Red Hat Advanced Cluster Management for Kubernetes allows you to deploy, upgrade, and configure different Spoke clusters from a Hub cluster; essentially, it is an Openshift cluster that manages other clusters. This article demonstrates how to use Red Hat Advanced Cluster Management and the associated governance model to manage configuration and policies of your clusters, with exceptions on some specific clusters.
In a previous article, I focused on subgroups instead of exceptions. Read it for context and a better understanding on how Red Hat Advanced Cluster Management and Zero-Touch Provisioning (ZTP) work. Basic knowledge of these technologies is required to follow along with this article.
Policy Templates
PolicyGenTemplates (PGT) eases the definition of the Policies that manage the configuration of your infrastructure. A PolicyGenTemplate defines a set of configurations and policies. These are linked to different clusters:
apiVersion: ran.openshift.io/v1 kind: PolicyGenTemplate metadata: name: "group-du-sno" namespace: "ztp-group" spec: bindingRules: group-du-sno: "" <CONFIGURATIONS/POLICIES>
You can use a PGT to ease creation of Red Hat Advanced Cluster Management Policies, and to manage all the different configurations of your infrastructure. In this example, all the clusters with the group-du-sno:"" label are affected by policies generated by this PGT.
But what happens when you need to make exceptions? What if a cluster that logically belongs to that group needs to be configured exceptionally? The objective of this article is to be able to set exceptions, but making the cluster still belong to its logical groups. Also, the exceptional behavior of that cluster can be reverted.
Here are some differences in this article compared to my previous article:
- Instead of creating subgroups of clusters, I set some exceptions on configurations
- Instead of using Advanced Cluster Management Policies, I use ZTP PGTs
- Instead of a Canary rollout, the exceptional cluster is reverted to the default configuration of the group when the new configuration is tested. In my previous post, I did this the other way around, moving all the other clusters to the new tested configuration
This example isn’t to show that one way is better than the other. Whether you work with subgroups or exceptions depends largely on the scenario. The same is true about PGT, Policies, or the Canary rollout. I'm using different options in this article to demonstrate a different set of available features.
The scenario
For this tutorial, I focus on a scenario using three Single Node OpenShift (SNO) instances. All are intended for a telco environment, deploying a Midband Distribution Unit. This is just an example, though, and the method I use in this article could apply to other scenarios with ZTP implementing exceptions on some other configuration.
SNO5 and SNO6 are already deployed and working. Both are based on Red Hat OpenShift 4.12 and have been configured for a telco Midband Distribution Unit (MB DU). In their configuration, you can see the groups they belong to and the OpenShift version.
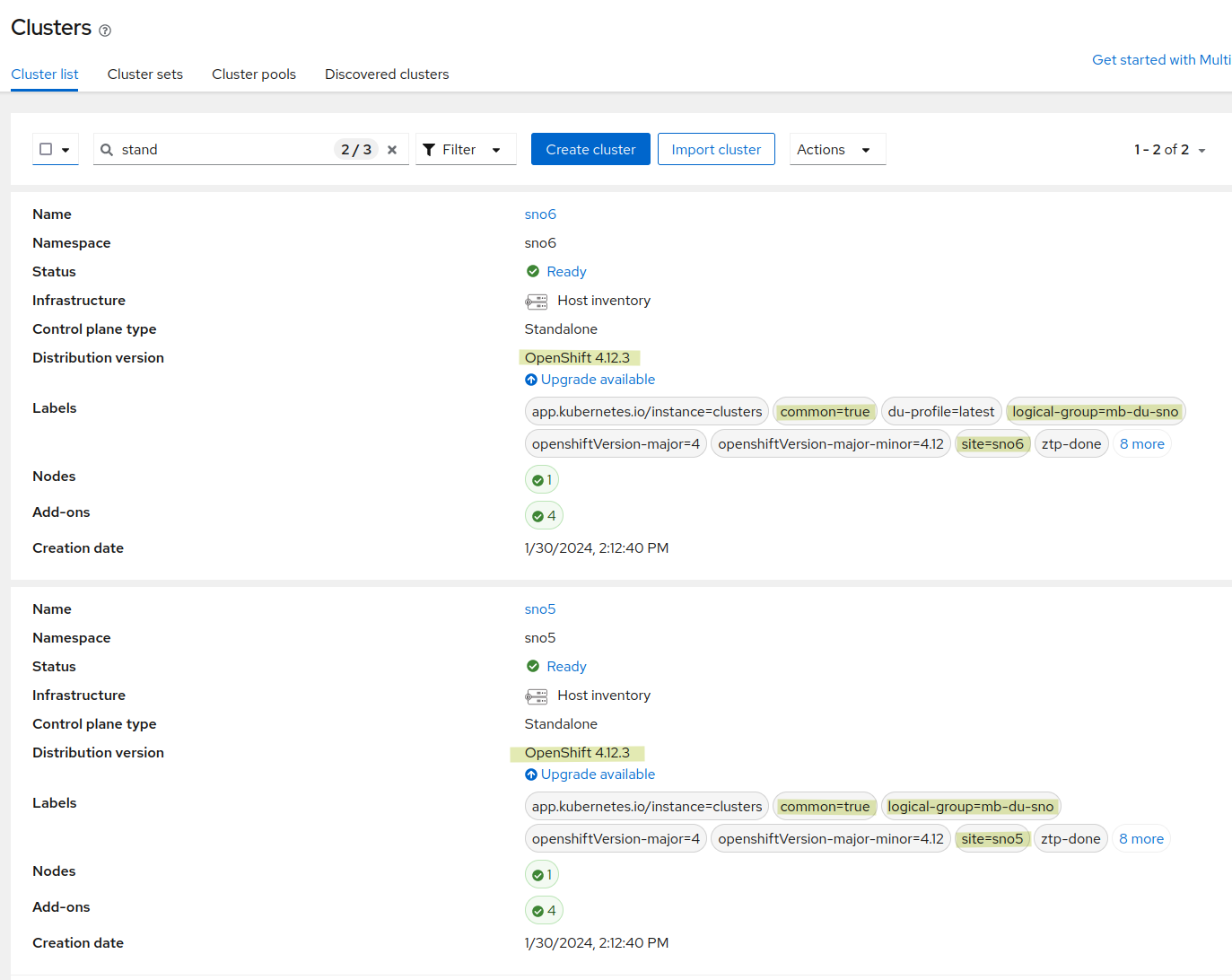
From the Advanced Cluster Management interface, you can see they belong to ‘groups: common’ and ‘group-du-mb’. You can also see the label ‘ztp-done’, which confirms that the clusters have been correctly configured by ZTP, and so workloads can be deployed.
You can also see the different configurations (Policies) that have been applied.
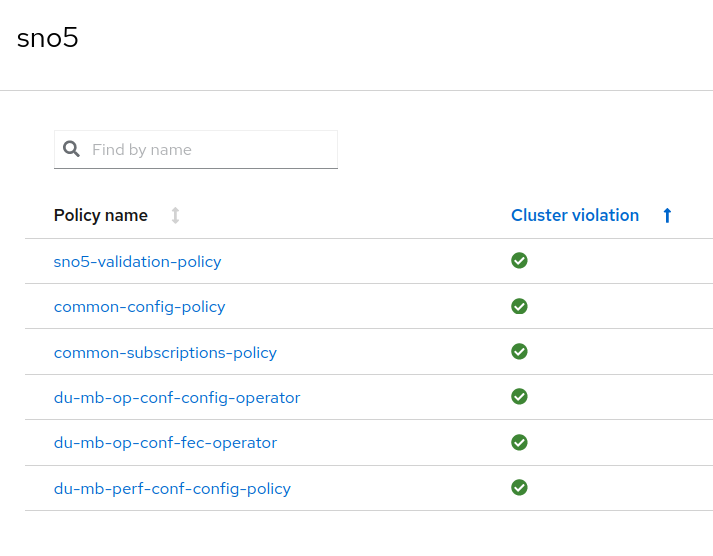
Now I want to introduce a new SNO for an MB DU. But I want to test the configuration with OpenShift 4.13. The idea is to test whether the workloads to be deployed can run in this environment, with the intention of detecting possible issues and missed configurations. We need to reach the ztp-done on OpenShift 4.13, considering that everything would not be 100% available yet, and some exceptions would be needed.
The implemented mechanism requirements:
- Must not affect the current deployments and configurations. For demonstration purposes, I'm using only 3 SNOs and a few configurations. You can imagine scenarios with hundreds of clusters and dozens of configurations
- Must allow exceptions on some configurations. At the same time, we can't make the infrastructure definition and configuration any more complex
- The cluster with exceptions belongs to the appropriate groups. In this case, the cluster is part of the
group group-du-mbregardless of whether it contains exceptions. From a logical and functional point of view, the cluster is a MB DU - Exceptions can be easily reverted
Add a new cluster for experimentation
The new cluster SNO7 is deployed using OpenShift 4.13.
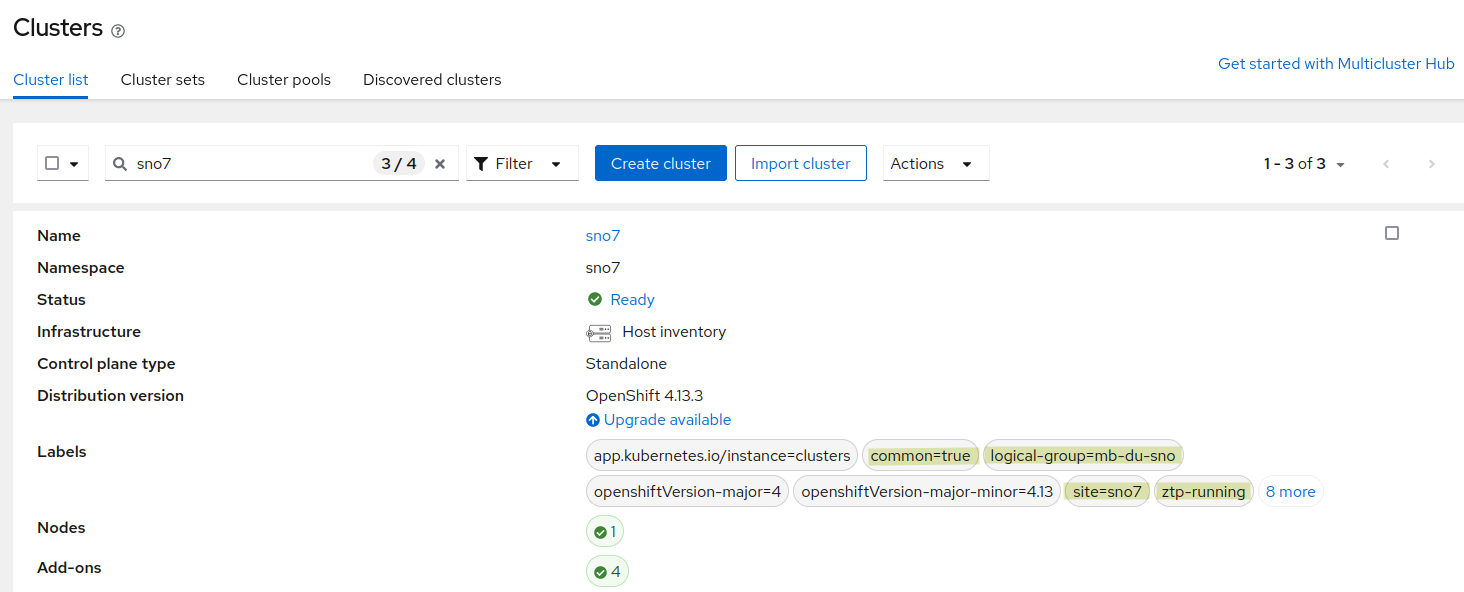
The cluster installation with OpenShift 4.13 has been verified as correct, and the cluster configuration is managed by the labels common and group-du-mb. But the labels ztp-running (instead of ztp-done) indicates that it's not fully configured. It's not ready for day-2 and workloads deployments.
If you take a look at the Policies on Red Hat Advanced Cluster Management, you can see the Policies that need to be applied.
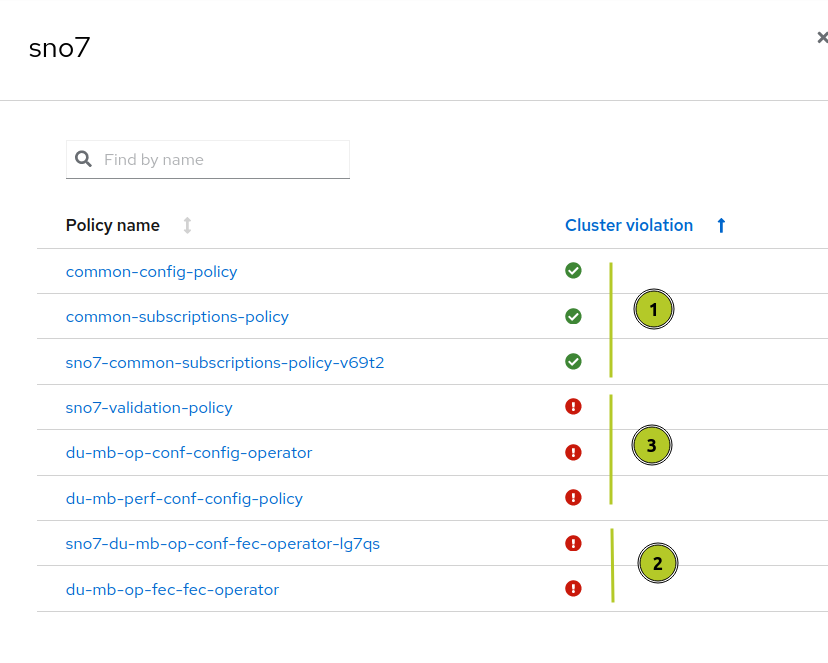
- These first three Policies install all configurations for the clusters labeled as common. This is expected to work. Common policies are pretty generic to all environments
- These are the failing ones. Without going into too much detail,
sno7-du-mb-op-conf-fec-operator-lg7qsis trying to remediate the Policydu-mb-op-fec-operator. And for some reason, it's failing - These Policies aren't being applied yet. These are waiting for the previous one to succeed before continuing. This is the default behavior for remediating Policies
The reason for the failure is an operator that doesn't exist yet in the OpenShift 4.13 catalog. To test the cluster on 4.13, I would proceed without installing this operator. First, I'll create an exception that allows me to fully configure the new cluster and the required operator. When the operator is available, I would remove the exception.
Creating the configuration exceptions
The du-mb-op-fec-fec-operator Policy comes from a PolicyGenTemplate in my GitOps repository:
apiVersion: ran.openshift.io/v1 kind: PolicyGenTemplate metadata: name: "du-mb-op-fec" namespace: "ztp-group" spec: bindingRules: group-du-mb: "" sourceFiles: # Install fec operator as part of the DU - fileName: AcceleratorsNS.yaml policyName: "fec-operator" - fileName: AcceleratorsOperGroup.yaml policyName: "fec-operator" - fileName: AcceleratorsOperatorStatus.yaml policyName: "fec-operator" - fileName: AcceleratorsSubscription.yaml policyName: "fec-operator"
This tries to install the operator that does not exist yet on OpenShift 4.13. You can modify the PolicyGenTemplate conditions to specify which clusters are affected. Currently, all the clusters with group-du-mb are affected, but I'm adding an exception in the PGT:
apiVersion: ran.openshift.io/v1 kind: PolicyGenTemplate metadata: name: "du-mb-op-fec" namespace: "ztp-group" spec: bindingRules: group-du-mb: "" bindingExcludedRules: experiment: ""
Now, the PGT affects the clusters in the group group-du-mb, except for the ones that also belong to the group experiment. In addition, I also need to label the cluster with this new label experiment. In order to do that, we edit the Siteconfig of the SNO7 in our GitOps repository, adding the label experiment:"" in the clusterLabels section:
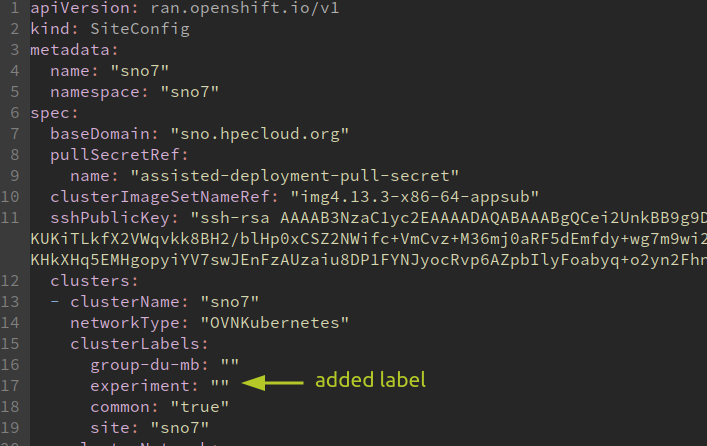
Checking the new status
With the new exception added, the cluster is not affected by the Policy du-mb-op-fec-operator. The configuration continues applying configurations related to this cluster.
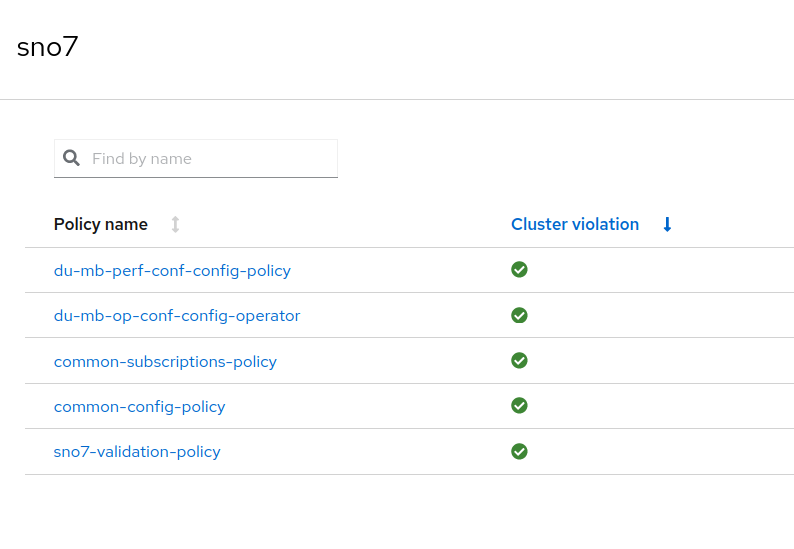
We have reached the final validation and the cluster is ztp-done. We can start deploying workloads.
Revert back to a normal configuration
Just removing the label experiment from the Siteconfig makes the cluster to be affected by all the Policies of the group group-du-mb. So to revert the exception is very easy to achieve.
Conclusions
Using cluster's labels, bindingExcludedRules and bindingRules, we can work at a very detailed level about how we want to configure clusters. In this tutorial, we have seen how to implement exceptions for cluster groups, not having to create multiple copies of a Policy for different groups or subgroups. The exceptions allow us to skip some configurations, with an easy way of going back to a normal configuration.
With my previous tutorial, Working with subgroups and configurations on your ZTP/Red Hat Advanced Cluster Management for Kubernetes infrastructure, you can see different mechanisms to do fine tuning about how we want to apply configurations in clusters. Using these principles, you can test without putting your infrastructure at risk.
Sobre o autor

Computer Engineer from the Universidad Rey Juan Carlos. Currently working as Software Engineer at Red Hat, helping different clients in the process of certifying CNF with Red Hat Openshift. Expert and enthusiastic about Free/Libre/Open Source Software with wide experience working with Open Source technologies, systems and tools.
Mais como este
Control your AI agent traffic at scale: Model Context Protocol gateway for Red Hat OpenShift is now in technology preview
Why developer portals matter more in the age of AI agents
Becoming a Coder | Command Line Heroes
You need Ops to AIOps | Technically Speaking
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem