
Open source AI is more exciting than ever, offering a growing number of AI models to choose from. There are reasoning-heavy architecture options like DeepSeek and Kimi K2, more versatile options like the highly-adopted Qwen family, and the specialized, edge-ready Granite 4 from IBM. Having this many options is great news, but it can make users feel paralysis by analysis when trying to decide which model fits their project best.
For many organizations, the challenge is no longer finding an open source model, but identifying which will perform best given their specific constraints, whether that is maximizing reasoning for agentic workflows or minimizing latency for customer-facing chatbots.
This is where the OpenShift AI model catalog comes in. Rather than leaving teams to manually retrieve model sources and conflicting performance data, the catalog collects the world’s leading open source models into a single library. It provides a unified platform to discover and serve models with a few clicks, and a quick way to compare models based on trusted industry benchmarks. Let's take a closer look!

Find the model you need from our collection of open source models.
Screenshot of the Catalog page in Red Hat OpenShift AI. On the left, there is a panel to filter models by their intended task, and provider. On the right, there is a search bar and cards representing each model by their name.
In the catalog, users can filter models by use case like code generation or speech recognition. They can also directly toggle the performance view to see benchmark data. The main dashboard organizes the models by name and version, followed by its number of parameters and quantization, if there is any. You will also find the quantized versions of some models in the catalog. These are large language models (LLMs) that have been optimized for speed and efficiency using the open source tool, LLMCompressor.
These models are packaged following the Open Container Initiative (OCI) standard into portable container images hosted in Red Hat's registry. This format allows organizations to manage models with the same level of governance, versioning, and automation as traditional enterprise microservices.
When a model is selected, users can then view technical information like the model architecture, its licensing, and the performance results on HuggingFace OpenLLM V1 and V2 text-based tasks using lm_evaluation_harness. Models that have been validated by Red Hat also show the OpenShift AI versions in which they have been tested.
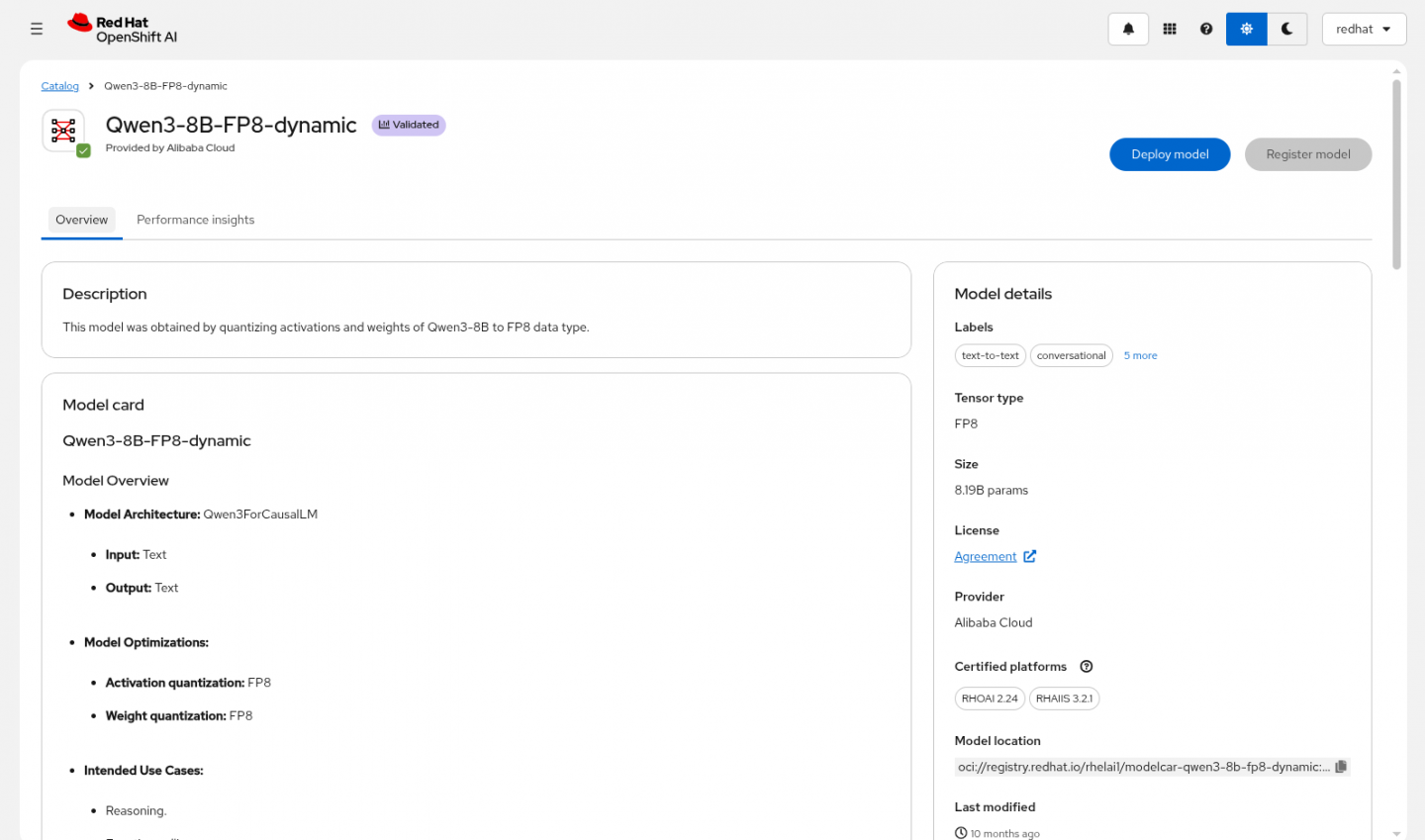
Find clear information about the model's origin and intended use cases.
Screenshot of the overview tab of the model page in Red Hat OpenShift AI, for the model Qwen3-8B-FP8-dynamic. On the top, there is the model name and buttons to deploy and register a model. On the left, there is information about the model card: architecture, optimization and intended use cases. On the right, there are other details like the tensor type, size, license, provider, certified platforms and model location.
One of the primary values of the catalog are the performance insights it provides. These are the results obtained by Red Hat teams running the model through several scenarios, such as a chatbot, retrieval-augmented generation (RAG), and as a coding assistant. The hardware used to test these models includes NVIDIA GPUs—like A100, B200, H100, H200 and L4—while using vLLM.
You can see how long it took each model to start responding to the user prompt with time-to-first-token (TTFT), and also how quickly the model generated a response with tokens-per-second (TPS). These metrics are fundamental to understanding the performance of the model, which has a direct impact on user experience.
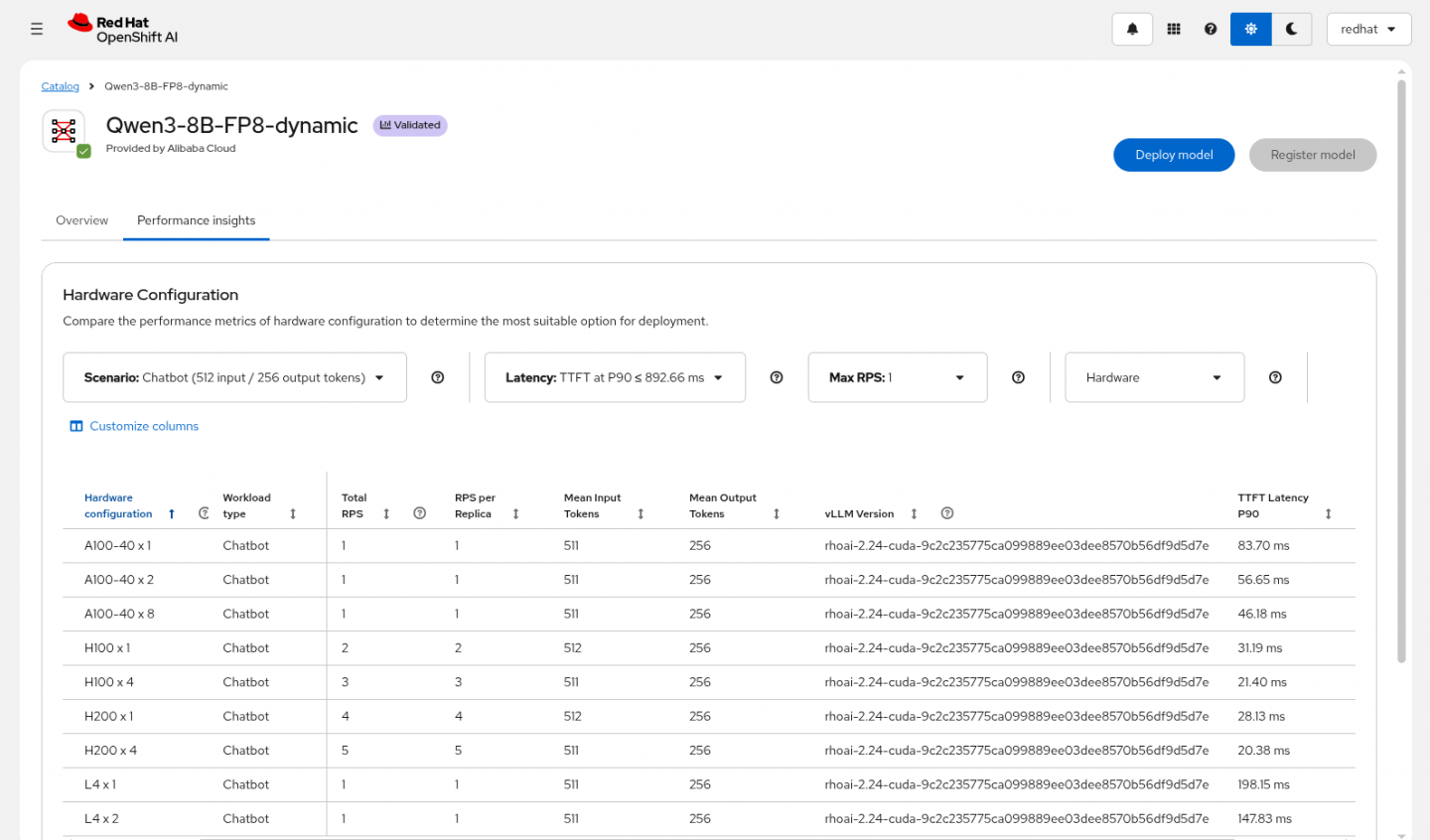
Performance insights curated by Red Hat model validation teams.
Screenshot of the performance insights tab of the model page in Red Hat OpenShift AI, for the model Qwen3-8B-FP8-dynamic. There is a table describing the TTFT latency depending on different hardware configurations by GPU, use case and vLLM version. On the top, there are filtering options like the use case, latency, max RPS and hardware.
Once a model is selected, your team can quickly deploy the model by providing some project details and clicking a button. And as simple as that, the model is ready to use! This eliminates manual environment setup, helping teams pivot quickly from model evaluation to AI application development.
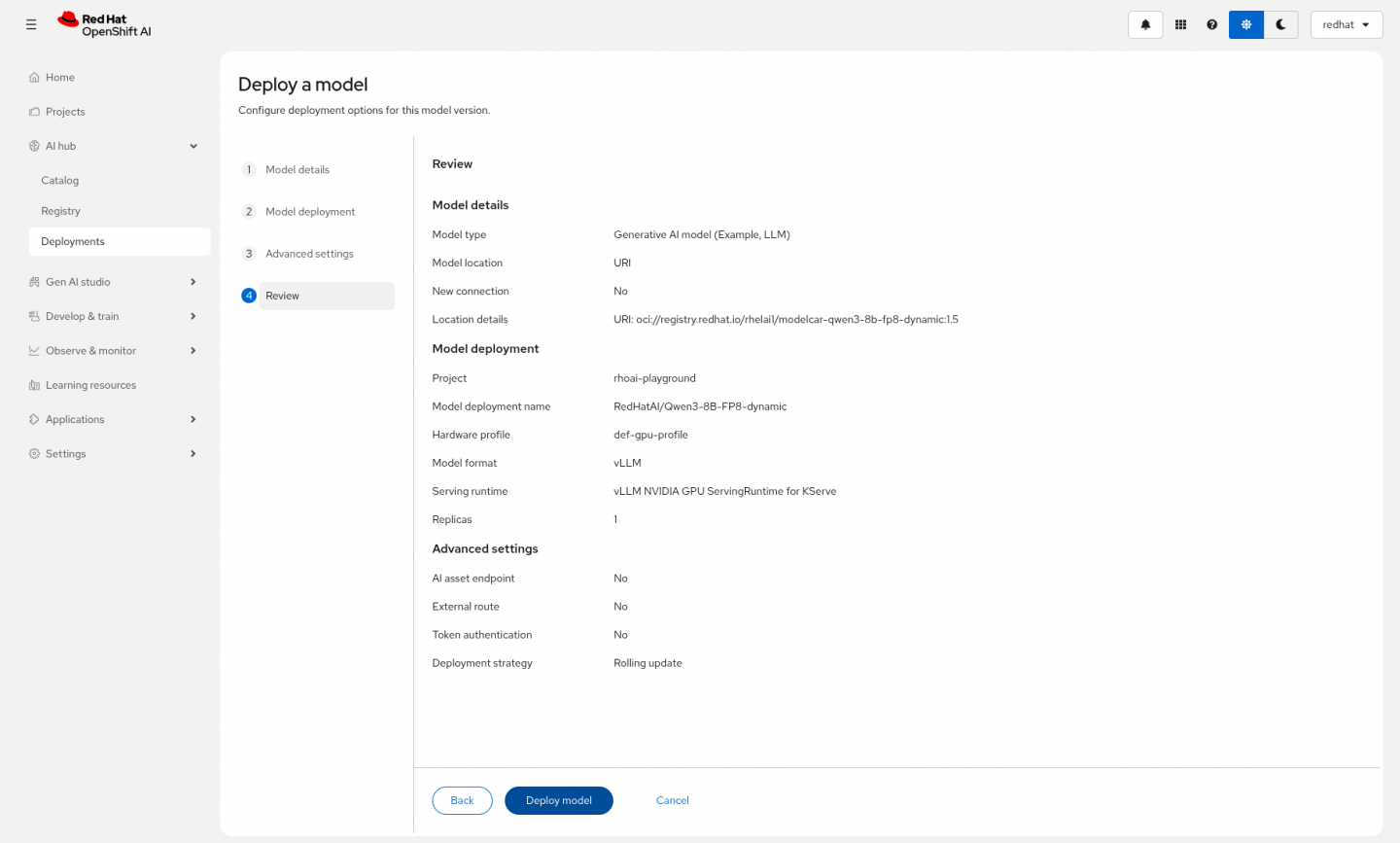
The model can be deployed easily into the OpenShift AI cluster.
Screenshot of the deploy a model page in Red Hat OpenShift AI. It shows a review of the answers provided to the form to deploy a model including model name, model location, project, serving runtime, token authentication and deployment strategy. On the bottom, there are buttons to go back and edit the answers, deploy the model or cancel.
Learn more
리소스
엔터프라이즈 조직을 위한 AI 시작하기: 입문자를 위한 가이드
저자 소개
Diego is a Specialist Solution Architect for OpenShift. He helps organizations navigate their digital transformation journeys by tailoring cloud-native solutions that align with their business objectives.
With a background spanning AI and application development, Diego brings a hands-on perspective to the adoption of AI solutions. He is passionate about the evolution of Agentic AI and focuses on helping enterprises simplify complex architectural challenges. By bridging the gap between innovative ideas and enterprise-grade execution, he helps customers gain a competitive edge through production-ready AI solutions.
유사한 검색 결과
빠르게 진화하는 AI 위협, 더 빠른 대응
AI 전환점 디지털 주권 확보가 더 이상 선택이 아닌 이유
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래