
With the release of Red Hat OpenStack Services on OpenShift , there is a major change in the design and architecture that changes how OpenStack is deployed and managed. The OpenStack control plane has moved from traditional standalone containers on Red Hat Enterprise Linux (RHEL) to an advanced pod-based Kubernetes managed architecture.
Introducing Red Hat OpenStack Services on OpenShift
In this new form factor, the OpenStack control services such as keystone, nova, glance and neutron that were once deployed as standalone containers on top of bare metal or virtual machines (VMs) are now deployed as native Red Hat OpenShift pods leveraging the flexibility, placement, abstraction and scalability of Kubernetes orchestration
The OpenStack compute nodes that are running VMs are still relying on RHEL, with the difference being that it is provisioned by Metal3 and configured by an OpenShift operator using Red Hat Ansible Automation Platform behind the scenes. It is worth noting that it’s still possible to bring preprovisioned nodes with RHEL pre-install.
New approach, new storage considerations
Deploying and managing the OpenStack control plane on top of OpenShift brings several new advantages, but it also comes with new storage considerations.
Previously, the OpenStack control plane was deployed as three “controllers” which usually took form as bare metal servers or, in some cases, VMs.
In terms of storage, the OpenStack control services used the server’s local disk(s) to write persistent data (or a network storage backend when booting from SAN).
With the shift to a native OpenShift approach, the OpenStack control services are dynamically scheduled across OpenShift workers as pods. This approach introduces a number of benefits, but the default pod storage option is to use ephemeral storage. Ephemeral storage is perfectly fine for stateless services such as the service’s API, but not appropriate for services that require persistent data such as the control plane database. When a pod restarts or terminates, it must get its data back.
Fortunately, OpenShift provides a persistent storage abstraction layer in the form of “Persistent Volumes” (PV) and “Persistent Volume Claim” (PVC) that enable pods to mount volumes that persist across pod’s lifecycle. This persistent storage framework is tightly coupled with another standard called Container Storage Interface (CSI) that allows OpenShift to provision volumes from a variety of storage backends should the storage vendor provide a certified CSI Driver.
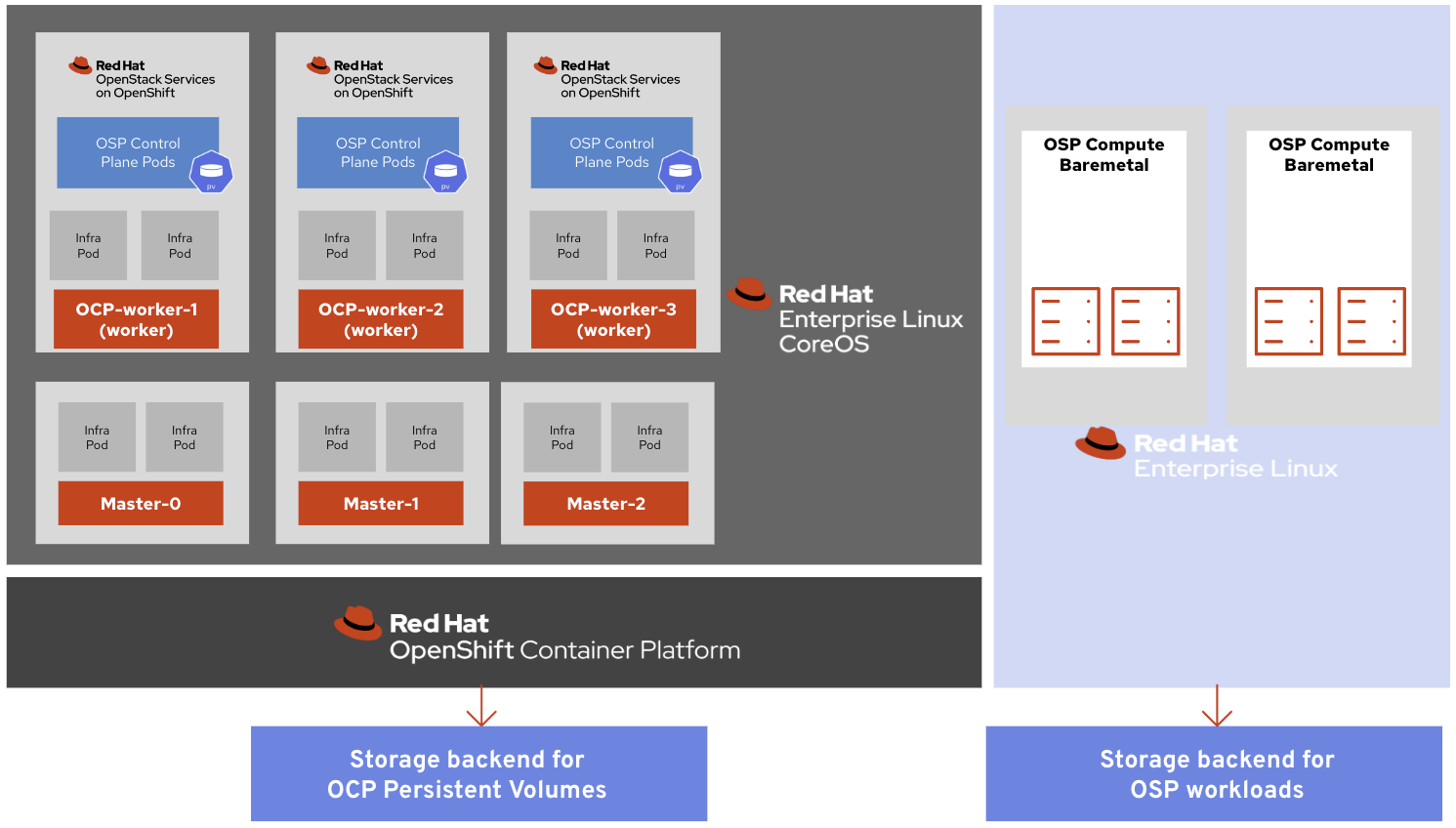
This is where the paradigm changes, in previous versions of Red Hat OpenStack, the control services' persistent data were stored on local controllers disks and no further design decisions were needed besides the size, type, performance and RAID level of the disks.
With OpenStack Services on OpenShift, a storage solution must also be considered for OpenShift alongside the traditional OpenStack storage.
In this article, we dive into the main available options to back OpenShift and OpenStack data for environments that are using Ceph or third-party storage solutions.
Before we get into the details, you may wonder which OpenStack control services need persistent storage:
- Glance for the staging area and optional cache
- Galera for storing the database
- OVN Northbound and Southbound database
- RabbitMQ for storing the queues
- Swift for storing object data when not using external physical nodes.
- Telemetry for storing metrics
Red Hat OpenStack Services on OpenShift with Red Hat Ceph Storage
Ceph is a well known and widely used storage backend for OpenStack. It can serve block with Nova, Glance and Cinder, file with Manila, and object with S3/SWIFT APIs.
The integration between OpenStack Services on OpenShift and Ceph is the same as previous OpenStack versions—block is served by RBD, file by CephFS or NFS and object by S3 or SWIFT.
The different OpenStack services are configured to connect to the Ceph cluster, but what changes is the way you configure it at install time, as we are now using native Kubernetes Custom Resources Definition (CDR) instead of TripleO templates as in previous versions.
The main design change is how to serve OpenShift volumes.
Using Ceph across both platforms
The first option is to use the same external Ceph cluster between OpenStack and OpenShift, consolidating the Ceph investment by sharing the storage resources.

In the above diagram, OpenStack is consuming Ceph as usual, and OpenShift uses OpenShift Data Foundation (ODF) external mode to connect to the same cluster. ODF external deploys the Ceph CSI drivers that allow OpenShift to provision persistent volumes from a Ceph cluster.
OpenStack and OpenShift use different Ceph pools and keys, but architects should review their cluster’s capacity and performance to anticipate any potential impact. It’s also possible to isolate the storage I/O of both platforms by customizing the CRUSH map and allowing data to be stored on different OSDs.
The design outlined above shares the same Ceph cluster between OpenShift and OpenStack but they can be different clusters based on the use case.
Third-party or local storage for OpenShift and Ceph for OpenStack
In some cases, you do not want to share OpenStack and OpenShift data on the same cluster. As mentioned before, it’s possible to use another Ceph cluster but the capacity needed for the control plane services may not be enough to justify it.
Another option is to leverage OpenShift’s workers' local disks. To do so, OpenShift includes an out-of-the-box LVM based CSI operator called LVM Storage (LVMS). LVMS allows dynamic local provisioning of the persistent volumes via LVM on the workers' local disks. This has the advantage of using local direct disk performance at a minimum cost.
On the other hand, if the data being local to the worker, the pods relying on volumes cannot be evacuated to other workers. This is a limitation to consider, especially if OpenStack control services are deployed on more than three workers.
It is also possible to rely on an existing third-party backend using a certified CSI driver which would remove the 1:1 pinning between the pod and the volume but can increase the cost. Using ODF internally as an OpenShift storage solution is also an option.
The OpenStack integration to Ceph remains the same.

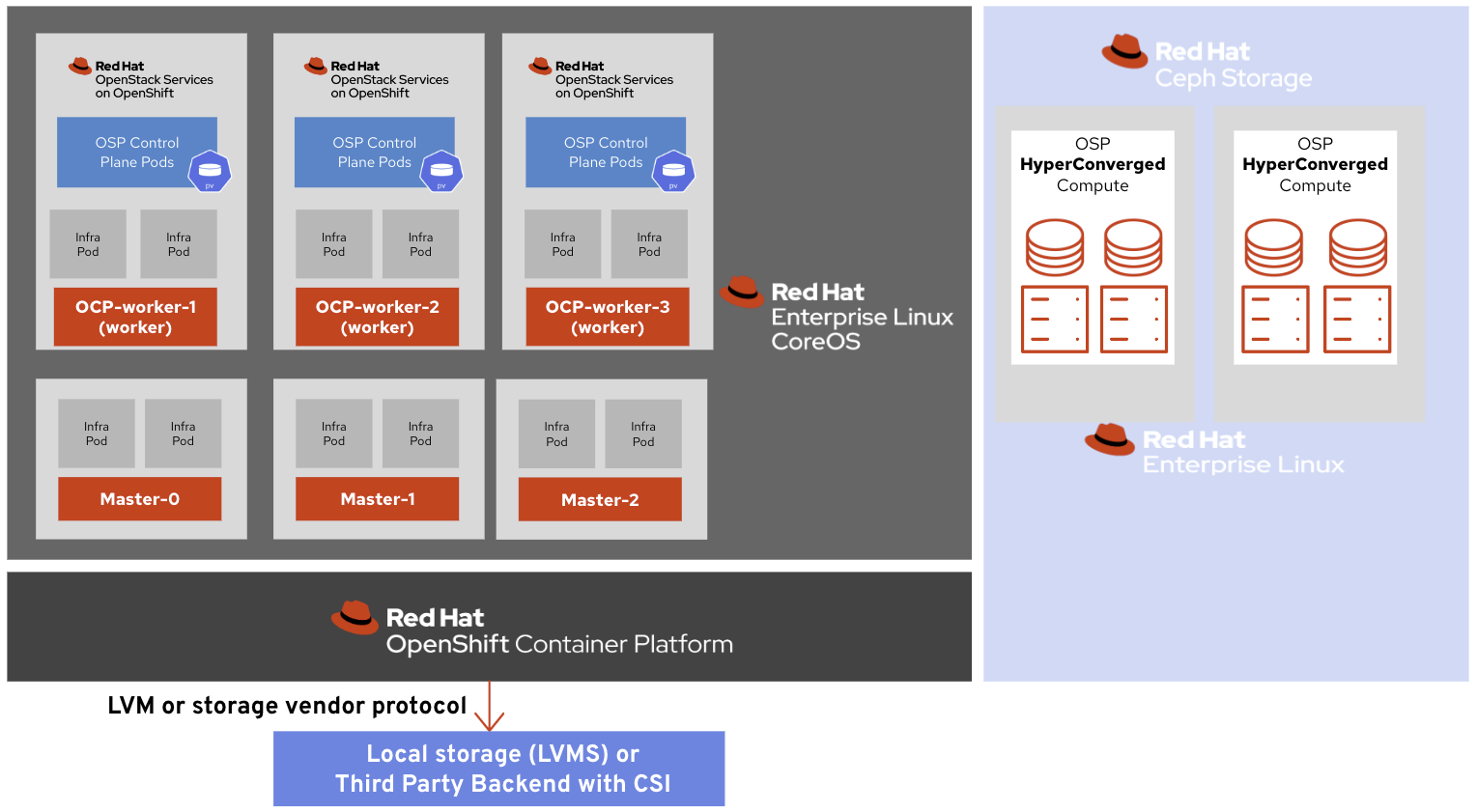
OpenStack with Ceph hyper-converged
Deploying Ceph hyper-converged with OpenStack compute nodes is a popular solution to combine both compute and storage resources on the same hardware, reducing the cost and hardware footprint.
The integration with Ceph does not differ from an external Ceph besides the fact that the compute and storage services are collocated.
The OpenShift storage options are more limited, however, as it is not possible to use the hyper-converged Ceph cluster to back OpenShift persistent volumes.
The options are the same as those outlined in the previous section—OpenShift can rely on LVMS to leverage the local worker disks or use an existing third-party backend with a certified CSI driver.
OpenStack with third-party storage solutions
For environments that are not using Ceph, the same principle applies. The OpenStack integration does not change, the control and compute services are configured to use an external shared storage backend through iSCSI, FC, NFS, NVMe/TCP or other vendor-specific protocols. Cinder and Manila drivers are still used to integrate the storage solution with OpenStack.
On the OpenShift side, the options are to either use LVMS to leverage the local worker disks or use an existing third-party backend with a certified CSI driver. This third-party backend can be the same as the one used for OpenStack or a different one.

Wrap up
As Red Hat OpenStack moves to a more modern OpenShift-based deployment model, new storage systems need to be considered. Red Hat OpenStack Services on OpenShift offers a broad set of options for storing the OpenStack control services and the end user’s data. Whether you’re using Ceph or not, and whether you want shared storage or to rely on local disks, the different supported combinations will match a vast set of use cases and requirements.
For more details on Red Hat OpenStack Services on OpenShift storage integration, please refer to our planning guide.
저자 소개
Gregory Charot is a Senior Principal Technical Product Manager at Red Hat covering OpenStack Storage, Ceph integration as well as OpenShift core storage and cloud providers integrations. His primary mission is to define product strategy and design features based on customers and market demands, as well as driving the overall productization to deliver production-ready solutions to the market. Open source and Linux-passionate since 1998, Charot worked as a production engineer and system architect for eight years before joining Red Hat in 2014, first as an Architect, then as a Field Product Manager prior to his current role as a Technical Product Manager for the Hybrid Platforms Business Unit.
유사한 검색 결과
Red Hat Enterprise Linux의 이미지 모드를 지금 바로 사용해야 하는 4가지 이유
강력한 보안, 즉시 사용 가능, 추가 비용 없이 제공: 컨테이너 보안의 진화
The Containers_Derby | Command Line Heroes
Can Kubernetes Help People Find Love? | Compiler
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래