

InstructLab은 합성 데이터 생성을 통해 대규모 언어 모델(LLM)에 기여하고 이를 개선하는 프로세스를 간소화하기 위해 설계된 커뮤니티 기반 프로젝트입니다. 이 이니셔티브는 LLM에 기여하는 것의 복잡성, 분기된 모델로 인한 모델 확산 문제, 직접적인 커뮤니티 거버넌스의 부재 등 개발자가 직면한 다양한 과제를 해결합니다. Red Hat과 IBM Research가 지원하는 InstructLab은 새로운 합성 데이터 기반 정렬 튜닝 방법을 활용하여 모델 성능과 접근성을 개선합니다. 여기에서는 현재 문제와 기존 방식으로 모델을 미세 조정(fine-tuning)할 때 직면하게 되는 기술적 과제, 그리고 이러한 문제를 해결하기 위해 InstructLab이 취하는 접근 방식에 대해 설명합니다.
도전 과제: 낮은 품질의 데이터와 컴퓨팅 리소스의 비효율적인 사용
LLM 분야의 경쟁이 치열해짐에 따라, 여러 기업은 인터넷에 공개된 방대한 정보를 기반으로 학습한 모델을 대규모로 구축하는 방식을 시도하고 있습니다. 그러나 인터넷의 상당 부분에는 모델의 핵심 기능에 필요 없는 중복 정보 또는 비자연어 데이터가 포함되어 있습니다.
예를 들어, 이후 버전 구축의 기반이 되는 LLM GPT-3를 학습시키는 데 사용되는 토큰의 80%는 엄청난 양의 웹 페이지를 포함하는 Common Crawl에서 비롯됩니다. 이 데이터세트에는 고품질 텍스트, 저품질 텍스트, 스크립트 및 기타 비자연어 데이터가 혼합되어 있습니다. 데이터의 상당 부분이 유용하지 않거나 품질이 낮은 콘텐츠일 것으로 예상됩니다. (Common Crawl 분석)
이처럼 방대한 양의 큐레이션되지 않은 데이터로 인해 컴퓨팅 리소스가 비효율적으로 사용되는 것은 높은 학습 비용으로 이어지며 결국 이러한 모델의 소비자 비용이 증가할 뿐만 아니라 로컬 환경에서 이러한 모델을 구현하는 데 문제가 발생합니다.
지금까지의 추세로 보아 매개변수 수가 더 적은 모델이 늘어나고 있으며, 이러한 모델에서는 데이터의 품질과 관련성이 단순히 데이터의 양보다 더 중요하게 고려됩니다. 더 정확하고 의도적인 데이터 큐레이션 능력을 갖춘 모델은 더 나은 성능을 발휘하고 더 적은 컴퓨팅 리소스를 사용하며 더 높은 품질의 결과를 제공할 수 있습니다.
InstructLab의 솔루션: 합성 데이터 생성 개선
InstructLab만의 고유한 장점은 매우 적은 시드 데이터세트로 시작하여 학습에 사용할 대량의 데이터를 생성할 수 있는 기능입니다. 이는 사람이 생성한 데이터와 컴퓨팅 오버헤드를 최소한으로 사용하면서 LLM을 개선하는 챗봇을 위한 대규모 조정(Large-scale Alignment for chatBots, LAB) 방법론을 활용합니다. 또한, 개인이 관련성 있는 데이터를 제공할 수 있는 사용자 친화적인 방법을 제공하며, 생성 프로세스 중에 도움을 주는 모델과 함께 합성 데이터 생성을 통해 개선됩니다.

InstructLab 접근 방식의 주요 특징:
분류 체계 기반의 데이터 큐레이션
가장 먼저 다양한 기술과 지식 영역을 구성하는 계층 구조인 분류 체계를 생성하는 것으로 시작됩니다. 이 분류 체계는 사람이 생성한 초기 예시를 선별하기 위한 로드맵 역할을 하며, 이러한 예시는 합성 데이터 생성 프로세스의 시드 데이터로 사용됩니다. 이 데이터는 모델의 기존 지식을 간단히 탐색하고 기여할 수 있는 격차를 찾기 쉬운 구조로 구성되어 중복된 비정형 정보를 줄입니다. 동시에, 손쉽게 작성할 수 있는 YAML 파일을 질문-답변 페어 포맷으로 사용하여 모델을 특정 사용 사례나 요구 사항에 맞게 적용할 수 있습니다.

합성 데이터 생성 프로세스
InstructLab은 기반 시드 데이터에서 교사 모델(teacher model)을 활용하여 데이터 생성 프로세스 중에 새로운 예시를 생성합니다. 주목해야 할 중요한 점은 이 프로세스는 교사 모델에 의해 저장된 지식을 사용하는 것이 아니라, 데이터세트를 대폭 확장하는 특정 프롬프트 템플릿을 사용하는 동시에 새로운 예시가 사람이 큐레이션한 원래 데이터의 구조와 의도를 유지하도록 한다는 것입니다. LAB 방법론에서는 두 가지 특정 합성 데이터 생성기를 사용합니다.
- 기술 합성 데이터 생성기(Skills-SDG): 지시 생성, 평가, 응답 생성, 최종 페어(pair) 평가에 프롬프트 템플릿을 사용합니다.
- 지식 SDG: 외부 지식 소스를 사용하여 생성된 데이터를 기반으로 교사 모델에서 다루지 않는 도메인에 대한 지시 데이터를 생성합니다.
이는 수동으로 주석이 추가된 대량의 데이터를 사용할 필요성을 크게 줄여줍니다. 사람이 생성한 작고 고유한 예시를 참조로 사용하면 수백, 수천 또는 수백만 개의 질문-답변 쌍을 큐레이션하여 모델의 가중치와 편향에 영향을 줄 수 있습니다.
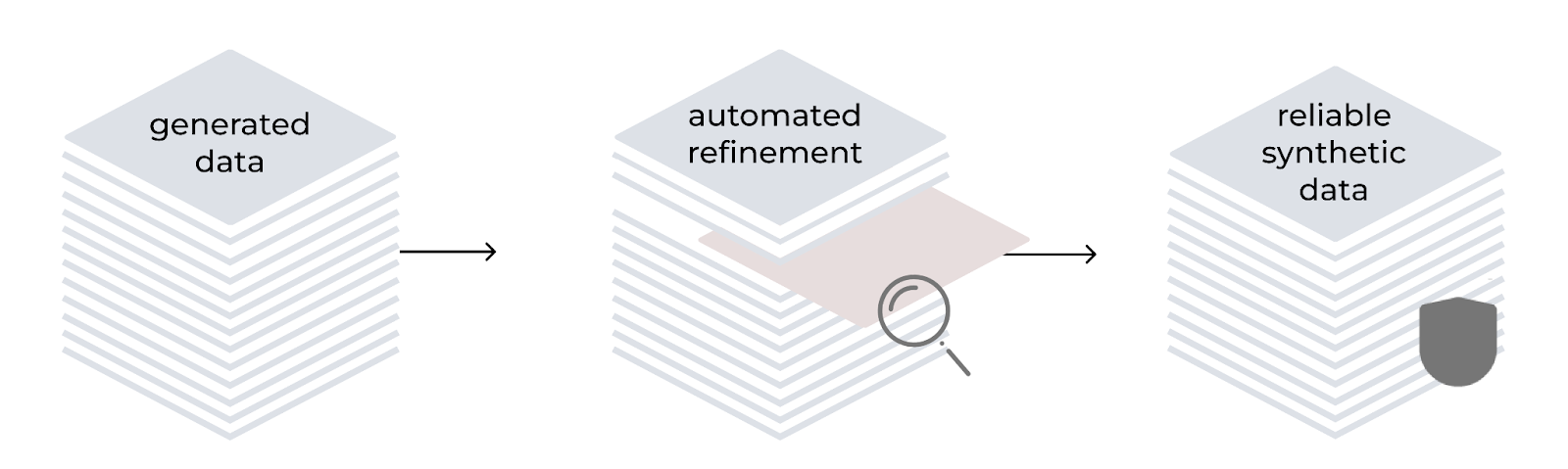
자동 개선
LAB 방법은 자동화된 개선 프로세스를 통합하여 합성으로 생성된 학습 데이터의 품질과 신뢰성을 높입니다. 계층적 분류 체계에 따라 모델을 생성기와 평가자로 사용합니다. 이 프로세스에는 지시 생성, 콘텐츠 필터링, 응답 생성, 3점 평가 시스템을 사용한 페어 평가가 포함됩니다. 지식 기반 태스크의 경우 생성된 콘텐츠는 신뢰할 수 있는 소스 문서를 기반으로 하여 특수 도메인에서 발생할 수 있는 부정확성을 해결합니다.
다단계 튜닝 프레임워크
InstructLab은 모델의 성능을 점진적으로 개선하기 위해 다단계 학습 프로세스를 구현합니다. 이러한 단계별 접근 방식으로 학습의 안정성을 유지할 수 있으며, 데이터의 재생 버퍼는 치명적인 망각을 방지하여 모델이 지속적으로 학습하고 개선할 수 있도록 합니다. 생성된 합성 데이터는 2단계 튜닝 프로세스에서 활용됩니다.
- 지식 튜닝: 새로운 사실 정보를 통합합니다. 먼저 짧은 답변을 기반으로 학습한 다음 긴 답변과 기본적인 기술을 바탕으로 학습합니다.
- 기술 튜닝: 구성 기술에 초점을 맞춰 다양한 태스크와 컨텍스트 전반에 지식을 적용하는 모델의 능력을 향상합니다.

프레임워크는 안정성을 위해 작은 학습량, 긴 워밍업 기간, 큰 유효 배치 크기를 사용합니다.
반복적인 개선 주기
합성 데이터 생성 프로세스는 반복되도록 설계되었습니다. 분류 체계에 대한 새로운 기여가 이루어지면 추가 합성 데이터를 생성하는 데 사용될 수 있으므로 모델을 더욱 강화할 수 있습니다. 이러한 지속적인 개선 주기는 모델이 최신 상태를 유지하고 관련성을 유지하도록 하는 데 도움이 됩니다.
InstructLab의 결과와 의미
InstructLab은 상용 모델에 의존하는 대신 공개적으로 사용 가능한 교사 모델을 사용하여 최첨단 성능을 달성할 수 있는 능력에 그 의미가 있습니다. 벤치마크에서 InstructLab 방법론은 앞으로가 기대되는 결과를 보여주었습니다. 예를 들어, LAB 학습 모델이 Llama-2-13b(Labradorite-13b의 기본 모델) 및 Mistral-7B(Merlinite-7B의 기본 모델)에 적용되었을 때 MT-Bench 점수 측면에서 각 기본 모델을 기반으로 파인 튜닝된 기존 최고 모델을 능가하는 성능을 보여주었습니다. 또한 MMLU(멀티태스크 언어 이해 테스트), ARC(추론 능력 평가), HellaSwag(상식 추론 평가) 등 다른 메트릭에서도 강력한 성능을 유지했습니다.

커뮤니티 기반 협업 및 접근성
InstructLab의 중요한 장점 중 하나는 오픈소스라는 특성과 모델의 미래를 설계할 때 모두가 협력하는 방식으로 생성형 AI를 민주화한다는 목표입니다. 커맨드라인 인터페이스(Command Line Interface, CLI)는 개인용 노트북과 같은 일반적인 하드웨어에서 실행되도록 설계되어 개발자와 기여자의 진입 장벽을 낮춥니다. 또한 InstructLab 프로젝트는 멤버가 Hugging Face에서 정기적으로 빌드되고 릴리스되는 주요 모델에 새로운 지식이나 기술로 기여할 수 있도록 하여 커뮤니티 참여를 장려합니다. 여기에서 최신 모델을 확인해 보세요.

LAB 방법론을 기반으로 구축된 InstructLab의 합성 데이터 생성 프로세스는 생성형 AI 분야에서의 상당한 발전을 보여줍니다. InstructLab은 새로운 기능과 지식 도메인으로 LLM을 효율적으로 개선함으로써 AI 개발에 대한 더욱 협업적이고 효과적인 접근 방식을 위한 탄탄한 기반을 제공합니다. 프로젝트에 대해 자세히 알아보려면 instructlab.ai를 방문하거나 이 시작하기 가이드를 참고하여 직접 InstructLab을 시도해 보시기 바랍니다.
저자 소개
Cedric Clyburn (@cedricclyburn), Senior Developer Advocate at Red Hat, is an enthusiastic software technologist with a background in Kubernetes, DevOps, and container tools. He has experience speaking and organizing conferences including DevNexus, WeAreDevelopers, The Linux Foundation, KCD NYC, and more. Cedric loves all things open-source, and works to make developer's lives easier! Based out of New York.
Legare Kerrison is a Technical Marketing Manager and Developer Advocate working on Red Hat's Artificial Intelligence offerings. She is passionate about open source AI and making technical knowledge accessible to all. She is based out of Boston, MA.
유사한 검색 결과
자동화 그 이상의 가치: AI 기반 보안 취약점 급증에 따라 기술 전문가의 지원이 필요한 이유
Red Hat Enterprise Linux, 양자 컴퓨팅 시대를 대비한 SSH 보안 역량 강화
Technically Speaking | Defining sovereign AI with open source
Infrastructure At The Edge | Compiler
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래