생성형 AI와 에이전틱 AI가 대중화됨에 따라 AI 도입과 개발이 가속화되고 있습니다. 새로운 시장이 등장하면서 많은 기업이 AI를 통해 실질적인 투자 수익(ROI)을 얻는 데 어려움을 겪고 있습니다. GPU가 인프라를 장악하고 있지만, 수요 증가로 인한 비용 상승과 가용성 감소로 인해 기업들은 성능 요구 사항과 고객 만족도 기준을 충족하는 대안을 모색하고 있습니다.
한편, AI 개발자와 엔지니어는 복잡하고 시간이 많이 소요되는 인프라 설정과 검색 증강 생성(RAG)을 통해 최적의 LLM(대규모 언어 모델) 추론을 위한 소프트웨어 스택 및 아키텍처 구축의 어려움에 직면해 있습니다. AI를 쉽게 사용할 수 있는지, 독점 데이터가 안전한지, AI 구축을 어떻게 시작해야 하는지와 같은 기술적인 문제로 인해 개발자가 AI를 시작하지 못할 수도 있습니다.
Intel과 Red Hat의 협업은 Xeon CPU의 성능과 Red Hat OpenShift AI의 확장성을 결합하여 기업에서 에이전틱 AI를 배포하기 위한 안전하고 유연한 기반을 제공합니다. 고객은 이 플랫폼에서 하이브리드 클라우드 환경 전반에 걸쳐 AI 및 머신 러닝 모델과 애플리케이션을 더욱 안전하게 구축할 수 있습니다.
Intel은 도입 프로세스를 간소화하기 위해 다양한 AI 퀵스타트를 개발했습니다. AI 퀵스타트는 OpenShift를 통해 Xeon에 빠르게 배포할 수 있는 실제 비즈니스 활용 사례의 예시로, 개발 및 출시 기간을 단축합니다. 이러한 퀵스타트는 AI 퀵스타트 카탈로그에서 확인할 수 있습니다.
Xeon에서 AI를 사용해야 하는 이유
GPU가 딥러닝, 생성형 AI, 에이전틱 AI 분야를 주도하고 있지만, 추론의 경우 더 작고 비용 효율적인 컴퓨팅 플랫폼으로도 기능 및 성능 요구 사항을 충족할 수 있습니다. CPU는 기존에 데이터 처리, 데이터 분석, 클래식 머신 러닝을 위한 플랫폼으로 널리 사용되었습니다. 여기에는 서포트 벡터 머신(SVM), XGBoost, K-평균과 같은 방법을 사용한 회귀, 분류, 클러스터링, 의사 결정 트리가 포함됩니다. 활용 사례로는 금융 및 소매업 예측, 사기 탐지, 공급망 최적화 등이 있습니다. 이를 통해 장기적인 AI 인프라 비용을 관리할 수 있습니다. Intel Xeon은 이러한 소규모 플랫폼을 위한 헤드 노드로서 적합합니다.
Intel Xeon의 하드웨어 기능
Xeon을 AI에 적합한 CPU 플랫폼으로 만드는 차별화 요소는 바로 하드웨어 기능입니다. 명령어 세트인 AMX(Advanced Matrix Extensions)와 MRDIMM(Multiplexed Rank Dual In-line Memory Module)을 통한 높은 메모리 대역폭은 Xeon을 돋보이게 하는 가장 중요한 요소입니다.
AMX는 4세대 Intel® Xeon® Scalable Processors에 빌트인 AI 가속기로 도입되었으며, 이 코어의 전용 하드웨어 블록은 별도의 가속기에 의존하지 않고 행렬 연산을 수행합니다. 여기에는 Bfloat16(BF16) 및 INT8과 같은 저정밀 데이터 유형에 대한 지원이 포함됩니다. BF16의 주요 이점은 FP32와 비교했을 때 정확도 저하 없이 성능을 향상할 수 있다는 점입니다. AMX를 통해 가속화하면 전력 및 리소스 사용률이 줄어들고, PyTorch 및 TensorFlow를 포함한 AI 프레임워크로 최적화를 업스트림하여 개발 시간을 단축할 수 있습니다.
추천 시스템, 자연어 처리, 생성형 AI, 에이전틱 AI, 컴퓨터 비전과 같은 활용 사례는 모두 AMX를 통해 최종 사용자와 비즈니스 가치를 높일 수 있습니다.

그림 1: Intel® AMX는 TMUL 타일 행렬 곱 연산을 지원하는 2D 레지스터 타일을 제공하여, 한 번의 연산으로 대규모 행렬을 계산할 수 있습니다.
AI 및 LLM 추론에서 메모리 병목 현상은 높은 메모리 수요로 인한 키-값(KV) 캐싱에서 발생합니다. MRDIMM은 계산 복잡도를 제곱(quadratic)에서 선형(linear)으로 전환하여 RDIMM보다 37% 이상 높은 메모리 대역폭을 제공합니다. 이를 통해 AI 추론 중 데이터 집약적 작업 처리 시 메모리 처리량을 개선하고 지연(latency)을 줄일 수 있습니다. GPU 메모리가 제한된 시스템에서 Xeon CPU는 KV 데이터를 오프로드하여 고성능을 유지하면서 고가의 GPU 리소스를 확보할 수 있습니다.
Xeon은 AI 분야에서 다양한 실용 사례가 있습니다. 추론(inference), RAG, 안전한 데이터 처리, 에이전트형 AI(Agentic AI) 등입니다. 기능적이면서도 높은 성능을 제공하는 Xeon은 GPU 없이도 AI 요구 사항을 충족할 수 있는 지원 소프트웨어를 갖춘 플랫폼입니다.
Xeon 활용 사례 1: AI 추론
LLM 추론은 엔터프라이즈 챗봇, 문서 요약, 코드 어시스턴트, RAG 파이프라인과 같은 애플리케이션을 구동합니다. 대규모 GPU 투자 없이 비용 효율적인 생성형 AI를 구축하려는 중견 기업 및 조직에게 Xeon은 더욱 실용적인 선택지가 될 수 있습니다. Xeon은 작거나 중간 규모의 LLM과 최대 130억(13B) 파라미터의 Mixture-of-Experts(MOE) 모델에서 최적 성능을 발휘하며, 첫 토큰 생성 시간(TTFT) 3초, 토큰당 처리 시간 100ms와 같은 기준도 충족합니다.
Intel은 vLLM 및 SGLang을 포함한 AI 추론을 최적화하기 위해 오픈소스 커뮤니티와 긴밀하게 협력해 왔습니다. vLLM은 높은 처리량과 메모리 효율성을 제공하는 추론 서비스 엔진입니다. Pytorch.org의 Xeon용 vLLM 대시보드에는 Xeon 기반 Llama-3.1-8B-Instruct를 포함하여 널리 사용되는 LLM의 성능 수치가 게시되어 있습니다. Intel은 지속적으로 성능을 개선하고 검증된 모델 목록에 대한 지원을 추가하고 있습니다. SGLang은 Intel이 Xeon과 통합하기 위해 노력하고 있는 또 다른 고속 서비스 프레임워크입니다.
또한 Xeon은 llm-d를 활용한 분산 LLM 추론도 지원합니다. 이 방식에서는 prefill 단계와 decode 단계가 여러 노드에 분산되어 확장성을 높입니다. llm-d는 Kubernetes 네이티브의 오픈소스 프레임워크로, 대규모 분산 LLM 추론을 가속화합니다.
Xeon 활용 사례 2: RAG 및 안전한 데이터 처리
RAG는 모델을 재학습시키지 않고도 LLM에서 정확한 결과를 얻는 데 효과적입니다. 지식 기반은 문서 파싱(document parsing), 청킹(chunking), 메타데이터 추출을 통해 데이터를 준비하고 임베딩을 생성한 뒤, 이를 벡터 데이터베이스에 저장하여 만들어집니다. Intel® Trust Domain Extensions(TDX)라는 하드웨어 기반의 기밀 컴퓨팅 기술을 통해 모든 작업을 안전하게 수행할 수 있습니다. TDX는 하드웨어로 격리된 VM(가상 머신)을 사용하여 무단 액세스로부터 데이터와 애플리케이션을 보호합니다. 이를 통해 기업은 고객 지원 자동화, 문서 검색, 법률 연구를 위해 사용 가능한 독점 데이터를 신속하게 활용할 수 있습니다. Xeon을 사용하면 검색 지연 시간이 짧고 동시에 여러 쿼리를 처리할 수 있습니다.

그림 2: Intel® TDX는 하드웨어 확장을 사용하여 메모리를 관리 및 암호화함으로써 데이터의 기밀성과 무결성을 보호합니다.
Xeon 활용 사례 3: 에이전틱 AI
AI 에이전트는 계획(planning), 실행(acting), 관찰(observing), 반성(reflecting)의 순차적 로직을 따릅니다. AI 에이전트는 데이터베이스 쿼리, API 호출, 파일 액세스와 같은 LLM 추론 및 도구 실행과 관련된 혼합 워크로드를 사용합니다. Xeon은 MCP(Model Context Protocol) 서버, LlamaStack 에이전트 API, LangChain 및 CrewAI 프레임워크를 지원합니다. IT 운영 자동화, 재무 의사 결정 지원 및 공급망 에이전트가 주요 비즈니스 활용 사례입니다.
OpenShift 기반 Xeon: 새로운 기능
Red Hat OpenShift AI는 하이브리드 클라우드, 온프레미스 및 엣지 환경에서 AI 모델과 애플리케이션을 대규모로 구축, 학습 및 배포하는 전체 라이프사이클을 관리하기 위한 엔터프라이즈급 AI 플랫폼입니다. OpenShift AI에 포함된 기술 중 하나인 vLLM은 최적화된 고처리량 및 저지연 모델 서비스를 제공하면서 하드웨어 비용을 절감합니다. 개발 팀은 최적화되고 프로덕션 환경에 즉시 배포할 수 있는 검증된 타사 모델 컬렉션을 통해 모델 접근성과 가시성을 더욱 강력하게 제어하여 보안 및 정책 요구 사항을 충족할 수 있습니다. 이 모든 것을 고급 툴링을 통해 자동으로 배포하여 AI 프로젝트를 빠르게 시작하고 운영 복잡성을 줄일 수 있습니다. 전반적으로 AI 애플리케이션을 프로덕션 환경에 훨씬 더 빠르게 배포할 수 있습니다.
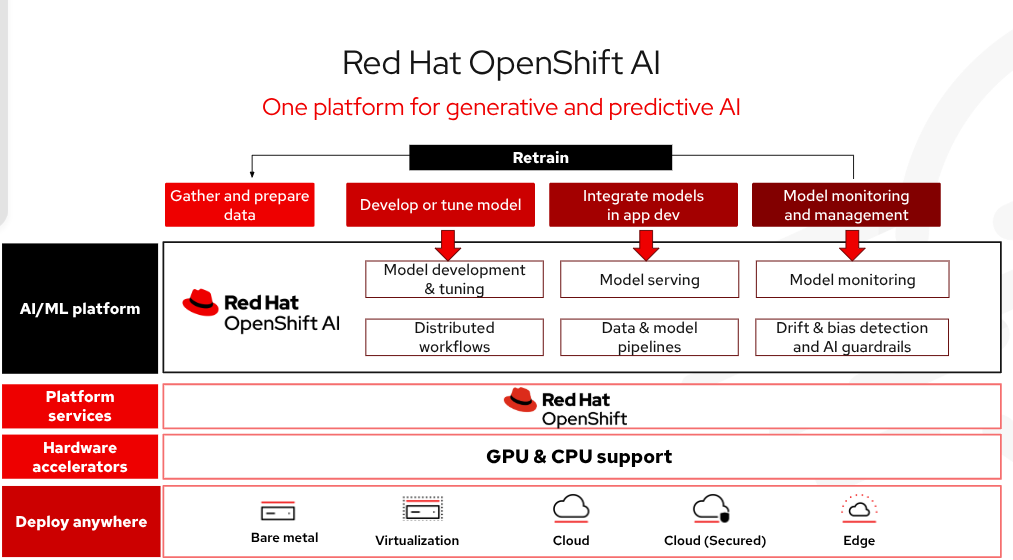
그림 3: Red Hat OpenShift AI는 기업이 하이브리드 클라우드 환경 전반에서 AI 기반 애플리케이션을 대규모로 생성하고 제공할 수 있도록 지원하는 유연하고 확장 가능한 AI(인공 지능) 및 ML(머신 러닝) 플랫폼입니다.
기능
AI 인프라 관리에 소요되는 시간을 단축하여 MaaS(Models-as-a-Service)를 통해 고성능 모델을 쉽게 배포하고 API 엔드포인트를 통해 액세스할 수 있습니다. 베어 메탈, 가상 환경 또는 주요 퍼블릭 클라우드 플랫폼에서 안전하고 유연한 자체 관리형 소프트웨어를 통해 하이브리드 클라우드 전반에서 유연성을 확보할 수 있습니다. Red Hat은 개발자가 쉽게 사용할 수 있도록 일반적인 오픈소스 AI/ML 툴링 및 모델 서비스를 테스트하고 통합했습니다. OpenShift AI에는 대규모 분산 AI 추론을 위한 오픈 소스 프레임워크인 llm-d도 포함되어 있습니다.
vLLM CPU 이미지
Intel은 Red Hat Universal Base Image를 기반으로 구축된 Dockerhub의 CPU용 vLLM 이미지를 제공합니다. 이 이미지는 AMX를 활성화한 상태로 빌드됩니다. 따라서 이 이미지를 실행하려면 4세대 Xeon® Scalable® 프로세서 이상이 필요합니다. 이제 바로 사용 가능한 많은 오픈 소스 모델을 신속하게 배포하고 높은 처리량과 짧은 지연 시간으로 추론을 실행할 수 있습니다.
AI 퀵스타트
redhat.com의 AI 퀵스타트 카탈로그에서 OpenShift AI 기반의 Xeon에서 vLLM을 통해 모델을 최적으로 실행하는 즉시 사용 가능한 비즈니스 활용 사례를 찾아볼 수 있습니다. 개발자는 이러한 예제를 시작점으로 삼아 필요에 따라 사용자 정의하거나 있는 그대로 사용할 수 있습니다. 여러 AI 퀵스타트의 초기 초안 버전은 GitHub에서 사용할 수 있으며 Xeon에서 즉시 실행할 수 있습니다. 모든 최종 퀵스타트는 AI 퀵스타트 카탈로그를 통해 릴리스됩니다.
- LlamaStack MCP 서버 – 날씨 리포트, 인사(HR) 툴 등 MCP 서버와 함께 vLLM으로 LLM 배포
- LLM CPU Serving – 소규모 언어 모델을 제공하는 경량 AI 리더십 및 전략 채팅 어시스턴트
- RAG – 검색 증강 생성(Retrieval-Augmented Generation)을 활용하여 LLM을 전문 데이터 소스로 강화, 보다 정확하고 문맥을 이해한 응답 제공
- vLLM 툴 호출(Tool Calling) – 함수 호출(function calling) 기능과 함께 vLLM을 사용하여 LLM 배포
다음 단계
Red Hat OpenShift AI를 사용하면 Xeon에서 AI를 쉽게 사용할 수 있습니다. 보호되고 관리되는 환경은 개발, 배포 및 관찰에 필요한 AI 인프라를 설정합니다.
- Xeon용 vLLM 대시보드에서 성능 수치를 확인하고, vLLM 도큐멘테이션에서 AMX 지원을 통해 CPU용 vLLM 이미지를 빌드/다운로드하는 방법을 알아보세요.
- DockerHub에서 Red Hat Universal Base Image를 기반으로 하는 CPU용 vLLM을 사용하세요.
- Xeon용 지원되는 모델 목록을 검토하세요.
- AI 퀵스타트 카탈로그에서 바로 실행할 수 있는 예제를 살펴보고, AI 퀵스타트 Github에서 아직 개발 중인 AI 퀵스타트를 확인하세요.
- Red Hat OpenShift AI 사이트를 방문하세요.
저자 소개

유사한 검색 결과
Red Hat OpenShift sandboxed containers 1.12 and Red Hat build of Trustee 1.1 bring confidential computing to bare metal and AI workloads
AI for scientific research: Building the research platform that science needs with Red Hat AI
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래