
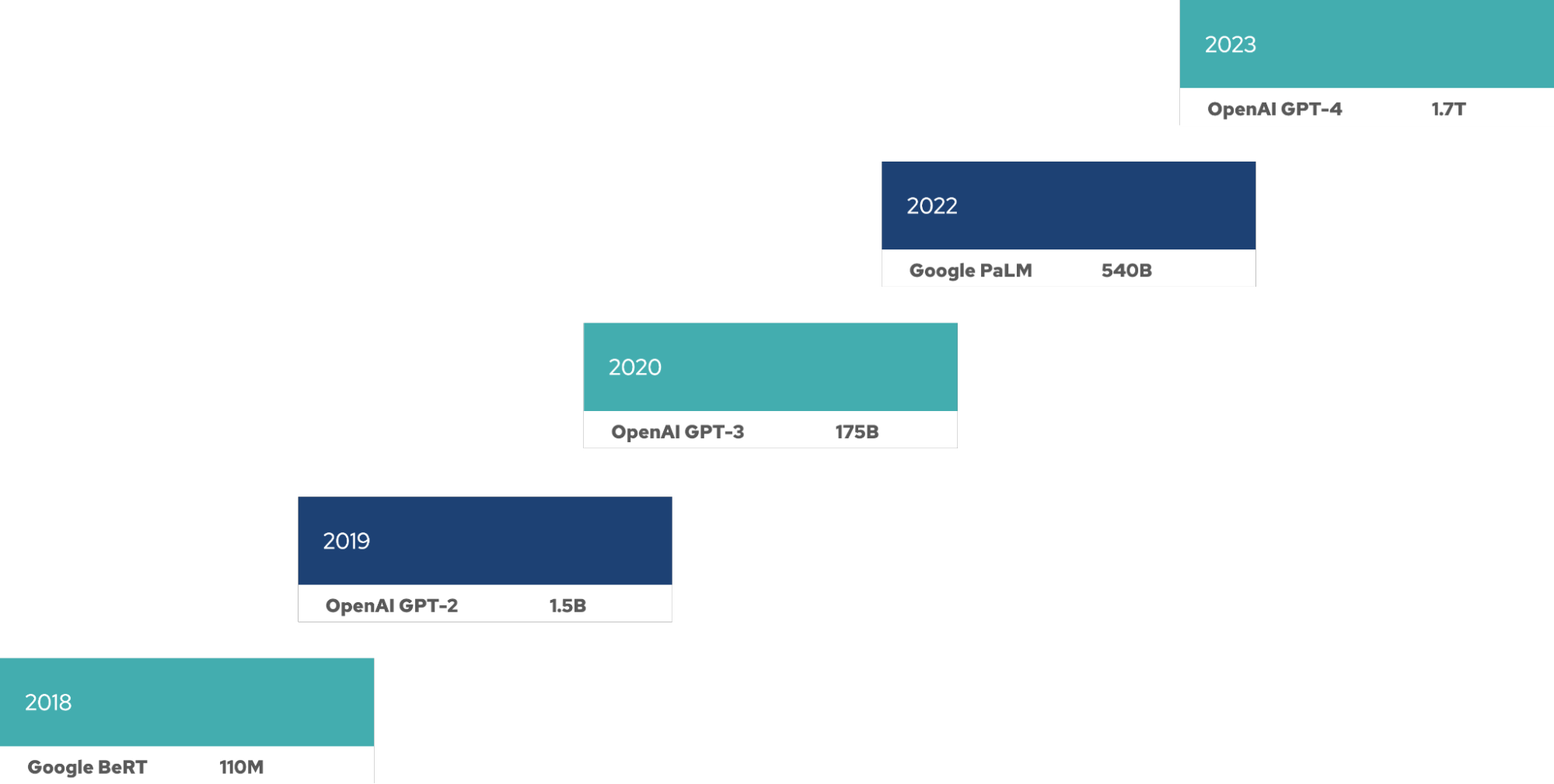
Parece que qualquer Large Language Model (LLM) fica cada vez maior a cada lançamento. Isso exige um grande número de GPUs para treinar o modelo, e mais recursos são necessários ao longo do ciclo de vida desses modelos para ajuste fino, inferência e assim por diante. Há uma nova Lei de Moore para esses LLMs: o tamanho do modelo (medido por números de parâmetros) dobra de tamanho a cada quatro meses.
LLMs são caros
Treinar e operar um LLM é caro em termos de recursos, tempo e dinheiro. Os requisitos de recursos têm um impacto direto nas empresas que implantam um LLM, não importa se é em sua própria infraestrutura ou usando um hyperscaler. E os LLMs estão ficando cada vez maiores.
Além disso, manter a operação de um LLM exige muitos recursos. O LLM do Llama 3.1 tem 405 bilhões de parâmetros e exige 810 GB de memória (FP16) somente para inferência. A família de modelos do Llama 3.1 foi treinada em 15 trilhões de tokens em um cluster de GPU com 39 milhões de horas de GPU. Com o aumento exponencial do tamanho do LLM, os requisitos de computação e memória para treinamento e operação também estão crescendo. O ajuste fino do Llama 3.1 exige 3,25 TB de memória.
Houve uma grave escassez de GPUs no ano passado. Conforme a lacuna entre oferta e demanda está melhorando, o próximo obstáculo deve ser a energia. Com mais data centers entrando em operação e o consumo de eletricidade em cada um dobrando para quase 150 MW, é fácil perceber por que isso se tornaria um problema para o setor de IA.
Como reduzir o custo dos LLMs
Antes de discutirmos como tornar os LLMs mais baratos, considere um exemplo de algo que todos já conhecem. As câmeras estão sempre melhorando, com novos modelos tirando fotos com resolução mais alta do que nunca. No entanto, os arquivos de imagem bruta podem ter até 40 MB (ou mais) cada. A menos que você seja um profissional de mídia que precise manipular essas imagens, a maioria das pessoas se contenta com uma versão da imagem em formato JPEG, reduzindo o tamanho do arquivo em 80%. É claro que a compactação usada pelo JPEG diminui a qualidade da imagem do original RAW, mas o JPEG é bom o suficiente para a maioria dos propósitos. Além disso, geralmente são necessárias aplicações especiais para processar e visualizar uma imagem RAW. Portanto, lidar com imagens RAW tem um custo computacional maior em comparação a uma imagem JPEG.
Agora, vamos voltar a falar sobre LLMs. O tamanho do modelo depende do número de parâmetros. Portanto, uma das abordagens é usar um modelo com um número menor de parâmetros. Todos os modelos open source mais conhecidos vêm com uma variedade de parâmetros, permitindo que você escolha aqueles que melhor se adequam a uma aplicação específica.

No entanto, um LLM com um número maior de parâmetros geralmente supera um com menos parâmetros na maioria dos benchmarks. Para reduzir os requisitos de recursos, talvez seja melhor usar um modelo de parâmetros maior, mas compactá-lo para um tamanho menor. Testes demonstraram que a compactação GAN pode reduzir a computação em quase 20 vezes.
Existem dezenas de abordagens para compactar um LLM, incluindo quantização, poda, destilação de conhecimento e redução de camadas.
Quantização
A quantização altera os valores numéricos em um modelo do formato de ponto flutuante de 32 bits para um tipo de dados de precisão mais baixa: ponto flutuante de 16 bits, número inteiro de 8 bits, número inteiro de 4 bits ou até mesmo número inteiro de 2 bits. Ao diminuir o tipo de dados de precisão, o modelo precisa de menos bits durante as operações, resultando em menos memória e computação. A quantização pode ser feita após o modelo ser treinado ou durante o processo de treinamento dele.
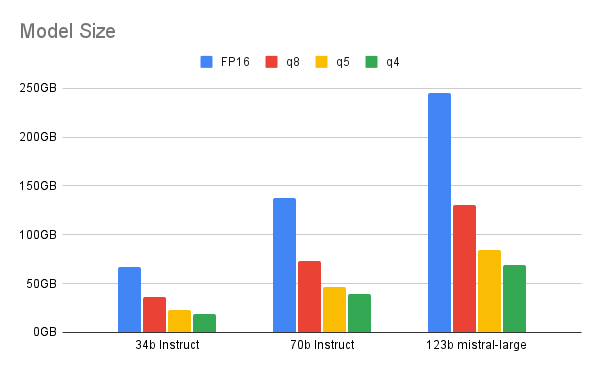
À medida que avançamos para bits mais baixos, há uma relação de compensação entre quantização e desempenho. Este artigo destaca o intervalo ideal oferecido pela quantização de 4 bits para modelos maiores (pelo menos 70 bilhões de parâmetros). Qualquer valor menor mostra uma discrepância de desempenho perceptível entre o LLM e seu equivalente quantizado. Para um modelo menor, a quantização de 6 ou 8 bits pode ser uma escolha melhor.
Graças à quantização, posso executar esta demonstração de RAG em LLM no meu laptop.
Poda
A poda reduz o tamanho do modelo eliminando pesos ou neurônios menos importantes. Um equilíbrio delicado é necessário entre a redução do tamanho do modelo e a preservação da precisão. A poda pode ser feita antes, durante ou depois do treinamento do modelo. A poda de camadas leva essa ideia adiante, removendo blocos inteiros de camadas. Neste artigo, os autores relatam que até 50% das camadas podem ser removidas com uma degradação mínima de desempenho.
Destilação de conhecimento
Transfere conhecimento de um modelo grande (o professor) para um modelo menor (o aluno). O modelo menor é treinado com as saídas do modelo maior, em vez de dados de treinamento maiores.
Este artigo mostra como a destilação do modelo BERT do Google no DistilBERT reduziu o tamanho do modelo em 40%, aumentou a velocidade de inferência em 60% e reteve 97% dos recursos de compreensão de linguagem.
Abordagem híbrida
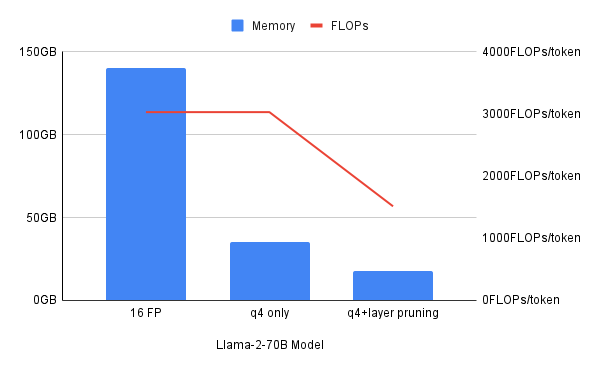
Embora cada uma dessas técnicas de compactação individuais seja útil, às vezes uma abordagem híbrida que combina diferentes técnicas de compactação funciona melhor. Este artigo mostra como a quantização de 4 bits reduz as necessidades de memória em quatro vezes, mas não os recursos computacionais medidos por FLOPS (operações de ponto flutuante por segundo). A quantização combinada com a poda de camadas ajuda a reduzir a memória e os recursos de computação.
Benefícios do modelo de menor tamanho
Usar modelos menores pode reduzir significativamente os requisitos computacionais, mantendo um alto nível de desempenho e precisão.
- Custos de computação menores: modelos menores exigem menos requisitos de CPU e GPU, resultando em economias significativas. Considerando que as GPUs de ponta podem custar até US$ 30 mil cada, qualquer redução no custo computacional é uma boa notícia.
- Redução do uso de memória: modelos menores exigem menos memória em comparação com os modelos maiores. Isso ajuda as implantações de modelos em sistemas com recursos limitados, como dispositivos de IoT ou celulares.
- Inferência mais rápida: modelos menores podem ser carregados e executados rapidamente, o que resulta em uma latência de inferência reduzida. Uma inferência mais rápida pode fazer uma grande diferença para as aplicações em tempo real, como as de veículos autônomos.
- Redução da pegada de carbono: a redução dos requisitos computacionais de modelos menores ajuda a melhorar a eficiência energética, reduzindo, assim, o impacto ambiental.
- Flexibilidade de implantação: requisitos computacionais menores aumentam a flexibilidade para implantar modelos onde for necessário. Os modelos podem ser implantados para atender às necessidades dinâmicas do usuário ou às restrições do sistema, incluindo a edge da rede.
Modelos menores e mais baratos estão se tornando mais comuns, como fica evidente pelos lançamentos recentes do ChatGPT-4o mini (60% mais barato que o GPT-3.5 Turbo) e pelas inovações dos modelos open source, como o SmolLM e Mistral NeMo:
- Hugging Face SmolLM: uma família de pequenos modelos com 135 milhões, 360 milhões e 1,7 bilhão de parâmetros
- Mistral NeMo: um modelo pequeno com 12 bilhões de parâmetros, criado em colaboração com a Nvidia
A tendência de usar SLM (Small Language Models) é impulsionada pelos benefícios discutidos acima. Há muitas opções disponíveis com modelos menores: use um modelo pré-criado ou técnicas de compactação para reduzir um LLM existente. Seu caso de uso deve guiar a escolha da abordagem ao selecionar um modelo pequeno. Portanto, considere suas opções com a devida atenção e cuidado.
Sobre o autor
Ishu Verma is an AI Solution Architect at Red Hat dabbling in emerging technologies like AI Ops, AI safety and security. He, along with fellow open source hackers, works on building enterprise focused solutions with open source technologies. Prior to Red Hat, Ishu worked in technical marketing at Intel on IoT Gateways and building end-to-end IoT solutions with partners.
Mais como este
O paradoxo agêntico e o argumento a favor da IA híbrida
Pare de gerenciar o passado e comece a construir o futuro da TI
Technically Speaking | Inside open source AI strategy
Technically Speaking | Build a production-ready AI toolbox
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem