We are happy to announce a record-breaking performance with NVIDIA in the STAC-A2 benchmark, affirming Red Hat OpenShift's ability to run compute heavy, high performance workloads. The Securities Technology Analysis Center (STAC®) facilitates a large group of financial firms and technology vendors that produces benchmark standards which enable high-value technology research and testing software for multiple financial applications.
Red Hat and NVIDIA collaborated to create this latest STAC-A2 entrant, and STAC performed an independent, third-party audit. These are the first public STAC-A2 results using Red Hat OpenShift. Compared to all other publicly reported results to-date, this solution based on Red Hat OpenShift and NVIDIA DGX A100 set several new records for performance metrics and energy efficiency:
- highest energy efficiency1
- highest space efficiency2
- highest throughput3
- fastest warm & cold start times in the large Greeks benchmark4
- fastest warm time in the baseline Greeks benchmark5
- highest maximum paths6
- highest maximum assets7
Below is the high-level architectural diagram of the benchmark configuration that was used.
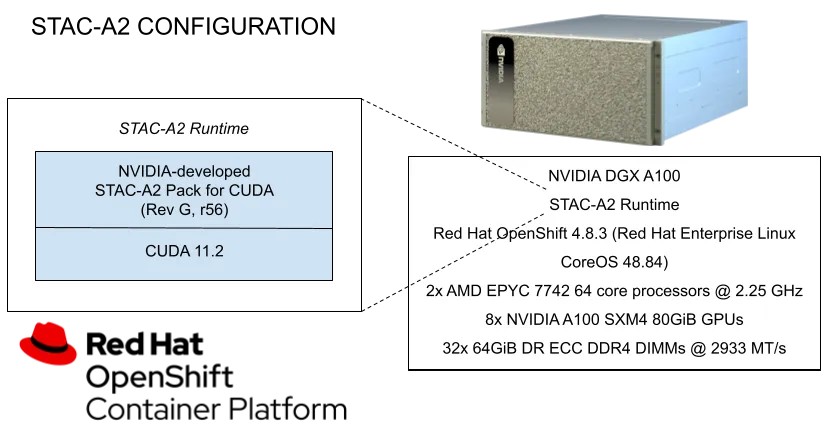
Below, I’ve provided an overview of the technologies and best practices needed to run this STAC-A2 workload. These practices should be generally applicable to running any compute-intensive applications, including those that use Monte Carlo simulation, and need to take advantage of powerful NVIDIA GPUs, such as those featured in the NVIDIA DGX A100 used to run these record-breaking benchmarks.
First, some background on the STAC-A2
The STAC-A2 Benchmark suite is the industry standard for testing technology stacks used for compute-intensive analytic workloads involved in pricing and risk management. This benchmark is tightly linked to what is known as Monte Carlo simulation, which has numerous applications in finance and scientific fields.
Red Hat is an active STAC member both supporting the performance tuning and execution of vendor benchmarks, as well as contributing artifacts to simplify and modernize the execution for cloud-native platforms, such as Red Hat OpenShift.
Running high performance containerized workloads on Red Hat OpenShift already has delivered impressive performance results. The Red Hat OpenShift Performance Sensitive Applications (PSAP) team that I’m on has done a lot of work to simplify and enable the use of accelerator cards and special devices on Red Hat OpenShift.
There are three available Red Hat OpenShift operators that simplify setup and configuration of devices that require out-of-tree drivers as well as other special purpose devices: the Node Feature Discovery Operator (NFD), the NVIDIA GPU Operator and the Node Tuning Operator (NTO). Conveniently, NTO comes with Red Hat OpenShift and the other two operators can be found in and installed via OperatorHub from within Red Hat OpenShift.
The Node Feature Discovery Operator
The NFD is the prerequisite to exposing node-level information to the kubelet. NFD manages the detection of hardware features and configuration in an Red Hat OpenShift cluster by labeling the nodes with hardware-specific information (PCI devices, CPU features, kernel and OS information, etc.). With this information available to the Red Hat OpenShift cluster, other operators can work off this information to enable the next layer of functionality. Here are instructions for setting up NFD operators.
The NVIDIA GPU Operator
In our configuration, the next layer to be installed is the NVIDIA GPU Operator, which brings the necessary drivers to the nodes that have NVIDIA GPU devices. The PSAP team also created the Special Resource Operator (SRO) pattern as a basis to enable out of tree driver support in Red Hat OpenShift and to expose these special resources to the Red Hat OpenShift scheduler.
The NVIDIA GPU Operator is based off of this (SRO) pattern, and we worked alongside NVIDIA to co-develop this operator. The GPU Operator release 1.8 was the first to support the NVIDIA DGX A100, the system under test (SUT) for this benchmark.
Once the GPU Operator is installed, the kernel modules are built and loaded for the nodes with the devices and the kubelet gains even more information regarding the GPU devices on the applicable nodes. This extra information allows the scheduler to see these new special resources and schedule them as you traditionally would with CPU or memory, by requesting the desired resources per pod. Follow these installation instructions to set up NVIDIA GPU Operator.
The Node Tuning Operator
The final operator in this stack is the NTO, which comes pre-installed in any standard Red Hat OpenShift 4 installation. The NTO helps manage node-level tuning by orchestrating the TuneD daemon. The NTO provides a unified management interface to users of node-level sysctls via TuneD profiles and also more flexibility to add custom tuning specified by user needs.
Given that we’re trying to optimize the system performance for our specific hardware accelerator needs, the NTO makes it very easy to set a pre-existing profile for this specific purpose, i.e., “accelerator-performance.”
Applying the profile
To apply the “accelerator-performance” profile to the DGX A100 node:
- Find label to match node such as
nvidia.com/gpu.present - Create tuned profile:
apiVersion: tuned.Red Hat OpenShift.io/v1
kind: Tuned
metadata:
name: Red Hat OpenShift-node-accelerator-performance
namespace: Red Hat OpenShift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Custom Red Hat OpenShift node profile for accelerator workloads
include=Red Hat OpenShift-node,accelerator-performance
name: Red Hat OpenShift-node-accelerator-performance
recommend:
- match:
- label: nvidia.com/gpu.present
priority: 20
profile: Red Hat OpenShift-node-accelerator-performance
Verify the profile has been applied to the desired node (that has gpu.present label):
$ oc get profile NAME TUNED APPLIED DEGRADED AGE master01 Red Hat OpenShift-control-plane True False 4d worker01 Red Hat OpenShift-node True False 4d master02 Red Hat OpenShift-control-plane True False 4d worker02 Red Hat OpenShift-node True False 4d master03 Red Hat OpenShift-control-plane True False 4d dgxa100 Red Hat OpenShift-node-accelerator-performance True False 4d
Now that we have the Red Hat OpenShift cluster ready to run GPU-enabled applications, the most difficult component is likely to be the containerization of your actual workload. Fortunately, if you have experience with creating containers outside of Red Hat OpenShift, the same concepts apply here.
Given that we are trying to use a CUDA implementation of STAC-A2, we used a base image from the NVIDIA NGC image repository: nvcr.io/nvidia/cuda11.2.0-devel-ubi8. This container has the CUDA 11.2 development libraries and binaries running on a Red Hat Universal Base Image (UBI) 8, and it provides a preferred and tested environment right out of the box.
The STAC benchmarks are a great example of traditional Linux applications that were not designed with containerization in mind. They have multiple components and dependencies to each benchmark suite such as input data generation, implementation compilation, quality assurance binaries, chart generation and a variety of shell script customizations. However, it is still possible to successfully containerize these benchmarks and build them in an automated fashion.
Red Hat contributes these example artifacts to the STAC Vault, where STAC member companies can find resources to either build and run the benchmark in their own environment or as a starting point for containerization of their workloads. STAC member companies can take a look at the Red Hat OpenShift for STAC-A2 repo in the STAC Vault to find these artifacts.
Now all that remains is deploying our containerized GPU/CUDA workload to the cluster. Here is the yaml necessary to deploy the NVIDIA STAC-A2 container on Red Hat OpenShift:
apiVersion: v1
kind: Namespace
metadata:
labels:
stac: a2-nvidia
name: stac
---
apiVersion: v1
kind: Pod
metadata:
labels:
app: stac-a2-nvidia
name: stac-a2-nvidia
namespace: stac
spec:
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
restartPolicy: Never
containers:
- name: stac-a2-nvidia
image: "quay.io/sejug/stac-a2-nv:dgxa100-cuda1120-40"
command: ['sh', '-c', 'entrypoint.sh']
imagePullPolicy: Always
securityContext:
privileged: true
env:
- name: NVIDIA_VISIBLE_DEVICES
value: all
resources:
limits:
nvidia.com/gpu: 8 # requesting 8 GPUs
nodeSelector:
node-role.kubernetes.io/worker: ""
We create a new namespace stac that will be populated with a single pod. We have specified that this pod be created on a worker node with a nvidia.com/gpu. Since we’re deploying this on a NVIDIA DGX A100, we’ve asked for a node that has eight GPUs available and we’ve asked that all the devices are visible to the container.
It is not generally necessary to make the pod privileged in order to run GPU workloads, as we have done in the yaml above. However, in our test execution we use nvidia-smi apply some device-level tuning, which does require these privileges.
With the advancements in Red Hat OpenShift enabled by operators such as the NVIDIA GPU Operator, it’s now easier than ever to make the most of GPUs/special hardware in heterogeneous cluster environments. The convenience of workload deployment and management provided by Red Hat OpenShift has been repeatedly demonstrated in real-world deployments. Benchmarks bring into light the overall performance of the entire solution. This latest record-breaking STAC-A2 benchmark result produced in conjunction with NVIDIA DGX systems is another product of our joint focus on performance.
Sobre o autor

Sebastian Jug, a Senior Performance and Scalability Engineer, has been working on OpenShift Performance at Red Hat since 2016. He is a software engineer and Red Hat Certified Engineer with experience in enabling Performance Sensitive Applications with devices such as GPUs and NICs. His focus is in automating, qualifying and tuning the performance of distributed systems. He has been a speaker at a number of industry conferences such as Kubecon and STAC Global.
Mais como este
OpenShift: integração consistente para a empresa híbrida
Principais atualizações do Red Hat Certification
Technically Speaking | Taming AI agents with observability
Python's Tale | Command Line Heroes
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem