Estamos percebendo uma tendência significativa: mais organizações estão adotando a infraestrutura de Large Language Models (LLM) internamente. Seja por motivos de latência, conformidade ou privacidade de dados, a auto-hospedagem com modelos open source em seu próprio hardware coloca você no controle da sua jornada de IA. No entanto, escalar LLMs de experimentação para um serviço de nível de produção apresenta complexidade e custos significativos.
Um novo framework open source, o llm-d, amparado por uma poderosa rede de colaboradores como a Red Hat, a IBM e o Google, foi projetado para enfrentar esses desafios. Ele vai direto à raiz do problema: a inferência de IA, o processo em que seu modelo gera resultados para prompts, agentes, Geração Aumentada de Recuperação (RAG) e muito mais.
Por meio de decisões inteligentes de agendamento (desagregação) e padrões de roteamento específicos para IA, o llm-d possibilita uma distribuição dinâmica e inteligente de cargas de trabalho para modelos de linguagem (LLMs). Por que isso é tão importante? Vamos descobrir como o llm-d funciona e como ele pode reduzir os custos com a IA e melhorar o desempenho.
O desafio para escalar a inferência do LLM
Escalar serviços web tradicionais em plataformas como o Kubernetes segue padrões já estabelecidos. Em geral, as solicitações HTTP padrão são rápidas, uniformes e stateless. No entanto, escalar a inferência de LLM é um desafio diferente.
Um dos principais motivos para isso é a alta variação nas características de solicitação. Um padrão de RAG pode, por exemplo, usar um prompt de entrada longo empacotado com contexto de um banco de dados vetorial para gerar uma resposta curta de uma frase. De outra forma, uma tarefa de raciocínio pode começar com um prompt curto e produzir uma resposta longa e com várias etapas. Essa variação cria cargas desbalanceadas que podem prejudicar o desempenho e aumentar a latência de cauda (ITL). A inferência de LLM também depende muito do cache de chave-valor (KV), o qual é a memória de curto prazo de um LLM, para armazenar resultados intermediários. O balanceamento de carga tradicional desconhece o estado desse cache, o que leva a um encaminhamento ineficiente de solicitações e recursos de computação subutilizados.

Com o Kubernetes, a abordagem atual tem sido implantar LLMs como containers monolíticos, ou seja, grandes caixas pretas sem visibilidade ou controle. Isso compromete o escalonamento eficaz, além de ignorar a estrutura de prompt, a contagem de tokens, as metas de latência de resposta (objetivos de nível de serviço ou SLO), a disponibilidade de cache, entre outros fatores.
Em resumo, nossos sistemas de inferência atuais são ineficientes e usam mais recursos de computação do que o necessário.
O llm-d está deixando a inferência mais eficiente e econômica
Enquanto o vLLM oferece amplo suporte a modelos em uma grande variedade de hardwares, o llm-d vai além. Com base nas infraestruturas de TI empresariais existentes, o llm-d oferece recursos de inferência distribuídos e avançados para economizar recursos e melhorar o desempenho, com aceleração de até três vezes no tempo do primeiro token e taxas de transferência dobradas mesmo sob restrições de latência (SLO). Embora ofereça um conjunto poderoso de inovações, o foco principal do llm-d são duas inovações que ajudam a melhorar a inferência:
- Desagregação: ao desagregar o processo, é possível usar os aceleradores de hardware com mais eficiência durante a inferência. Isso envolve a separação do processamento de prompts (fase de preenchimento prévio) da geração de tokens (fase de decodificação) em cargas de trabalho individuais, chamadas pods. Essa separação permite o escalonamento e a otimização independentes de cada fase, já que elas têm diferentes demandas computacionais.
- Camada de agendamento inteligente: estende a API Kubernetes Gateway, para permitir decisões de roteamento mais sutis nas solicitações de entrada. Ela aproveita dados em tempo real, como a utilização do cache de chave-valor e o carregamento do pod, para direcionar solicitações para a instância ideal, maximizando ocorrências em cache e equilibrando a carga de trabalho no cluster.

Além de funcionalidades como o armazenamento em cache de pares de chave-valor entre solicitações para evitar a recomputação, o llm-d divide a inferência do LLM em serviços modulares e inteligentes para oferecer um desempenho escalável (e aproveita o amplo suporte que o próprio vLLM oferece). Vamos nos aprofundar um pouco em cada uma dessas tecnologias e saber como elas funcionam no llm-d, com alguns exemplos práticos.
Como a desagregação aumenta a taxa de transferência com latência reduzida
A principal diferença entre as fases de preenchimento prévio e decodificação da inferência do LLM apresenta um desafio para a alocação uniforme de recursos. A fase de preenchimento prévio, que processa o prompt de entrada, de modo geral, é limitada à computação e requer alto poder de processamento para criar as entradas iniciais de cache de chave-valor. Por outro lado, a fase de decodificação, na qual os tokens são gerados um por um, está geralmente limitada à largura de banda da memória, envolvendo sobretudo a leitura e a gravação no cache de chave-valor com menos computação.
Ao implementar a desagregação, o llm-d permite que esses dois perfis diferentes de computação sejam atendidos por pods separados do Kubernetes. Isso significa que você pode provisionar pods de preenchimento prévio com recursos otimizados para tarefas de alta demanda computacional e decodificar pods com configurações personalizadas para eficiência de largura de banda da memória.
Como funciona o gateway de inferência com reconhecimento de LLM
No centro dos avanços de desempenho do llm-d está o roteador de agendamento inteligente, responsável por orquestrar onde e como as solicitações de inferência são processadas. Quando uma solicitação de inferência chega ao gateway llm-d (baseado em kgateway), ela não é simplesmente encaminhada para o próximo pod disponível. Em vez disso, o seletor de endpoints (EPP), um componente principal do scheduler do llm-d, avalia vários fatores em tempo real para determinar o destino ideal:
- Reconhecimento do cache de chave-valor: o scheduler mantém um índice do status em todas as réplicas do vLLM em execução. Se uma nova solicitação compartilhar um prefixo comum com uma sessão já armazenada em cache em um pod específico, o scheduler priorizará o roteamento para esse pod. Isso aumenta de maneira significativa as taxas de ocorrência do cache, evitando cálculos redundantes de pré-preenchimento e reduzindo diretamente a latência.
- Reconhecimento de carga: além da simples contagem de solicitações, o scheduler avalia a carga real em cada pod do vLLM, considerando a utilização de memória da GPU e as filas de processamento, ajudando a evitar obstáculos.
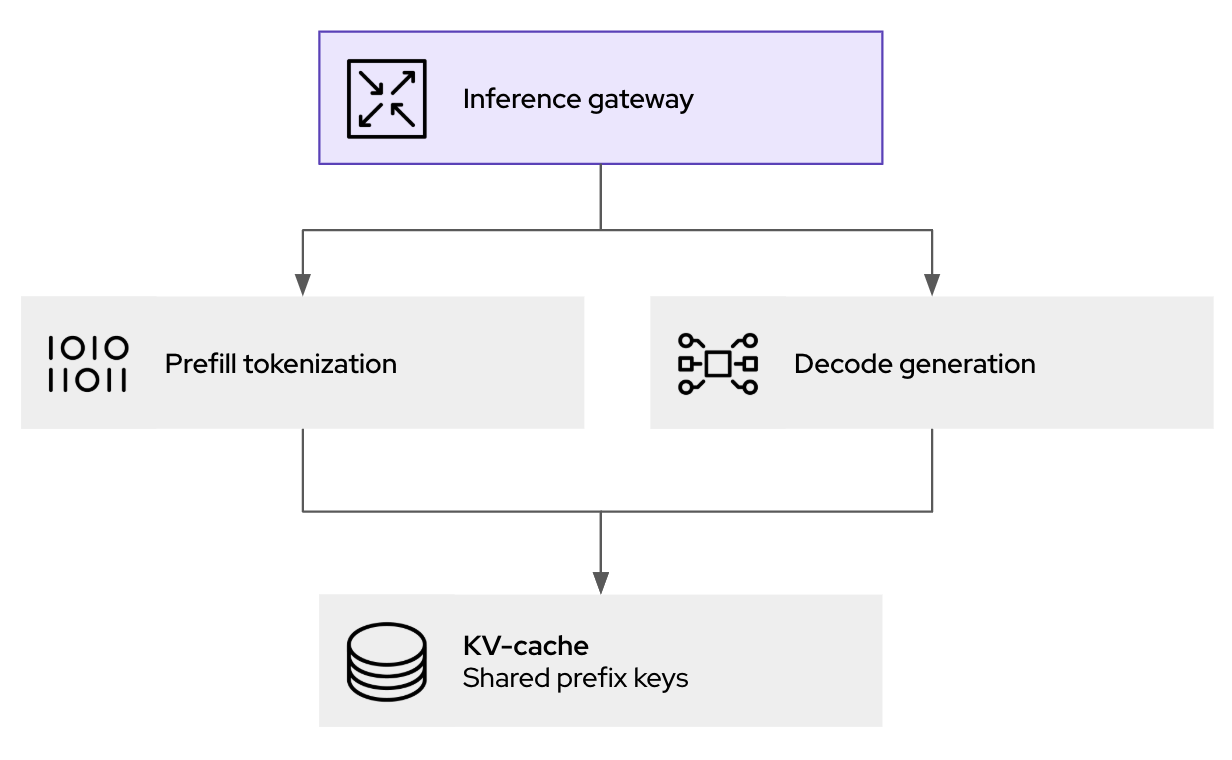
Essa abordagem nativa do Kubernetes oferece a camada de política, segurança e observabilidade para inferência de IA generativa. Isso não apenas ajuda a lidar com o tráfego, mas também possibilita auditoria e geração de logs (para governança e conformidade), bem como medidas de proteção antes de encaminhar para inferência.
Veja por onde começar com o llm-d
O projeto do llm-d envolve uma energia inspiradora. Enquanto o vLLM é ideal para configurações de servidor único, o llm-d foi criado para o operador que gerencia um cluster, visando uma inferência de IA econômica e de alto desempenho. Quer descobrir mais por conta própria? Confira o repositório llm-d no GitHub e participe da conversa no Slack. É um ótimo lugar para se envolver mais e fazer perguntas.
O futuro da IA está sendo construído a partir de princípios open source e colaborativos. Com comunidades como o vLLM e projetos como o llm-d, a Red Hat trabalha para tornar a IA mais acessível, rentável e potente para desenvolvedores de todos os lugares.
Recurso
Introdução à IA empresarial: um guia para iniciantes
Sobre os autores

Cedric Clyburn (@cedricclyburn), Senior Developer Advocate at Red Hat, is an enthusiastic software technologist with a background in Kubernetes, DevOps, and container tools. He has experience speaking and organizing conferences including DevNexus, WeAreDevelopers, The Linux Foundation, KCD NYC, and more. Cedric loves all things open-source, and works to make developer's lives easier! Based out of New York.

Christopher Nuland is a Principal Technical Marketing Manager for AI at Red Hat and has been with the company for over six years. Before Red Hat, he focused on machine learning and big data analytics for companies in the finance and agriculture sectors. Once coming to Red Hat, he specialized in cloud native migrations, metrics-driven transformations, and the deployment and management of modern AI platforms as a Senior Architect for Red Hat’s consulting services, working almost exclusively with Fortune 50 companies until recently moving into his current role. Christopher has spoken worldwide on AI at conferences like IBM Think, KubeCon EU/US, and Red Hat’s Summit events.
Mais como este
The subject matter expert advantage in the AI era
Innovating at the tactical edge: Red Hat at Exercise: HEIMDALL
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem