A adoção e o desenvolvimento da IA aceleraram com a popularização da IA generativa e dos agentes de IA. Com o surgimento de novos mercados, as empresas têm enfrentado dificuldades para aproveitar as vantagens da IA e obter retornos reais sobre o investimento. Embora as GPUs tenham dominado a infraestrutura, o aumento dos custos e a diminuição da disponibilidade devido à demanda levaram os líderes a buscar alternativas que ainda atendam aos requisitos de desempenho e aos padrões de satisfação do cliente.
Enquanto isso, os desenvolvedores e engenheiros que trabalham com a IA enfrentam desafios na configuração de infraestruturas complexas e demoradas, além de dificuldades para criar stacks e arquiteturas de software para uma inferência de Large Language Model (LLM) ideal com geração aumentada de recuperação (RAG). Facilidade de uso, segurança de dados proprietários e até mesmo como começar a criar IA são desafios técnicos que podem impedir os desenvolvedores de entrar na IA.
A colaboração entre a Intel e a Red Hat combina o desempenho das CPUs Xeon com a escalabilidade do Red Hat OpenShift AI, oferecendo uma base protegida e flexível para a implantação de agentes de IA na empresa. Nessa plataforma, os clientes podem criar modelos e aplicações de IA e machine learning com mais segurança e em escala nos ambientes de nuvem híbrida.
Para simplificar o processo de adoção, a Intel criou vários guias de início rápido sobre IA. Os guias de início rápido de IA são exemplos de casos de uso empresariais reais que podem ser implantados rapidamente no Xeon com OpenShift, acelerando o desenvolvimento e o time to market. Esses guias de início rápido estão disponíveis no catálogo AI quickstarts (guias de início rápido de IA).
Por que usar IA no Xeon?
Embora as GPUs tenham dominado o deep learning, a IA generativa e os agentes de IA, a inferência pode usar plataformas de computação menores e mais econômicas para atender aos requisitos funcionais e de desempenho. As CPUs têm sido historicamente a plataforma escolhida para processamento de dados, análise de dados e machine learning clássico. Isso inclui regressão, classificação, clusterização e árvores de decisão usando métodos como máquinas de vetores de suporte, XGBoost e K-means. Os casos de uso incluem previsão financeira e de varejo, detecção de fraudes e otimização da cadeia de suprimentos. Isso ajuda a gerenciar os custos da infraestrutura de IA a longo prazo. O Intel Xeon está bem posicionado como nó principal para esse tipo de plataforma menor.
Funcionalidades de hardware do Intel Xeon
Os recursos de hardware são o que distinguem o Xeon como uma plataforma de CPU viável para IA. As extensões avançadas de matriz (AMX) do conjunto de instruções e a alta largura de banda de memória com módulos de memória em linha dual de classificação multiplexada (MRDIMMs) são os componentes mais proeminentes que diferenciam o Xeon.
O AMX foi introduzido na 4ª geração de processadores escaláveis Intel® Xeon® como um acelerador de IA integrado, um bloco de hardware dedicado nos núcleos, para realizar matemática de matrizes em vez de depender de um acelerador discreto. Ele é compatível com tipos de dados de precisão mais baixa, incluindo Bfloat16 (BF16) e INT8. Um grande benefício do BF16 é melhorar o desempenho sem sacrificar a precisão em comparação com o FP32. As acelerações com o AMX reduzem a utilização de energia e recursos, além de reduzir o tempo de desenvolvimento com suas otimizações upstream para frameworks de IA, incluindo PyTorch e TensorFlow.
Sistemas de recomendação, processamento de linguagem natural, IA generativa, agentes de IA e casos de uso de visão computacional são todos os benefícios do AMX resultando em maior valor para o usuário final e para os negócios.

Figura 1: O Intel® AMX apresenta blocos de registro 2D com instruções de multiplicação de matrizes de blocos TMUL para calcular grandes matrizes em uma única operação.
Na inferência de IA e LLM, o gargalo de memória é o cache de chave-valor (KV) de alta demanda de memória. O MRDIMMS resolve isso mudando a complexidade computacional de quadrática para linear, oferecendo uma largura de banda de memória 37% maior do que os RDIMMs. Isso melhora o rendimento da memória e reduz a latência ao lidar com tarefas com uso intensivo de dados durante a inferência de IA. Em sistemas onde a memória da GPU é limitada, as CPUs do Xeon podem descarregar dados do KV, liberando recursos caros da GPU e mantendo o alto desempenho.
O Xeon tem vários casos de uso práticos em IA, como inferência, RAG e processamento de dados seguro e agentes de IA. O Xeon é uma plataforma funcional e de alto desempenho com software de suporte para atender às necessidades de IA sem a necessidade de GPUs.
Caso de uso 1 do Xeon: inferência de IA
A inferência de LLM capacita aplicações, incluindo chatbots empresariais, resumo de documentos, assistentes de código e pipelines de RAG. Empresas de todos os tamanhos e organizações que buscam IA generativa econômica sem grandes investimentos em GPU podem encontrar no Xeon uma opção mais prática. O Xeon é executado melhor com LLMs pequenos a médios e mistura de especialistas (MOEs) de até 13 bilhões de parâmetros. Ao mesmo tempo, ele atende a padrões como time-to-first-token (TTFT) de três segundos e time-per-output-token de 100 ms.
A Intel tem trabalhado em estreita colaboração com a comunidade open source para otimizar a inferência de IA, incluindo o vLLM e o SGLang. O vLLM é um engine de serviço de inferência para alta capacidade e eficiência de memória. O dashboard do vLLM para o Xeon no Pytorch.org contém números de desempenho publicados de LLMs conhecidos, incluindo Llama-3.1-8B-Instruct no Xeon. A Intel continua aprimorando o desempenho e adicionando suporte a uma lista de modelos validados. O SGLang é outro framework de serviço rápido que a Intel está trabalhando para integrar ao Xeon.
O Xeon também é compatível com a inferência de LLM distribuído com o llm-d, em que os estágios de pré-preenchimento e decodificação são divididos em vários nós para maior escalabilidade. O llm-d é um framework open source do Kubernetes que acelera a inferência de LLM distribuído em escala.
Caso de uso 2 do Xeon: A RAG e o processamento seguro de dados
A RAG é eficaz para obter saídas precisas de LLMs sem retreinar modelos. A base de conhecimento é criada com a preparação dos dados usando análise de documentos, fragmentação e extração de metadados para criar embeddings armazenados em um banco de dados vetorial. Todas as operações podem ser feitas de forma segura com as Intel® Trust Domain Extensions (TDX), uma tecnologia de computação confidencial baseada em hardware. O TDX usa máquinas virtuais (VMs) isoladas de hardware para proteger dados e aplicações contra acessos não autorizados. Isso permite que as empresas aproveitem rapidamente os dados proprietários disponíveis para automação do suporte ao cliente, recuperação de documentos e pesquisa jurídica. A latência de recuperação é baixa, e as consultas simultâneas podem ser tratadas com o Xeon.

Figura 2: O Intel® TDX usa extensões de hardware para gerenciar e criptografar a memória, a fim de proteger a confidencialidade e a integridade dos dados.
Caso de uso do Xeon 3: Agentes de IA
Os agentes de IA seguem uma lógica sequencial de planejamento, ação, observação e reflexão. Ele usa uma carga de trabalho mista que envolve inferência de LLM e execução de ferramentas, desde consultas ao banco de dados, chamadas de API e acesso a arquivos. O Xeon é compatível com servidores de protocolo de contexto de modelo (MCP), APIs LlamaStack agentic, LangChain e frameworks CrewAI. Automação de operações de TI, suporte a decisões financeiras e agentes da cadeia de suprimentos são casos de uso de negócios desejados.
Xeon no OpenShift: Novidades
O Red Hat OpenShift AI é uma plataforma de IA de nível empresarial para gerenciar todo o ciclo de vida da criação, treinamento e implantação de modelos e aplicações de IA em escala na nuvem híbrida, em ambientes on-premise e de edge. Entre as tecnologias incluídas no OpenShift AI, o vLLM oferece modelos otimizados de baixa latência e alta taxa de transferência, além de reduzir os custos de hardware. Há uma coleção de modelos de terceiros otimizados, prontos para produção e validados que oferece às equipes de desenvolvimento mais controle sobre a acessibilidade e visibilidade do modelo para atender aos requisitos de segurança e políticas. Tudo isso pode ser implantado automaticamente com ferramentas avançadas para iniciar seus projetos de IA e reduzir a complexidade operacional. Em geral, as aplicações de IA podem ser colocadas em produção em escala com mais rapidez.
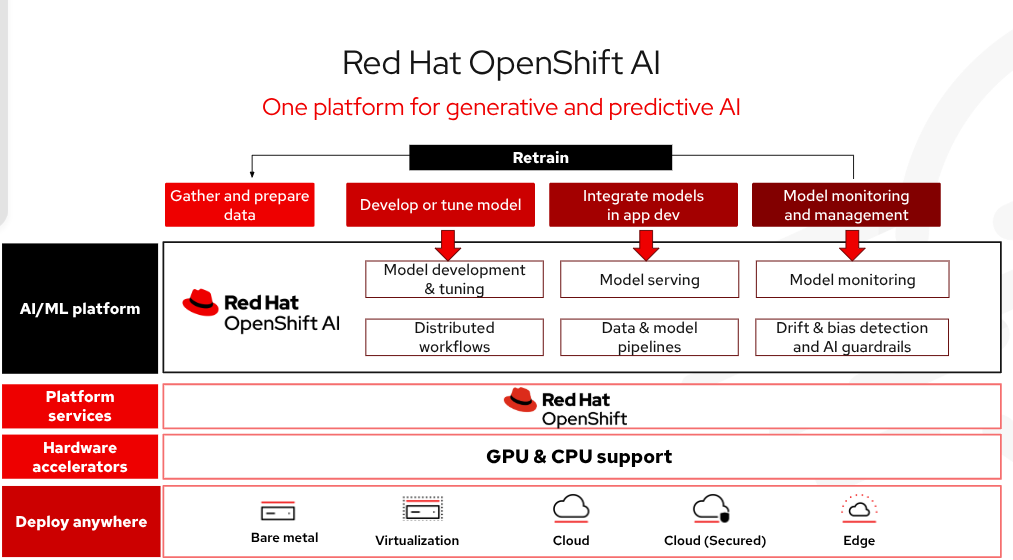
Figura 3: O Red Hat OpenShift AI é uma plataforma flexível e escalável de inteligência artificial (IA) e machine learning (ML) que permite às empresas criar e entregar aplicações com IA em escala nos ambientes de nuvem híbrida.
Funcionalidades
O gerenciamento da infraestrutura de IA levará menos tempo, pois modelos de alto desempenho poderão ser facilmente implantados com Modelos como Serviço (MaaS) e acessados por endpoints de API. Há flexibilidade em toda a nuvem híbrida, como software autogerenciado flexível e protegido em bare metal, ambientes virtuais ou todas as principais plataformas de nuvem pública. A Red Hat testou e integrou ferramentas open source comuns de IA/ML e modelo de serviço para ser fácil para os desenvolvedores usá-las. O OpenShift AI também inclui o llm-d, um framework open source para inferência de IA distribuída em escala.
Imagem de CPU do vLLM
A Intel disponibilizou uma imagem vLLM para CPU no Dockerhub, criada com base na imagem base universal da Red Hat. A imagem é criada com o AMX habilitado. Portanto, os processadores 4th Gen Xeon® Scalable® ou mais recentes são necessários para executar esta imagem. Agora, muitos modelos open source podem ser implantados rapidamente e executar inferências com alto rendimento e baixa latência.
AI quickstarts (guias de início rápido de IA)
No catálogo AI quickstarts (guias de início rápido de IA) no site redhat.com, você encontra exemplos de casos de uso empresariais prontos para execução que executam modelos de maneira ideal com o vLLM no Xeon, com tecnologia do OpenShift AI. Os desenvolvedores podem usar esses exemplos como ponto de partida e personalizar de acordo com as necessidades ou usar como estão. Os primeiros rascunhos de vários guias de início rápido de IA estão disponíveis no GitHub e são executados no Xeon de maneira pronta. Todos os guias de início rápido finalizados foram lançados no catálogo AI quickstarts.
- LlamaStack MCP Server: implanta LLMs com vLLM com servidores MCP, como previsão do tempo e ferramentas de RH
- LLM CPU Serving: um assistente de chat leve e estratégico para liderança e estratégia de IA que atende a um pequeno modelo de linguagem
- RAG: Use a geração aumentada de recuperação para aprimorar LLMs com fontes de dados especializadas e gerar respostas mais precisas e contextualizadas
- vLLM Tool Calling: implanta LLMs usando vLLM com chamada de função
Próximas etapas
IA para o Xeon é facilitada com o Red Hat OpenShift AI. O ambiente gerenciado e protegido configura a infraestrutura de IA necessária para o desenvolvimento, a implantação e a observabilidade.
- Consulte o dashboard do vLLM para Xeon para ver números de desempenho e a documentação do vLLM para compilar/fazer o download de imagens do vLLM para CPU com suporte ao AMX.
- Use o vLLM para CPU com base no Red Hat Universal Base Image do DockerHub.
- Confira a lista de modelos compatíveis do Xeon.
- Explore o catálogo AI quickstarts para ver exemplos prontos para execução e visite o GitHub de início rápido de IA para ver inícios rápidos de IA que ainda estão em desenvolvimento.
- Visite o site do Red Hat OpenShift AI.
Produto
Red Hat AI
Sobre o autor

Mais como este
Pare de gerenciar o passado e comece a construir o futuro da TI
O próximo ponto de inflexão da IA: transformando agentes em superusuários corporativos
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem