红帽 OpenShift AI
红帽® OpenShift® AI 是一个平台,用于在混合云环境中大规模管理预测性 AI 模型和生成式人工智能(生成式 AI)模型的生命周期。
什么是红帽 OpenShift AI?
OpenShift AI 采用开源技术构建,能提供值得信赖且运维一致的功能,助力团队进行实验、供应模型以及交付创新应用。
OpenShift AI 支持数据的获取和准备、模型训练和微调、模型服务、模型监控及硬件加速。凭借由硬件和软件合作伙伴组成的开放式生态系统,OpenShift AI 能够满足不同的需求和场景。

加速将 AI 赋能的应用部署到生产环境
这款一站式企业就绪型 AI 应用平台集结了红帽 Openshift AI 和红帽 OpenShift 成熟可靠的功能,能够让不同团队团结一心、顺畅协作。数据科学家、工程师和应用开发人员可以在统一的平台上进行协作,从而提高一致性、安全性和可扩展性。
最新发布的 OpenShift AI 包含一系列精挑细选的、经过优化的生产就绪型第三方模型,这些模型均已通过红帽 OpenShift AI 验证。拥有这个第三方模型目录的访问权限后,您的团队能够更好地控制模型可访问性和可见性,这有助于满足安全性与政策要求。
此外,OpenShift AI 还借助优化的 vLLM 框架提供的分布式服务功能,帮助用户管理推理成本。为进一步降低运维复杂性,它提供了高级工具来实现部署自动化,并支持自助访问模型、工具和资源。
减少在 AI 基础架构管理上花费的时间
按需获取高性能模型,从而轻松实现自助服务、扩展和部署。 开发人员可跳过复杂操作,保持控制权并优化成本。
诸如模型即服务(MaaS)等功能目前处于开发人员预览版阶段。该服务通过 API 端点提供 AI 访问方式,助力实现私有且更快速的大规模 AI 部署。
经过测试、享受支持的 AI/ML 工具
红帽平台可替您测试、集成和支持 AI/ML 工具和模型服务,无需您自己费心费力。OpenShift AI 借鉴了红帽 Open Data Hub 社区项目及 Kubeflow 等开源项目多年的孵化经验。
我们凭借丰富的经验和开源专业知识,提供生成式 AI 就绪型基础,让客户在制定生成式 AI 策略时拥有更多选择与更大的信心。
跨混合云的灵活性
红帽 OpenShift AI 提供了一个安全、灵活的平台,让您可以自由选择开发和部署模型的位置,无论是在本地、公共云还是边缘。
AI 快速入门
探索来自我们社区的各种创新 AI 用例。这些示例简单明了、重点突出,专为在红帽 AI 平台上快速、轻松地部署而设计。


适用于红帽 OpenShift AI 的 MCP 服务器
探索我们精挑细选的 MCP 服务器集合,这些来自技术合作伙伴的服务器可与红帽 OpenShift AI 集成。
模型上下文协议(MCP)是一种开源协议,可实现 AI 应用与外部服务之间的双向连接和标准化通信。
现在,您可利用这些 MCP 服务器,将企业工具和资源集成到 AI 应用和代理式工作流中。
利用 vLLM 进行优化,以实现大规模快速且经济高效的推理。
红帽 AI 推理服务器是红帽 AI 平台的一部分。它既可以作为独立产品使用,同时也已包含在红帽企业 Linux® AI 和红帽 OpenShift® AI 中。
能够满足您需求并按您意愿运行的 AI。
生成式 AI
制作文本和软件代码等新内容。
借助红帽 AI,您可以更快地运行您选择的生成式 AI 模型,同时减少资源消耗并降低推理成本。

预测性 AI
应用模式并预测未来结果。
借助红帽 AI,企业组织能够构建、训练、部署和监控预测模型,同时在混合云环境中始终保持一致性。
运营化 AI
创建支持大规模维护和部署 AI 的系统。
借助红帽 AI,在节省资源并确保遵守隐私法规的同时,管理与监控支持 AI 的应用的生命周期。

代理式 AI
构建在有限监督下执行复杂任务的工作流。
红帽 AI 为在现有应用中构建、管理和部署代理式 AI 工作流提供了灵活的方法和稳定的基础。
借助模型工作台实现协同工作
AI 中心与生成式 AI 工作室支持平台工程师和 AI 工程师协同工作,从而更快地将生成式 AI 模型投入使用。
AI 中心支持平台工程师管理 LLM 与集中式 AI 工作负载,以及来自第三方模型验证的性能洞察分析。生成式 AI 工作室为 AI 工程师提供一个实操环境,可通过 Playground 与模型进行交互,并快速构建生成式 AI 应用原型。在生命周期集成前,通过沙盒环境验证模型适用性,并对聊天与检索增强生成(RAG)流程开展实验。
此外,数据科学家可访问预构建或定制的集群镜像,使用首选的 IDE 和框架处理模型。红帽 OpenShift AI 会跟踪对 Jupyter、PyTorch、Kubeflow 及其他开源 AI 技术进行的更改。
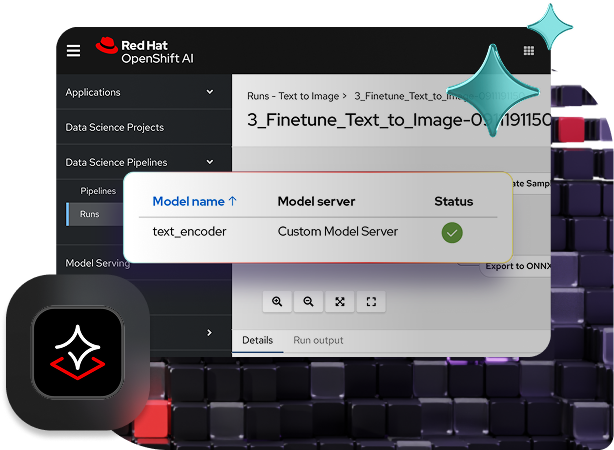
借助红帽 OpenShift AI 实现模型服务与安全性的扩展
您可以使用经过优化的 vLLM 版本(或您选择的其他模型服务器)来实现模型服务,以集成到在本地、公共云中或边缘运行的依托 AI 技术的应用中。还可以基于对源 notebook 的更改来重新构建、重新部署和监控这些模型。
模型幻觉与偏差问题可能会损害模型的完整性,增加其规模化应用的难度。为帮助维护模型公平性、安全性和可扩展性,OpenShift AI 允许数据从业人员监控模型输出与训练数据之间的一致性。
漂移检测工具可监测模型推理所用的实时数据何时偏离原始训练数据。 此外,内置的 AI 防护机制可以保护模型输入和输出免受有害信息(如辱骂性和亵渎性言论、个人数据或特定领域限制)的影响。

2025 年红帽全球峰会和 AnsibleFest 大会 AI 客户案例集锦
土耳其航空公司通过实现企业范围内的数据访问,将部署速度提高了一倍。
JCCM 利用 AI 技术,改进了该地区的环境影响评估(EIA)流程。
Denizbank 将上市时间从数天缩短到数分钟。
Hitachi 借助红帽 OpenShift AI 在整个业务范围内实施了 AI。
如何试用红帽 OpenShift AI
开发人员沙盒
适合想要尝试在灵活的预配置环境中构建依托 AI 技术的应用的开发人员和数据科学家。
60 天试用
企业组织准备好评估 OpenShift AI 的全部功能后,可以通过 60 天产品试用进行探索。需要用到现有的红帽 OpenShift 集群。