
A couple years ago, a few big companies began to run Spark and Hadoop analytics clusters using shared Ceph object storage to augment and/or replace HDFS.
We set out to find out why they were doing it and how it performs.
Specifically, we wanted to know first-hand answers to the following three questions:
- Why would companies do this? (this blog post)
- Will mainstream analytics jobs run directly against a Ceph object store? (see "Why Spark on Ceph? (Part 2 of 3)")
- How much slower will it run than natively on HDFS? (see "Why Spark on Ceph? (Part 3 of 3)")
We’ll provide summary-level answers to these questions in a 3-part blog series. In addition, for those wanting more depth, we’ll cross-link to a separate reference architecture blog series providing detailed descriptions, test data, and configuration scenarios, and we recorded this podcast with Intel, in which we talk about our focus on making Spark, Hadoop, and Ceph work better on Intel hardware and helping enterprises scale efficiently.
Part 1: Why would companies do this?
Agility of many, the power of one.
The agility of many analytics clusters, with the power of one shared data store.
(Ok ... enough with the simplistic couplets.)
Here are a few common problems that emerged from speaking with 30+ companies:
- Teams that share the same analytics cluster are frequently frustrated because someone else’s job often prevents their job from finishing on-time.
- In addition, some teams want the stability of older analytic tool versions on their clusters, while their peer teams need to load the latest-and-greatest tool releases.
- As a result, many teams demand their own separate analytics cluster so their jobs aren’t competing for resources with other teams, and so they can tailor their cluster to their own needs.
- However, each separate analytics cluster typically has its own, non-shared HDFS data store - creating data silos.
- And to provide access to the same data sets across the silos, the data platform team frequently copies datasets between the HDFS silos, trying to keep them consistent and up-to-date.
- As a result, companies end up maintaining many separate, fixed analytics clusters (50+ in one case), each with their own HDFS data silo containing redundant copies of PBs of data, while maintaining an error-prone maze of scripts to keep data sets updated across silos.
- But, the resulting cost of maintaining 5, 10, or 20 copies of multi-PB datasets on the various HDFS silos is cost prohibitive to many companies (both CapEx and OpEx).
In pictures, their core problems and resulting options look something like this:
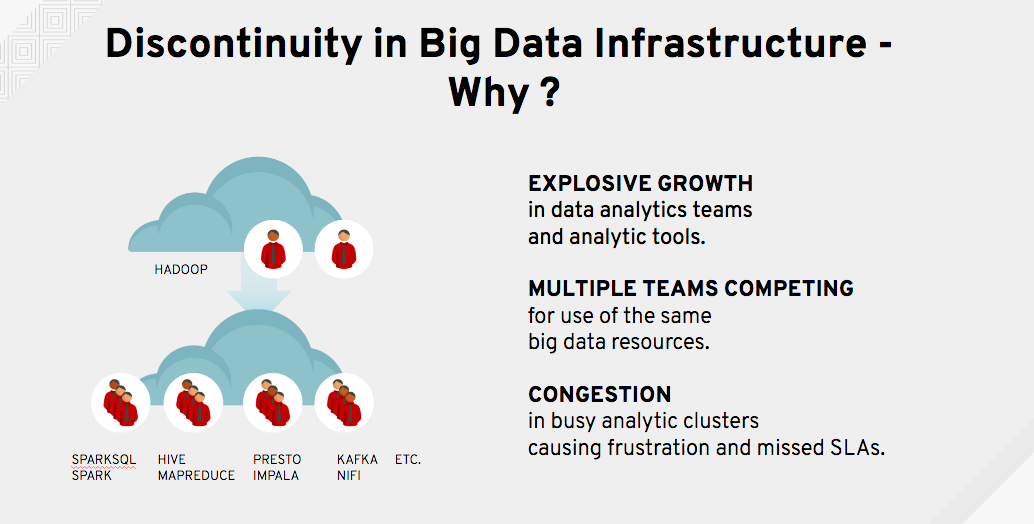 Figure 1. Core problems
Figure 1. Core problems
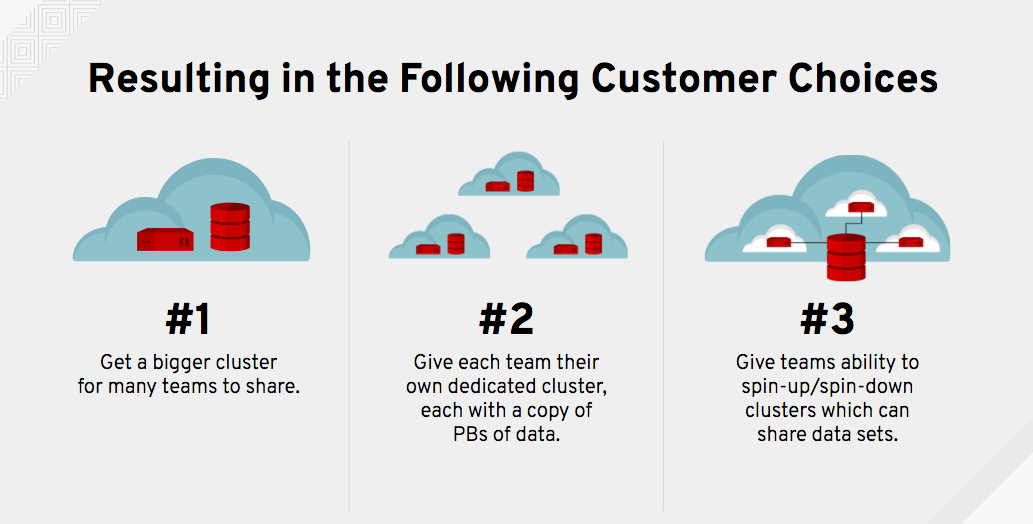 Figure 2. Resulting Options
Figure 2. Resulting Options
Turns out that the AWS ecosystem built a solution for choice #3 (see Figure 2 above) years ago through the Hadoop S3A filesystem client. In AWS, you can spin-up many analytics clusters on EC2 instances, and share data sets between them on Amazon S3 (e.g. see Cloudera CDH support for Amazon S3). No more lengthy delays hydrating HDFS storage after spinning-up new clusters, or de-staging HDFS data upon cluster termination. With the Hadoop S3A filesystem client, Spark/Hadoop jobs and queries can run directly against data held within a shared S3 data store.
Bottom-line ... more-and-more data scientists and analysts are accustomed to spinning-up analytic clusters quickly on AWS with access to shared data sets, without time-consuming HDFS data-hydration and de-stage cyles, and expect the same capability on-premises.
Ceph is the #1 open-source, private-cloud object storage platform, providing S3-compatible object storage. It was (and is) the natural choice for these companies looking to provide an S3-compatible shared data lake experience to their analysts on-premises.
To learn more, continue to the next post in this series, "Why Spark on Ceph? (Part 2 of 3)": Will mainstream analytics jobs run directly against a Ceph object store?
Sobre o autor
Mais como este
A nova moeda da velocidade empresarial
Por que agentes de IA são a evolução das aplicações
Container Roundup | Compiler
Untangling Networks | Compiler
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem