
모든 대규모 언어 모델(Large Language Model, LLM)이 릴리스가 거듭될수록 그 규모가 커지고 있습니다. 따라서 모델을 학습시키기 위해 많은 수의 GPU를 사용해야 하고 이러한 모델의 라이프사이클 전반에서 미세 조정, 추론 등을 위해 더 많은 리소스가 필요합니다. 이러한 LLM에는 새로운 무어의 법칙이 적용됩니다. 즉, 모델 크기(매개 변수 수로 측정됨)가 4개월마다 두 배로 늘어납니다.
고비용을 초래하는 LLM
LLM을 학습시키고 운영하는 데에는 자원, 시간, 비용 측면에서 많은 비용이 듭니다. 자원 요구량은 LLM을 배포하는 기업에 직접적인 영향을 미치며, 기업이 자체 인프라를 사용하거나 대형 클라우드 제공업체를 활용하더라도 상황은 마찬가지입니다. 그리고 LLM의 크기는 점점 커지고 있습니다.
설상가상으로 LLM을 운영하려면 매우 많은 리소스가 필요합니다. Llama 3.1 LLM의 경우 매개 변수가 4,050억 개나 되며 추론에만 810GB의 메모리(FP16)가 필요합니다. Llama 3.1 모델 계열은 3,900만 GPU 시간의 GPU 클러스터에서 15조 개의 토큰을 기반으로 학습되었습니다. LLM 크기가 기하급수적으로 증가함에 따라 학습 및 운영을 위한 컴퓨팅 및 메모리 요구 사항 역시 증가하고 있습니다. Llama 3.1의 미세 조정에는 3.25TB의 메모리가 필요합니다.
작년에는 심각한 GPU 부족 사태가 발생했으며, 수급 격차가 개선됨과 동시에 곧바로 전력 문제가 다음 장애물로 떠올랐습니다. 더 많은 데이터센터가 가동을 시작하고 각 데이터센터의 전력 소비량이 거의 150MW로 두 배나 증가한 것을 보면 이 문제가 AI 산업에 걸림돌이 되는 이유를 쉽게 이해할 수 있습니다.
LLM 관련 비용을 절감하는 방법
LLM 관련 비용을 절감하는 방법을 논의하기 전에, 먼저 모두가 잘 아는 예를 들어보겠습니다. 카메라 성능은 끊임없이 개선되고 있으며, 새로운 모델은 그 어느 때보다 더 높은 해상도로 사진을 촬영할 수 있습니다. 그러나 개별 원본 이미지 파일의 크기가 40MB 또는 그 이상이라면 너무 크죠. 직업 특성상 이러한 이미지를 사용해야 하는 미디어 전문가를 제외한 대부분의 사람들은 파일 크기를 80% 줄인 JPEG 버전의 이미지에 만족합니다. 물론 JPEG로 압축하는 방식을 사용하면 RAW 원본 이미지보다 품질이 낮아지지만 대부분의 경우 JPEG를 사용하는 것만으로 충분합니다. 또한 일반적으로 원본 이미지를 처리하고 보려면 특별한 애플리케이션을 사용해야 합니다. 따라서 원본 이미지를 처리할 때 드는 컴퓨팅 비용은 JPEG 이미지에 비해 더 높습니다.
이제 다시 LLM에 대한 이야기로 돌아가겠습니다. 모델 크기는 매개 변수 수에 따라 다르므로, 비용을 절감할 수 있는 한 가지 방법은 매개 변수 수가 적은 모델을 사용하는 것입니다. 널리 사용되는 모든 오픈소스 모델에는 다양한 매개 변수가 포함되어 있으므로 특정 애플리케이션에 가장 적합한 매개 변수를 선택할 수 있습니다.

그러나 대부분의 벤치마크에서 일반적으로 매개 변수 수가 많은 LLM이 매개 변수 수가 적은 LLM보다 성능이 더 우수한 것으로 확인됩니다. 필요한 리소스를 줄이기 위해서는 더 큰 매개 변수 모델을 사용하되 더 작은 크기로 압축하는 것이 더 효과적일 수 있습니다. 테스트 결과, GAN 압축은 계산량을 거의 20배 줄일 수 있는 것으로 나타났습니다.
LLM을 압축하는 방법에는 양자화(quantization), 가지치기(pruning), 큰 모델 지식을 작은 모델로 옮기기(knowledge distillation), 층 수 줄이기(layer reduction) 등 여러 가지가 있습니다.
양자화(Quantization)
양자화는 모델의 숫자 값을 32비트 부동 소수점 형식에서 정밀도가 낮은 데이터 유형(16비트 부동 소수점, 8비트 정수, 4비트 정수 또는 2비트 정수)으로 변경합니다. 데이터 유형의 정밀도를 낮추면 모델이 작업 중에 필요로 하는 비트 수가 줄기 때문에 메모리와 계산량이 줄어듭니다. 양자화는 모델을 학습시킨 후 또는 학습 과정 중에 수행할 수 있습니다.
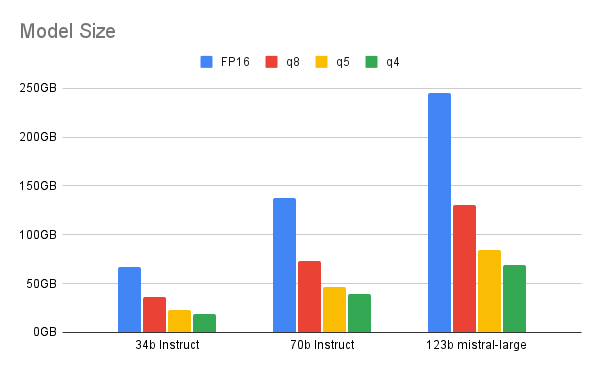
비트 수를 줄일수록 양자화와 성능 사이의 절충이 필요해집니다. 이 포스트는 4비트 양자화가 크기가 큰 모델(700억 개 이상의 매개 변수)에 제공하는 이상적인 범위를 중점적으로 다루고 있습니다. 비트 수가 낮을수록 양자화 전의 LLM과 양자화된 LLM 간에 현격한 성능 차이가 발생합니다. 소규모 모델의 경우 6비트 또는 8비트 양자화가 더 나은 선택일 수 있습니다.
양자화는 바로 이 LLM RAG 데모를 노트북에서 실행할 수 있는 이유입니다.
프루닝(Pruning)
프루닝은 덜 중요한 가중치 또는 뉴런을 제거하여 모델 크기를 줄이는 방식입니다. 이 경우 모델 크기를 줄이는 것과 정확성을 유지하는 것 사이에서 섬세한 균형 조정이 필요합니다. 프루닝은 모델 학습 전이나 중간 또는 이후에 수행할 수 있습니다. 이 아이디어를 한 단계 더 발전시킨 계층 프루닝은 전체 계층 블록을 제거합니다. 이 포스트에서 작성자는 성능 저하를 최소화하면서 최대 50%의 계층을 제거할 수 있다고 언급했습니다.
지식 증류(Knowledge distillation)
지식 증류는 대규모 모델(교사)의 지식을 소규모 모델(학생)로 이전하는 것을 의미합니다. 이 경우 소규모 모델은 더 큰 학습 데이터 대신 대규모 모델의 출력을 기반으로 학습합니다.
이 포스트는 Google의 BERT 모델을 DistilBERT로 증류하여 모델 크기를 40% 줄이고 추론 속도를 60% 높이는 동시에 언어 이해 능력은 97% 수준으로 유지한 방법을 소개합니다.
하이브리드 접근 방식
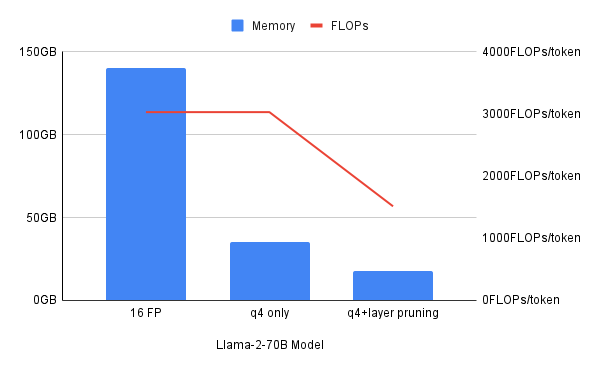
이러한 각 압축 기술은 개별적으로도 유용하지만 때로는 여러 기술을 함께 사용하는 하이브리드 접근 방식이 가장 적합할 수 있습니다. 이 포스트는 4비트 양자화가 필요한 메모리 양을 4배 줄이지만 FLOPS(초당 부동 소수점 연산 횟수)로 측정되는 계산 리소스 필요량을 줄이는 것에는 효과적이지 않다는 점에 주목합니다. 양자화와 계층 프루닝을 함께 사용하는 하이브리드 방식으로 필요한 메모리와 컴퓨팅 리소스를 둘 다 줄일 수 있습니다.
소규모 모델의 장점
소규모 모델을 사용하면 성능과 정확성을 높은 수준으로 유지하면서 컴퓨팅 요구 사항을 크게 줄일 수 있습니다.
- 컴퓨팅 비용 절감: 모델 크기가 작을수록 CPU 및 GPU 요구 사항이 낮아져 비용을 크게 절감할 수 있습니다. 고성능 GPU의 비용이 개당 30,000달러에 달할 수 있다는 점을 고려하면 컴퓨팅 비용을 줄일 수 있다는 것은 반가운 소식입니다.
- 메모리 사용 감소: 크기가 작은 모델은 큰 모델에 비해 더 적은 메모리를 사용합니다. 이는 IoT 기기 또는 휴대폰과 같이 리소스가 제한된 시스템에 모델을 배포하는 데 유용합니다.
- 추론 속도 향상: 소규모 모델은 빠르게 로드하고 실행할 수 있으므로 추론 대기 시간이 줄어듭니다. 빠른 추론 속도는 자율 주행 차량과 같은 실시간 애플리케이션에서 큰 차이를 가져올 수 있습니다
- 탄소 배출량 감소: 소규모 모델을 사용하여 컴퓨팅 요구 사항이 줄어들면 에너지 효율성을 개선하여 환경에 미치는 영향을 낮출 수 있습니다.
- 유연한 배포: 컴퓨팅 요구 사항이 줄어들어 필요한 위치에 모델을 유연하게 배포할 수 있습니다. 네트워크 엣지를 포함하여 사용자 요구 사항 또는 시스템 제약 조건의 동적인 변화에 맞춰 모델을 배포할 수 있습니다.
더 작고 저렴한 모델이 갈수록 많은 인기를 얻고 있습니다. 이는 ChatGPT-4o 미니(GPT-3.5 Turbo보다 60% 더 저렴한 모델)의 최신 릴리스와 SmolLM 및 Mistral NeMo의 오픈소스 혁신으로 증명됩니다.
- Hugging Face SmolLM: 1억 3,500만 개, 3억 6,000만 개, 17억 개의 매개 변수가 포함된 소규모 모델 제품군
- Mistral NeMo: NVIDIA와의 협업을 통해 구축된 120억 개의 매개 변수가 포함된 소규모 모델
이렇게 SLM(소규모 언어 모델)을 선호하는 추세는 위에서 설명한 장점에 기인합니다. 소규모 모델을 사용하는 경우 다양한 옵션 중에서 선택할 수 있습니다. 사전 구축된 모델을 사용하거나 압축 기술을 사용하여 기존 LLM의 크기를 줄일 수 있습니다. 소규모 모델을 선택할 때는 활용 사례에 따라 적합한 접근 방식을 결정해야 하므로 옵션을 신중하게 고려해야 합니다.
저자 소개
Ishu Verma is an AI Solution Architect at Red Hat dabbling in emerging technologies like AI Ops, AI safety and security. He, along with fellow open source hackers, works on building enterprise focused solutions with open source technologies. Prior to Red Hat, Ishu worked in technical marketing at Intel on IoT Gateways and building end-to-end IoT solutions with partners.
유사한 검색 결과
과거의 운영 방식에서 벗어나 IT의 미래 구축
추론에서 에이전트까지: Red Hat AI 3.4를 통해 기업의 AI 확장
Technically Speaking | Inside open source AI strategy
Technically Speaking | Build a production-ready AI toolbox
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래