
Previously we learned all about the benefits in placing Ceph storage services directly on compute nodes in a co-located fashion. This time, we dive deep into the deployment templates to see how an actual deployment comes together and then test the results!
Enabling Co-Location
This article assumes the director is installed and configured with nodes already registered. The default Heat deployment templates ship an environment file for enabling Pure HCI. This environment file is:
/usr/share/openstack-tripleo-heat-templates/environments/hyperconverged-ceph.yaml
This file does two things:
- It redefines the composable service list for the Compute role to include both Compute and Ceph Storage services. The parameter for storing this list in ComputeServices.
- It enables a port on the Storage Management network for Compute nodes using the OS::TripleO::Compute::Ports::StorageMgmtPort resource. The default network isolation disables this port for standard Compute nodes. For our scenario we must enable this port and its network for the Ceph services to communicate. If you are not using network isolation, you can leave the resource at None to disable the resource.
Updating Network Templates
As mentioned, the Compute nodes need to be attached to the Storage Management network so Red Hat Ceph Storage can access the OSDs on them. This is not usually required in a standard deployment. To ensure the Compute node receives an IP address on the Storage Management network, you need to modify the NIC templates for your Compute node to include it. As a basic example, the following snippet adds the Storage Management network to the compute node via the OVS bridge supporting multiple VLANs:
- type: ovs_bridge name: br-vlans use_dhcp: false members: - type: interface name: nic3 primary: false - type: vlan vlan_id: get_param: InternalApiNetworkVlanID addresses: - ip_netmask: get_param: InternalApiIpSubnet - type: vlan vlan_id: get_param: StorageNetworkVlanID addresses: - ip_netmask: get_param: StorageIpSubnet - type: vlan vlan_id: get_param: StorageMgmtNetworkVlanID addresses: - ip_netmask: get_param: StorageMgmtIpSubnet - type: vlan vlan_id: get_param: TenantNetworkVlanID addresses: - ip_netmask: get_param: TenantIpSubnet
The blue highlighted section is the additional VLAN interface for the Storage Management network we discussed.
Isolating Resources
We calculate the amount of memory to reserve for the host and Red Hat Ceph Storage services using the formula found in "Reserve CPU and Memory Resources for Compute”. Note that we accommodate for 2 OSDs so that we can potentially scale an extra OSD on the node in the future.
Our total instances:
32GB / (2GB per instance + 0.5GB per instance for host overhead) = ~12 hosts
Total host memory to reserve:
(12 hosts * 0.5 overhead) + (2 OSDs * 3GB) = 12GB or 12000MB
This means our reserved host memory is 12000MB.
We can also define how to isolate the CPU resources in two ways:
- CPU Allocation Ratio - Estimate the CPU utilization of each instance and set the ratio of instances per CPU while taking into account Ceph service usage. This ensures a certain amount of CPU resources are available for the host and Ceph services. See the ”Reserve CPU and Memory Resources for Compute” documentation for more information on calculating this value.
- CPU Pinning - Define which CPU cores are reserved for instances and use the remaining CPU cores for the host and Ceph services.
This example uses CPU pinning. We are reserving cores 1-7 and 9-15 of our Compute node for our instances. This leaves cores 0 and 8 (both on the same physical core) for the host and Ceph services. This provides one core for the current Ceph OSD and a second core in case we scale the OSDs. Note that we also need to isolate the host to these two cores. This is shown after deploying the overcloud.

Using the configuration shown, we create an additional environment file that contains the resource isolation parameters defined above:
parameter_defaults:
NovaReservedHostMemory: 12000
NovaVcpuPinSet: ['1-7,9-15']Our example does not use NUMA pinning because our test hardware does not support multiple NUMA nodes. However if you want to pin the Ceph OSDs to a specific NUMA node, you can do so using following “Configure Ceph NUMA Pinning”.
Deploying the configuration ...
This example uses the following environment files in the overcloud deployment:
- /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml - Enables network isolation for the default roles, including the standard Compute role.
- /home/stack/templates/network.yaml - Custom file defining network parameters (see Updating Network Templates). This file also sets the OS::TripleO::Compute::Net::SoftwareConfig resource to use our custom NIC Template containing the additional Storage Management VLAN we added to the Compute nodes above.
- /home/stack/templates/storage-environment.yaml - Custom file containing Ceph Storage configuration (see Appendix A. Sample Environment File: Creating a Ceph Cluster for an example).
- /usr/share/openstack-tripleo-heat-templates/environments/hyperconverged-ceph.yaml - Redefines the service list for Compute nodes to include the Ceph OSD service. Also adds a Storage Management port for this role. This file is provided with the director’s Heat template collection.
- /home/stack/templates/hci-resource-isolation.yaml - Custom file with specific settings for resource isolation features such as memory reservation and CPU pinning (see Isolating Resources).
The following command deploys an overcloud with one Controller node and one co-located Compute/Storage node:
$ openstack overcloud deploy \ --templates /usr/share/openstack-tripleo-heat-templates \ -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml \ -e /home/stack/templates/network.yaml \ -e /home/stack/templates/storage-environment.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/hyperconverged-ceph.yaml \ -e /home/stack/templates/hci-resource-isolation.yaml --ntp-server pool.ntp.org
Configuring Host CPU Isolation
As a final step, this scenario requires isolating the host from using the CPU cores reserved for instances. To do this, log into the Compute node and run the following commands:
$ sudo grubby --update-kernel=ALL --args="isolcpus=1,2,3,4,5,6,7,9,10,11,12,13,14,15" $ sudo grub2-install /dev/sda
This updates the kernel to use the isolcpus parameter, preventing the kernel from using cores reserved for instances. The grub2-install command updates the boot record, which resides on /dev/sda for default locations. If using a custom disk layout for your overcloud nodes, this location might be different.
After setting this parameter, we reboot our Compute node:
$ sudo rebootTesting
After the Compute node reboots, we can view the hypervisor details to see the isolated resources from the undercloud:
$ source ~/overcloudrc $ openstack hypervisor show overcloud-compute-0.localdomain -c vcpus +-------+-------+ | Field | Value | +-------+-------+ | vcpus | 14 | +-------+-------+ $ openstack hypervisor show overcloud-compute-0.localdomain -c free_ram_mb +-------------+-------+ | Field | Value | +-------------+-------+ | free_ram_mb | 20543 | +-------------+-------+
2 of the 16 CPU cores are reserved for the Ceph services and only 20GB out for 32GB is available for the host to use for instance.
So, let’s see if this really worked. To find out, we will run some Browbeat tests against the overcloud. Browbeat is a performance and analysis tool specifically for OpenStack. It allows you to analyse, tune, and automate the entire process.
For our test we have run a set of Browbeat benchmark tests showing the CPU activity for different cores. The following graph displays the activity for a host/Ceph CPU core (Core 0) during one of the tests:
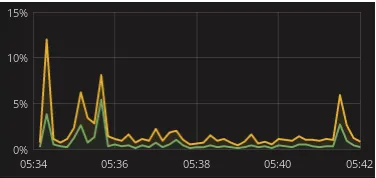
The green line indicates the system processes and the yellow line indicates the user processes. Notice that the CPU core activity peaks during the beginning and end of the test, which is when the disks for the instances were created and deleted respectively. Also notice the CPU core activity is fairly low as a percentage.
The other available host/Ceph CPU core (Core 8) follows a similar pattern:

The peak activity for this CPU core occurs during instance creation and during three periods of high instance activity (the Browbeat tests). Also notice the activity percentages are significantly higher than the activity on Core 0.
Finally, the following is an unused CPU core (Core 2) during the same test:

As expected, the unused CPU core shows no activity during the test. However, if we create more instances and exceed the ratio of allowable instances on Core 1, then these instances would use another CPU core, such as Core 2.
These graphs indicate our resource isolation configuration works and the Ceph services will not overlap with our Compute services, and vice versa.
Conclusion
Co-locating storage on compute nodes provides a simple method to consolidate storage and compute resources. This can help when you want to maximize the hardware of each node and consolidate your overcloud. By adding tuning and resource isolation you can allocate dedicated resources to both storage and compute services, preventing both from starving each other of CPU and memory. And by doing this via Red Hat OpenStack Platform director and Red Hat Ceph Storage, you have a solution that is easy to deploy and maintain!
关于作者









产品
工具
试用购买与出售
沟通
关于红帽
我们是世界领先的企业开源解决方案供应商,提供包括 Linux、云、容器和 Kubernetes。我们致力于提供经过安全强化的解决方案,从核心数据中心到网络边缘,让企业能够更轻松地跨平台和环境运营。