With the release of RHEL AI 1.3, we’re excited to introduce context aware chunking powered by the Docling project, a significant enhancement that expands the capabilities of taxonomy contributions, pushes the limits of synthetic data generation and offers enhanced document support (pdf and md). Through our collaboration with IBM Research and adoption of Docling, RHEL AI 1.3 now features a new data ingestion pipeline.
This update enables seamless integration of PDF documents, marking a shift from the previous Markdown-only support in qna.yaml and a new chunking strategy for documents, context aware chunking which allows better representation of different document elements.
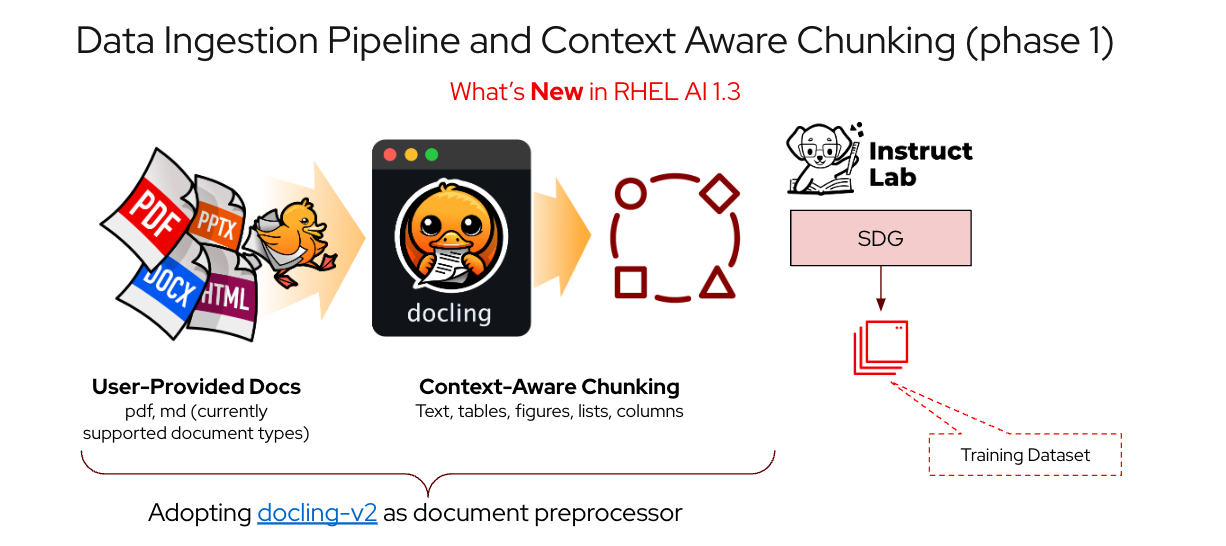
Fig 1: Docling Integration in RHEL AI brings improved chunking strategy and enhanced document support

Fig 2: Zoomed in view of data ingestion pipeline using Docling
What’s new?
PDF support
Contributors can now reference PDF documents directly in taxonomy submissions alongside Markdown files. This update eliminates the need to manually convert PDFs to Markdown, streamlining the contribution process.
With the support of pdf documents, end users can bring their personal/enterprise documents directly for model customization for their use cases. In RHEL AI 1.4, more document types such as word, pptx, docx, html will be supported allowing users to support a broad range of use cases.
Docling adoption/context aware chunking
With the adoption of Docling, the #1 open source document paper on GitHub, we are introducing a new context aware chunking capability. It intelligently recognizes and processes different document elements – from text and tables to figures, lists and columns. This means more accurate extraction and better understanding of your documents' structure and meaning. This is an improvement over naive chunking being used in RHEL AI 1.2.
We've also enhanced our synthetic data generation (SDG) pipeline to leverage these new capabilities. We are continuing our collaboration with IBM Research to push the boundaries of context-aware document processing even further in future releases.
Docling parses PDFs and converts them into structured, context-aware chunks. The tool accurately represents critical semantic elements, including text, tables and images and enhances contextual understanding for better synthetic data generation.
Why this matters
The addition of PDF support overcomes the limitations of Markdown-only workflows, enabling contributors to include richer, more detailed documents in their submissions. Docling’s robust chunking capabilities ensure that PDFs are no longer a barrier to streamlined knowledge integration, making taxonomy contributions faster, easier, and more effective.
Naive chunking strategies often result in poor outputs for synthetic data generation and thereby finetuning of language models. Context aware chunking can result in reduced hallucinations involving complex document structures. This can facilitate seamless integration across various departments within an organization, each handling complex document representations. Another capability we are working on is hierarchical context aware chunking that captures additional meta data such as headings/captions for better context.
제품 체험판
Red Hat Enterprise Linux AI | 제품 체험판
저자 소개

Aditi is a Technical Product Manager at Red Hat, working on Instruct Lab’s synthetic data generation capabilities. She is passionate about leveraging generative AI to create seamless, impactful end user experiences.

Aakanksha Duggal is a Senior Data Scientist at Red Hat, leading synthetic data generation efforts on Instructlab. Her work focuses on advancing scalable and impactful technologies in the field of AI.
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래