
NFV (Network Function Virtualization) has taken the telecommunications world by storm in recent years. Communications service providers plan to run their core services in virtual machines, running on a standardized, open source platform. This promises to reduce both capital and operation costs, and most importantly, to accelerate the delivery of new services to market through increased agility.
The Open Platform for NFV (OPNFV) project is deploying a collection of open source projects, including OpenStack as the Infrastructure-as-a-Service layer, OpenDaylight and Open vSwitch for virtual network, Ceph for virtual storage, and libvirt and qemu/KVM for virtual compute. OpenStack and OpenDaylight are themselves collections of multiple projects, each with their own set of maintainers. All told, the OPNFV platform consists of around 20 different projects, many of which will need to be changed to satisfy the performance and reliability constraints of an NFV platform.
How vendors make and distribute those changes will vary from one to another. Some participants will attempt to maintain differentiation by developing features in private, and integrating them in their products without ensuring the changes will be integrated into the upstream open source projects. Others will propose changes at the same time as they are released in a product.
Red Hat is a company with a policy we call “upstream first” - we work to get features integrated into open source projects before we integrate them into our product offerings. Wouldn't it be easier just to develop features for our customers, and let the upstream projects figure out what they care about? What are the costs associated with the upstream first approach? Why do we take this approach?
The short answer is because it is the cheapest, most sustainable way to innovate on an open source platform. To explain why, I will explore what it means to build on top of open source projects, the different approaches people take to doing it, and the costs associated with each approach.
Private fork

The simplest way to build something on top of open source is to take the source code at a moment in time, and use it. If you need to make any changes, make them in your copy, and maintain the difference yourself.
This has a lot of merit, especially if you plan to use the project essentially unchanged. However, if you build up a lot of changes on top of the upstream project, you quickly end up in a conundrum. You are missing out on all of the work which is being done on the upstream project. Mal Minhas of the now defunct Limo Foundation described this as “unleveraged potential” (PDF link).
For instance, one online retail company who shall remain unnamed told me recently that they still had a lot of infrastructure running on Linux kernels from 2008, because they made significant changes for performance and reliability in their environment.
On the other hand, moving to a newer version of the upstream project and integrating all of your features and fixes there is not straightforward either. This is called merging, or rebasing.

The costs here include the development cost of all of your own work, plus the cost of resolving conflicts when the community works in the same files as you have, plus the cost of testing and qualifying your release for production, working out an upgrade and roll-out path, adapting your work to new APIs and features in the upstream project. You may encounter regression issues because of interactions of your code and the new upstream features, or expose issues which had not been seen before, leading to an increase in the delta between your branch and the upstream project.

Many companies are “stuck” maintaining old versions of projects because the cost of rebasing to more recent versions of projects are expensive, and difficult to evaluate. This problem is worse the more code you have specific to your private fork. And of course, this is not a one-time operation! A year or two later, you will have another multi-month effort to review all of your code against the new upstream, re-merge new code, re-develop some of your code, re-test everything, re-deploy, re-upgrade, etc. This cost will compound over time, and if you are actively developing your code, it will slow down progress considerably. Soon, your development team will be spending more time on merging and upgrading the underlying platform, and fixing the resulting issues, than they will on developing new code.
If your offering is built on multiple open source projects, this problem compounds itself. A feature like supporting SR-IOV virtual functions in OpenStack instances, a frequently requested feature for NFV, requires multiple patches in OpenStack Compute (Nova), libvirt, qemu-kvm, and the Linux kernel. If all of these patches are living out of the upstream source tree, on a long-term fork, any update to the upstream projects could cause significant rework on all of these interdependent patches.
In the case of OPNFV, maintaining significant patches on a vendor branch across multiple open source projects is simply unsustainable. Once people have gone through this process once or twice, they inevitably get around to thinking that submitting their changes back to the parent project, in the interests of reducing this merge and maintenance burden, is a good idea.
Swimming upstream
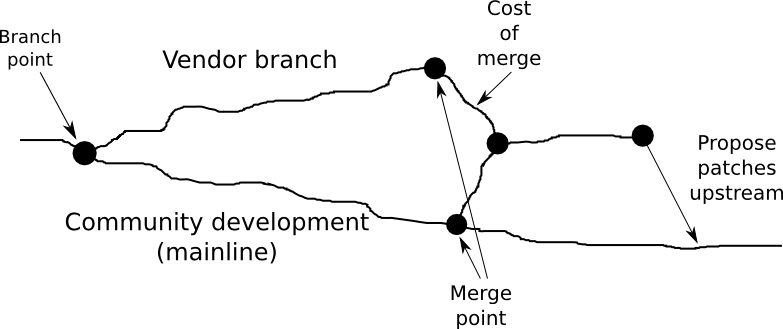
To the untutored eye, it might seem straightforward to submit features and patches to an open source project. These contributions can be useful to others, and represent a lot of work on behalf of the submitter, so one might expect upstream projects to be grateful to get new contributions. In reality it is not so straightforward. First, it is unlikely that patches written privately follow the project's coding guidelines. Second, developers writing code for a private branch may take shortcuts to solve a problem which makes a patch unsuitable for a large project. Third, open source projects expect developers to do a number of things which it is unlikely you have done.
One example of this is where you are expected to propose patches. As a company building a product on an open source project, you will typically want to build on a stable base – you wait for a stable release, and start from this base to add your features and patches. As long as the code is only used by you, this is fine, but when you want to submit the code upstream, the community will want patches to be proposed against the latest development branch. If you are several months or years removed from the stable branch you are using, this could involve considerable rework.
Another issue is that any code you submit upstream will be very difficult to digest unless it is cut into small, stand-alone patches, and each one needs to be submitted and accepted independently. Doing this after the fact, potentially years after the code was written, is a huge job.
Even when you have done this work, there is no guarantee that your proposed patches will be well received – perhaps the maintainer of the project disagrees with how you solved a problem, or another community member is working on a more elegant solution. The maintainer or community may not even care about your problem, or agree that it needs solving.

So, the ideal way to work is to develop your features against the unstable branch of the upstream project – this way, patches can be proposed as soon as they're ready. Your product offering may be based on a stable release of the project – when you want to integrate new features into your product, these features should be taken from the development branch and backported to the stable branch, which moves much more slowly, and where the maintenance cost will be lower over the lifetime of your product.
This approach is not free. Working upstream takes effort, features need to be discussed and specced out in public before work begins to ensure that you are taking an approach which will be accepted. Patches need to be broken down into easy to consume chunks. Relationships need to be built with the upstream maintainers, so that your needs are taken into account by the entire community. You will be developing your features on a fast-moving code base, which will make testing and stabilization harder. All told, developing a feature this way may take about twice the time and effort it would just to develop it in private, off a stable release, on a vendor branch.
But the pay-off is huge – once the code is accepted into the upstream source tree, it will be included in future stable releases. The maintenance work will be shared by the community. And by working upstream as part of the community, you make it more likely that future work will also be well received, and you get a real voice in defining the future priorities for the project. This is the way upstream developers work, and there is a reason for it. “Release early, release often” is a mantra in open source because it has been proven to be a successful engagement model, and a good way to build successful community projects.
Community innovation
This is the way Red Hat works. Working with open source is more than a cultural imperative at Red Hat. We see it as a better way to build products.
Commitment to working upstream is a fundamental building block of Red Hat's business. We work with upstream projects to innovate, and provide a stable, certified experience to customers and partners by integrating multiple projects into our products. In the community projects we lead and participate in, we encourage people to participate, defining the direction and priorities for future releases of our products.
Red Hat is active in all of the projects which make up the OPNFV platform. We are not only delivering open source projects, we are present, helping to define the future open source NFV platform. That's the kind of partner you need when deploying an OpenStack based NFV platform.
Sobre o autor
Dave Neary has been active in free and open source communities for more than 15 years as a consultant, community manager, trainer and developer. In that time, he has worked on advising companies in finance and telecommunications industry on effective adoption of, and participation in, open source projects.
Mais como este
Por que o aumento das vulnerabilidades de segurança impulsionadas pela IA exige a atuação técnica de especialistas
Avanço dos recursos pós-quânticos de SSH no Red Hat Enterprise Linux
Untangling Networks | Compiler
Technically Speaking | Defining sovereign AI with open source
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem