-
Soluções e documentação Red Hat AI
Uma plataforma de soluções e serviços para desenvolvimento e implantação de IA na nuvem híbrida.
Red Hat AI Enterprise
Crie, desenvolva e implante aplicações com tecnologia de IA na nuvem híbrida.
Red Hat AI Inference Server
Otimize o desempenho do modelo com o vLLM e realize inferências de forma mais rápida, econômica e em escala.
Red Hat Enterprise Linux AI
Desenvolva, teste e execute modelos de IA generativa com recursos de inferência otimizados.
Red Hat OpenShift AI
Crie e implante modelos e aplicações com IA em escala em ambientes híbridos.
-
Aprenda Básico
-
Parceiros de IA
A importância da inferência de IA
Não existe IA sem inferência.
A inferência é a base da IA generativa. No entanto, quando grandes modelos precisam executar estratégias ainda maiores, as coisas ficam complicadas.
É por isso que detalhamos os desafios e as oportunidades associados à inferência de IA, desde a otimização de modelos com vLLM até os frameworks distribuídos open source mais recentes, como o llm-d.
Por que a inferência é tão importante?
A inferência é a etapa final de um processo longo e complexo de machine learning, quando um modelo gera o resultado desejado.
Ela é uma função essencial para o sucesso de uma IA.
Por isso, o hardware e o software que viabilizam a inferência podem determinar o sucesso ou o fracasso da sua estratégia de IA.

O que está limitando sua capacidade de escalar?
Modelos em constante crescimento aumentam os requisitos da inferência. Conforme os modelos ficam mais complexos, a inferência tende a ficar mais lenta.
Para a inferência ser bem-sucedida, os modelos de IA exigem um alto volume de processamento em pouco tempo. Portanto, o tamanho do modelo, o alto volume de acessos e as exigências de latência são fatores que podem limitar o desempenho.
Com o aumento da demanda por dados e memória, o hardware e os aceleradores passam a enfrentar limitações de desempenho.
66%
dos recursos de computação de IA devem ser consumidos pela inferência em 2026, ante 33% em 2023 e 50% em 2025.1
Como aprimorar a inferência de IA?
Ao otimizar a inferência, é possível executar modelos de IA com mais rapidez e inteligência.
Os métodos de otimização incluem o uso mais eficiente de GPUs, decodificação especulativa, esparsidade, compressão de modelos com quantização e inferência distribuída.
Ferramentas como o LLM Compressor aproveitam os avanços mais recentes em compressão de modelos para tornar os LLMs menores, mais rápidos e energeticamente eficientes. Isso reduz os requisitos de hardware e melhora a eficácia, sem sacrificar a precisão.
Otimizações como essas ajudam a manter a inferência de IA com custo eficiente, permitindo que ela escale à medida que suas equipes evoluem.
+ de 99%
de precisão mantida durante as otimizações com o compressor de LLM.2

2x
mais capacidade de processamento com modelos comprimidos, sem comprometer a precisão.3
50%
de economia sem sacrificar o desempenho ao otimizar modelos com o compressor de LLM.4

Como o vLLM otimiza a inferência?
Otimizar os modelos é só parte do problema. Você também precisa de um mecanismo de inferência de alto desempenho. É aí que o vLLM pode ajudar.
Os sistemas tradicionais de gerenciamento de memória para LLMs não organizam os recursos de forma eficiente, o que afeta o desempenho. O vLLM utiliza o PagedAttention, técnica que identifica valores de chave repetidos para eliminar o processamento redundante.
Isso permite que o vLLM faça um uso melhor da memória da GPU e acelere a inferência de IA generativa. Ele amplia a taxa de processamento, medida em tokens processados por segundo, para atender vários usuários simultaneamente.
O uso mais eficiente de aceleradores permite que os modelos executem mais cálculos em menos tempo, ampliando a capacidade de atender mais usuários e agentes.
50%
menos parâmetros com o uso de estruturas de esparsidade.5

2,1x
menos latência de inferência com técnicas de decodificação especulativa.6
24x
mais desempenho de processamento com o vLLM em comparação aos concorrentes.7
Por que o vLLM está tão em alta?
O vLLM ajudou a responder aos principais desafios de utilização eficiente das GPUs, reduzindo o custo por token e oferecendo latência estável em grande escala. Tudo isso com uma implantação portátil e aberta.
Por isso a comunidade do vLLM é tão ativa e dinâmica. As contribuições surgem de grupos engajados como o Hugging Face, UC Berkeley, NVIDIA, Red Hat e muitos outros. A comunidade testa continuamente os limites do software e o aprimora no projeto open source.
Com suporte de Dia 0 para todos os principais modelos e aceleradores, sua acessibilidade é interessante para os setores empresariais e acadêmicos.
+ de 10 mil
commits* do vLLM no GitHub (um aumento de mais de 200%) em 2025.
A comunidade do vLLM hoje
+ de 500 mil
GPUs implantadas em tempo integral8
+ de 200
tipos de aceleradores9
+ de 500
modelos de arquitetura compatíveis9
+ de 2 mil
colaboradores exclusivos do vLLM9
Qual é o papel da inferência distribuída?
A inferência distribuída permite que modelos de IA dividam a execução da inferência entre um conjunto de dispositivos interconectados.
Quando um modelo consegue atender diferentes solicitações ao mesmo tempo, reduz significativamente a necessidade de hardware e aumenta a eficiência da inferência.
A inferência distribuída usa técnicas como paralelismo de tensores, programação inteligente de inferência e desagregação. Quando combinado ao vLLM, a inferência se torna altamente eficiente e capaz de lidar com múltiplas tarefas simultaneamente.
Isso ajuda a mantê-la observável, escalável e consistente.
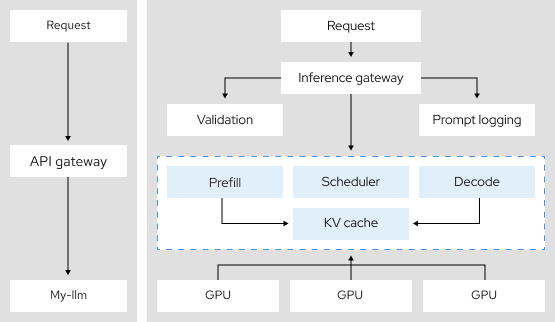
3,9x
mais desempenho no processamento de tokens usando o paralelismo de tensores, um tipo de arquitetura de inferência distribuída.10
Existe uma comunidade open source para isso?
Sim, e é chamada de llm-d.
O llm-d é um framework open source que oferece aos desenvolvedores um modelo para criar inferência distribuída em grande escala.
Sua arquitetura modular atende às demandas complexas de recursos de LLMs avançados e substitui processos manuais e fragmentados por fluxos integrados e bem definidos, reduzindo o tempo entre o piloto e a produção.
O llm-d traz a inferência para o Kubernetes, oferecendo ferramentas padronizadas para aplicar a inferência distribuída aos seus casos de uso empresariais exclusivos.
2x
mais consultas por segundo (QPS) sustentadas pelo llm-d em relação à linha de base.11
Mais recursos de IA
Red Hat AI Inference
Acelere a implantação dos seus LLMs em produção.
Baseado no vLLM, nosso mecanismo de inferência empresarial oferece mais velocidade sem afetar o desempenho.
Escale na nuvem híbrida com o modelo de gen AI otimizado de sua preferência, em qualquer acelerador de IA e em qualquer ambiente de nuvem.

Fontes citadas
[1] “Why AI’s Next Phase Will Likely Demand More Computing Power—Not Less .” The Wall Street Journal, 22 de janeiro de 2026.
[2] Kurtić, Eldar, et al. “We ran over half a million evaluations on quantized LLMs—here's what we found.”, Blog Red Hat Developer, 17 de outubro de 2024.
[3] Condado, Carlos. “Inferência de IA: uma abordagem estratégica para o desempenho”, Blog da Red Hat, 15 de setembro de 2025.
[4] Zelenović, Saša. “Aproveite todo o potencial dos LLMs: otimize o desempenho com vLLM.”, Blog da Red Hat, 27 de fevereiro de 2025.
[5] Kurtić, Eldar, et al. “2:4 Sparse Llama: Smaller models for efficient GPU inference.”, Blog Red Hat Developer , 28 de fevereiro de 2025.
[6] Marques, Alexandre, et al. “Fly Eagle(3) fly: Faster inference with vLLM & speculative decoding.”, Blog Red Hat Developer, 1 de julho de 2025.
[7] Kwon, Woosuk, et al. “vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention.” Blog do vLLM, 20 de junho de 2023.
[8] Goin, Michael. “[vLLM Office Hours #38] vLLM 2025 Retrospective & 2026 Roadmap - December 18, 2025.”, YouTube, 8 de dezembro de 2025.
[9] Kwon, Woosuk. “Today, vLLM supports 500+ model architectures, runs on 200+ accelerator types, and powers inference at global scale.”, X, 26 de janeiro de 2026.
[10] Goin, Michael. “Distributed inference with vLLM.”, Red Hat Developer, 6 de fevereiro de 2025.
[11] Shaw, Robert. “llm-d: Kubernetes-native distributed inferencing.”, Red Hat Developers, 20 de maio de 2025.