Data Processing Units (DPUs) represent a significant evolution in datacenter architecture. By offloading infrastructure tasks like networking, security, and storage from the main CPU, they promise to unlock new levels of cloud capabilities. Red Hat OpenShift 4.20 delivers a major breakthrough in solving the primary challenge of DPU adoption: vendor lock-in.
This new capability provides unified, vendor-agnostic support for different DPUs, all within a single cluster. This is the result of our focused, standards-based strategy. We began this journey by introducing tech preview support for the first DPU (the Intel IPU) in Red Hat OpenShift 4.19. By building on the open standards of the Open Programmable Infrastructure (OPI) project, our work for the 4.20 release has expanded this to include 2 additional DPUs: the Senao SX904 (Intel NetSec Accelerator) and the Marvell Octeon 10.
This directly addresses the industry's largest DPU challenge: the fragmented landscape. Until now, organizations have been forced into isolated, vendor-specific environments, each with proprietary tools, drivers, and APIs. This approach eliminates that fragmentation. As we've discussed in cloud-native enablement of DPUs, our goal is to make DPUs a smoothly integrated and abstracted component of Red Hat OpenShift.
A unified management platform for diverse hardware
Our integration work is centered on a standard Red Hat OpenShift cluster. The key differentiation is at the worker nodes: each one is equipped with a DPU from a different hardware vendor, including Intel and Marvell.
Through a common, OPI-based management layer, OpenShift is able to discover, manage, and deploy workloads to this heterogeneous hardware. This eliminates the need for vendor-specific toolchains and allows operators to manage their entire infrastructure—from the host CPU to the DPU—from the OpenShift platform.
Standardized discovery through abstraction
In a traditional multivendor environment, an operator would need to use separate tools just to identify the hardware in their cluster. Our approach simplifies this down to a single, familiar command.
By running oc get dpu, an operator can instantly query the cluster and receive a complete list of all detected DPUs, their vendor, and their current health status, all through the OPI API.
$ oc get dpu
NAME DPU PRODUCT DPU SIDE MODE NAME STATUS
030001163eec00ff-host Intel Netsec Accelerator false worker-host-ptl-243 True
d4-e5-c9-00-ec-3v-dpu Intel Netsec Accelerator true worker-dpu-ptl-243 True
intel-ipu-0000-06-00.0-host Intel IPU E2100 false worker-host-ipu-219 True
intel-ipu-dpu Intel IPU E2100 true worker-dpu-ipu-219 True
marvell-dpu-0000-87-00.0-host Marvell DPU false worker-host-marvell-41 True
marvell-dpu-ipu Marvell DPU true worker-dpu-marvell-41 TrueThis is possible because the hardware-specific logic is contained within vendor-specific plugins that adhere to the OPI standard. The underlying complexity is abstracted away from the user—whether a developer deploying an application or a platform operator managing the cluster. OpenShift simply sees a pool of "DPU" resources ready for work.
While the output here shows all DPUs managed within one cluster, our operator-based architecture also supports multicluster deployments (where the DPU is part of a separate cluster). This is simply a deployment detail; the user experience and OPI-based management remain consistent across both models.
Deploying workloads with Kubernetes-native primitives
The most significant benefit of this abstraction is the ability to deploy workloads using the standard, declarative tools that teams already know. When the cluster is ready for workloads, deploying and moving workloads across DPUs is straightforward.
There is no need to learn proprietary SDKs or write custom scripts for each DPU. We can deploy containerized workloads directly to any DPU using a standard Kubernetes YAML file. The only difference required is to specify which DPU to run on using a simple nodeSelector; regardless of the vendor details, the system will schedule the workload accordingly.
apiVersion: v1
kind: Pod
metadata:
- name: "intel-netsec-accelerator-pod"
+ name: "marvell-dpu-pod"
namespace: openshift-dpu-operator
...
- kubernetes.io/hostname: worker-dpu-ptl-243
+ kubernetes.io/hostname: worker-dpu-marvell-41
dpu.config.openshift.io/dpuside: "dpu"This brings the cloud-native operational model to DPU-accelerated infrastructure. It empowers developers to consume DPU resources just as they would any other resource in the cluster, dramatically lowering the barrier to adoption.
Enabling true workload portability and interoperability
This unification extends deep into the network. The OPI Networking API allows OpenShift to build a unified overlay data plane that spans all DPUs, regardless of the vendor, as well as the host nodes.
This creates a streamlined, programmable network where all workloads can communicate. A pod running on a DPU from one vendor can communicate directly with a pod running on a DPU from another vendor. In the diagram below, green and blue pods are part of the same network. This demonstrates true workload portability and, just as importantly, interoperability, allowing all pods to communicate freely.
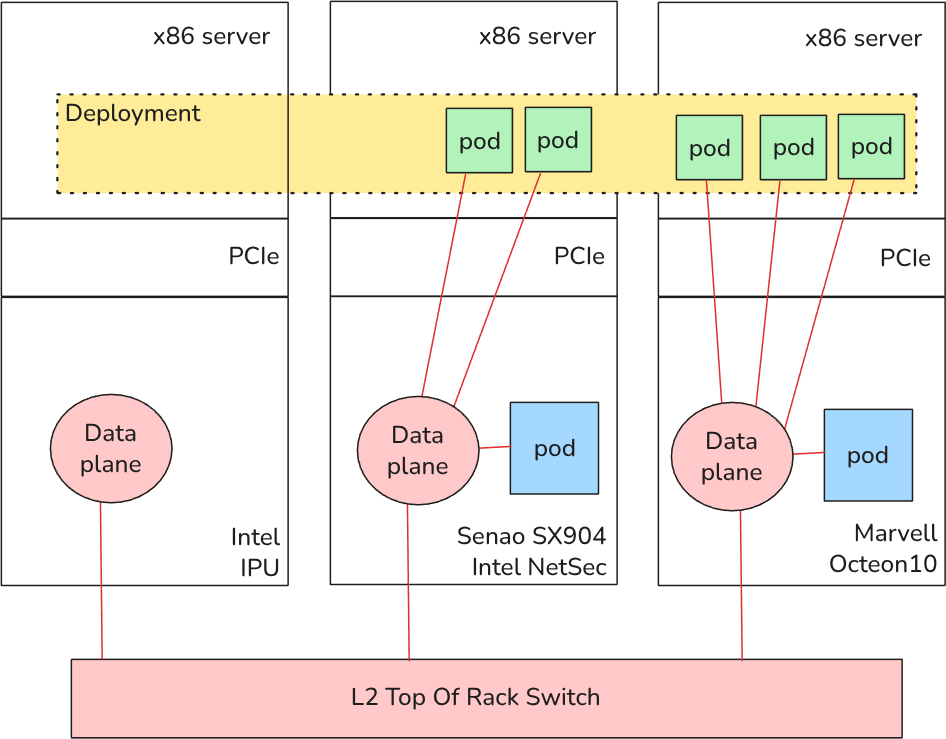
What this means for Red Hat customers
This capability is the foundation of our strategy for DPU-offloaded infrastructure on Red Hat OpenShift.
Our plan is to continue extending this support, integrating the unique benefits and accelerators of each DPU vendor into the OpenShift platform.
The goal is simple: to provide a streamlined transition to a DPU-equipped cluster without vendor lock-in. This unified, operator-based approach means you can start with an OpenShift cluster without DPUs and, when you are ready, add DPUs into worker nodes to it at any time.
We do the hard work of abstracting the hardware-level complexity so you can focus on your applications, not on vendor-specific drivers or proprietary SDKs. As we move these capabilities from tech preview toward general availability, we are actively working with customers and partners.
If you are running OpenShift 4.20 or later and are starting your DPU journey, or are looking to escape existing vendor lock-in, now is the time to engage with Red Hat. There is no need to reinstall or re-architect your cluster from scratch to begin taking advantage of DPU technology. See how this unified platform can simplify your infrastructure roadmap and allow you to evolve your cluster at your own pace.
제품 체험판
Red Hat OpenShift Container Platform | 제품 체험판
저자 소개

Balazs Nemeth is a Senior Principal Software Engineer at Red Hat. He's the tech lead and team lead of the Hardware Enablement Team specializing in end-to-end enablement of DPUs in Openshift.
유사한 검색 결과
CVE-2026-31431: How Red Hat Advanced Cluster Security and Red Hat Advanced Cluster Management can help
Strengthening the enterprise foundation: Red Hat and Oracle’s expanding collaboration
Collaboration In Product Security | Compiler
Keeping Track Of Vulnerabilities With CVEs | Compiler
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래