
In today’s Storage Tutorial, Brian chats with Red Hat’s Paul Cuzner of the storage business unit. Paul has been focused on finding new ideas and strategies where Red Hat Storage can make a difference for customers and, most recently, has spent time working with Splunk. Watch the video below to find out just how Paul and Red Hat work with customers to make the most of Splunk and their storage, but we’ve broken down one salient bit for you right here…keep reading!
Understanding Splunk data flows
Data arriving within a Splunk indexer, as it’s being parsed, is placed into a structure named a bucket – a directory in a file structure. This bucket is considered “hot” because its index is being actively built, or files are constantly being added or removed from it. When it reaches a certain size, or age, it moves to “warm” storage, meaning the index is built and closed, so no further information is added and it becomes a point of record.
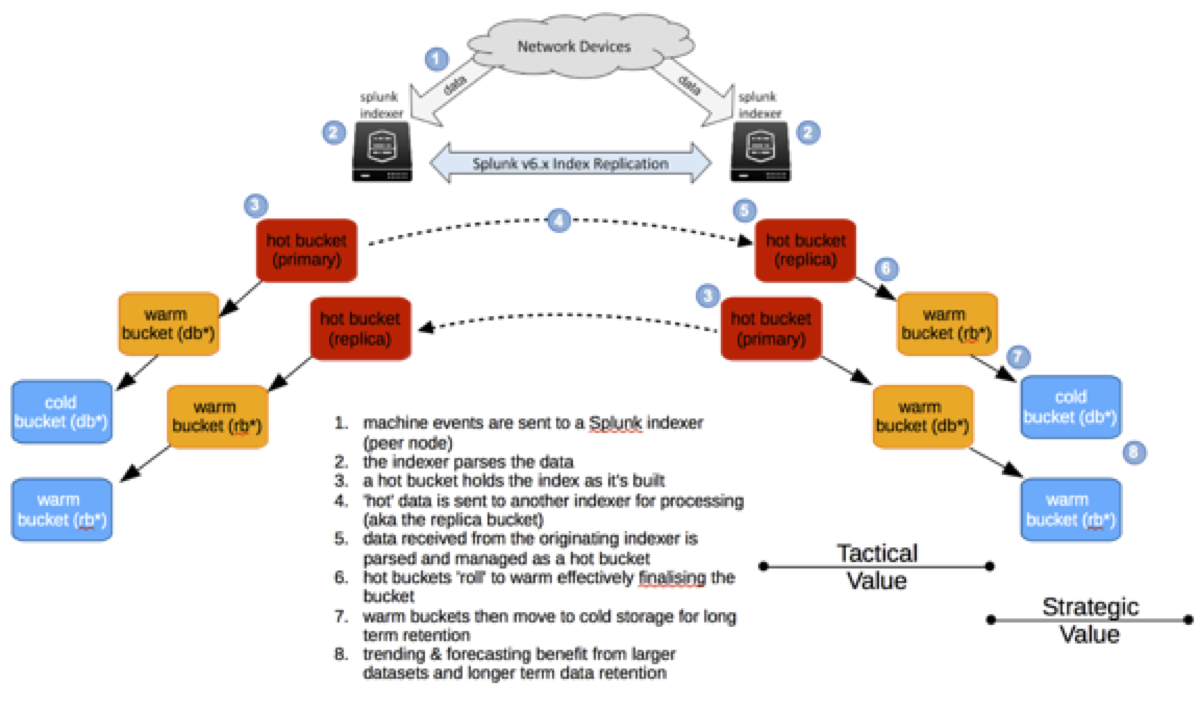 The Splunk data migration flow, illustrated!
The Splunk data migration flow, illustrated!
Hot and warm buckets, because they are considered to be in use or readily available, are typically placed on very fast storage – 10,000 or 15,000 RPM hard disks or flash storage, for example.
Eventually warm buckets are rolled into “cold” buckets. These are also not written to and are available for search. This storage, because it isn’t accessed quite as often, is typically placed on slower storage with very high capacity…and this is where customers struggle to choose a platform.
Be sure to check out the video, next:
저자 소개
유사한 검색 결과
에이전틱 AI가 요구하는 새로운 인프라 스택: AMD와 Red Hat의 솔루션 제공
과거의 운영 방식에서 벗어나 IT의 미래 구축
Infrastructure At The Edge | Compiler
Operating System Management | Compiler
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래