 벗어나 IT의 미래 구축
모델이 아니라 애플리케이션이 수익을 창출합니다.
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래