

Introducción
Las estrategias de recuperación ante desastres para las máquinas virtuales en Red Hat OpenShift son esenciales para mantener la continuidad empresarial durante las interrupciones imprevistas. A medida que las empresas migran sus cargas de trabajo más importantes a las plataformas de Kubernetes, se vuelve fundamental poder recuperarlas de manera rápida y segura.
Si bien las máquinas virtuales sin estado y efímeras se han vuelto comunes en los entornos de nube, la mayoría de las cargas de trabajo de las máquinas virtuales empresariales conservan su estado. Estas requieren almacenamiento en bloques permanente que se pueda volver a conectar durante los reinicios o las migraciones. Por lo tanto, la recuperación ante desastres para las máquinas virtuales con estado plantea desafíos muy diferentes a los que abordaban los patrones de recuperación ante desastres de Kubernetes (Spazzoli, 2024), que generalmente se centraban en las aplicaciones basadas en contenedores sin estado.
En esta publicación de blog, se explican distintos requisitos de las máquinas virtuales con estado. En primer lugar, se explora la manera en que las opciones de arquitectura de clústeres y almacenamiento afectan la viabilidad de la conmutación por error, el comportamiento de la replicación y los objetivos de punto de recuperación (RPO) y de tiempo de recuperación (RTO). Luego, se describe el nivel organizativo para mostrar la forma en que las herramientas originales de Kubernetes, como Red Hat Advanced Cluster Management, Helm, Kustomize y los canales de GitOps, controlan la ubicación y la recuperación de las cargas de trabajo. Por último, se analiza la manera en que las plataformas de almacenamiento avanzado que replican tanto el almacenamiento en bloques como los manifiestos de Kubernetes optimizan el proceso de recuperación y combinan la infraestructura y la automatización de las aplicaciones.
Terminología
Antes de avanzar, definamos algunos términos importantes:
Desastre:
En el contexto de este análisis, el término "desastre" hace referencia a la "pérdida de sitio".Cuando pensamos en la recuperación ante desastres, siempre se busca reducir al mínimo la interrupción de un servicio empresarial. Por lo tanto, cuando pierdes un sitio, debes implementar los planes de recuperación ante desastres para restaurar el servicio en el sitio alternativo de la manera más rápida y eficiente posible.
Nota: Un plan de recuperación ante desastres no solo se lleva a cabo cuando se pierde un sitio, sino que es habitual aplicarlo para los servicios empresariales individuales cuando hay una falla en un elemento principal que requiere trasladar estos servicios a un sitio alternativo mientras se restaura el elemento dañado.
Falla de un elemento:
Se trata de la falla de uno o más subsistemas que afecta a un subconjunto de aplicaciones de la empresa. Este modo requerirá trasladar el procesamiento a un sistema alternativo en el sitio principal, o bien puede ser necesario implementar planes individuales de recuperación ante desastres para llevar el procesamiento de la aplicación empresarial a un sitio secundario.
Objetivo de punto de recuperación (RPO):
El RPO es la cantidad máxima de datos (medida según el tiempo) que se puede perder después de la recuperación de una falla o un desastre, antes de que la pérdida de datos supere la cantidad que una empresa considera aceptable.
Objetivo de tiempo de recuperación (RTO):
El RTO es la cantidad máxima de tiempo que una empresa puede tolerar sin que un servicio esté disponible. Si bien las diferentes opciones de arquitectura influyen en el RTO, estos aspectos no se analizarán en detalle en esta publicación de blog.
Metro-DR y Regional-DR:
Hay dos tipos de recuperación ante desastres: la recuperación ante desastres local (Metro-DR) y la recuperación ante desastres regional (Regional-DR).
- Metro-DR es ideal cuando los centros de datos están lo suficientemente cerca y el rendimiento de la red permite la replicación sincrónica de los datos. Esta replicación tiene la ventaja de que permite alcanzar un RPO de cero.
- Regional-DR es ideal cuando debes usar la replicación asíncrona porque los centros de datos están demasiado alejados entre sí para admitir el otro método. Si bien es muy probable que con esta replicación se pierda cierta cantidad de datos, no es un aspecto relevante para el propósito del blog.
Nota: Si tu infraestructura de almacenamiento no admite la replicación sincrónica, se usará una arquitectura de Regional-DR para Metro-DR.
Tormenta de reinicios:
Una tormenta de reinicios se produce cuando intentas reiniciar una gran cantidad de máquinas virtuales simultáneamente y el hipervisor y la infraestructura de soporte no pueden completar la tarea. Por lo tanto, las máquinas virtuales no se reinician o tardan mucho más de lo aceptable. También se puede describir como un ataque de denegación de servicio no malintencionado.
Estrategias de arquitectura para la continuidad empresarial
Hay varias estrategias para lograr la continuidad empresarial y la recuperación ante desastres. Para obtener más información sobre el tema, consulta el whitepaper Cloud Native Disaster Recovery for Stateful Workloads (Spazzoli, 2024) de Cloud Native Computing Foundation (CNCF). En términos generales, hay cuatro estrategias arquetípicas de recuperación ante desastres que se representan en el siguiente diagrama (en el whitepaper hay una explicación detallada de cada una de ellas):
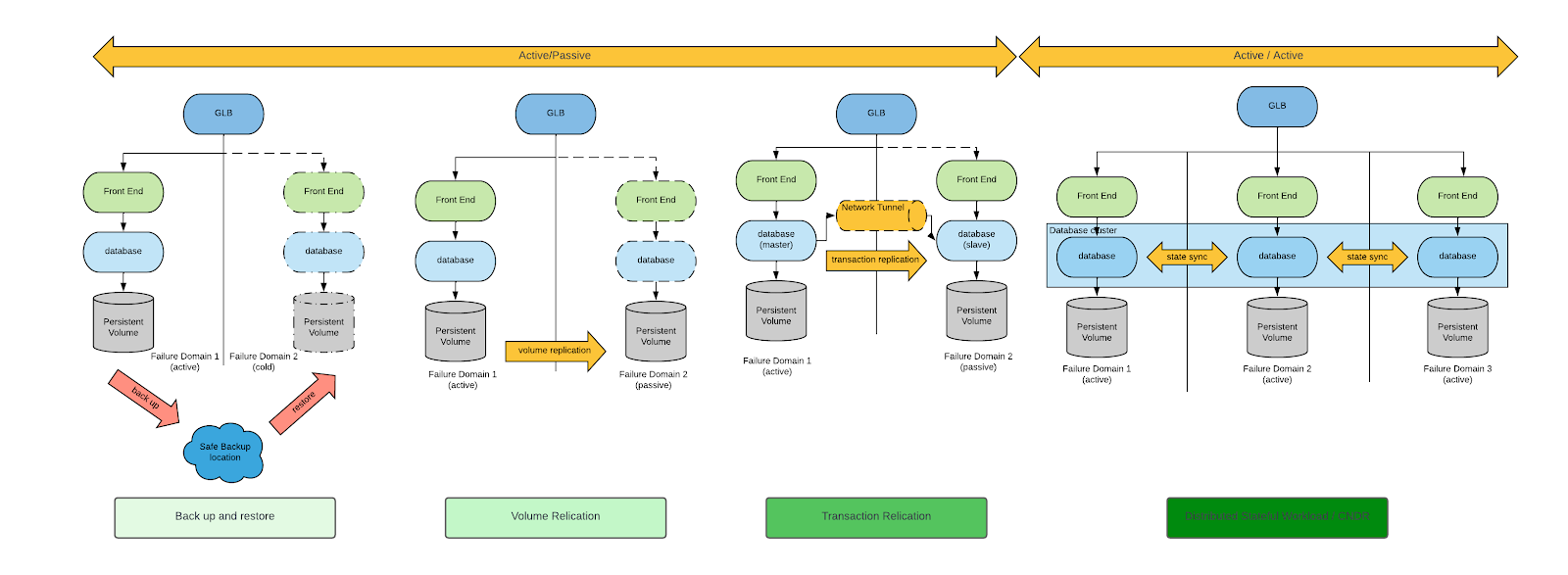
A la hora de tener en cuenta los requisitos de recuperación ante desastres para las máquinas virtuales, el proceso de backup y restauración y la replicación de volúmenes son los únicos patrones adecuados.
Tanto el proceso de backup y restauración como la replicación de volúmenes son estrategias viables, pero esta última disminuye el RPO y el RTO. Por este motivo, nos centraremos únicamente en ella.
Después de delimitar nuestro campo de análisis, abordaremos dos estrategias de arquitectura para la recuperación ante desastres, que se distinguen por el tipo de replicación de volúmenes:
- replicación unidireccional;
- replicación simétrica o bidireccional.
Replicación unidireccional
Con la replicación unidireccional, los volúmenes se copian de un centro de datos a otro, pero no viceversa. La dirección se controla a través de la matriz de almacenamiento, y la replicación de volúmenes puede ser sincrónica o asíncrona. La elección depende de la función de la matriz y de la latencia entre los dos centros de datos. La replicación asíncrona es adecuada para los centros de datos que tienen una alta latencia entre sí y que probablemente se encuentran en la misma región geográfica, pero no en la misma área local.
Con respecto a la arquitectura, la replicación unidireccional se representa de manera similar a la siguiente figura:
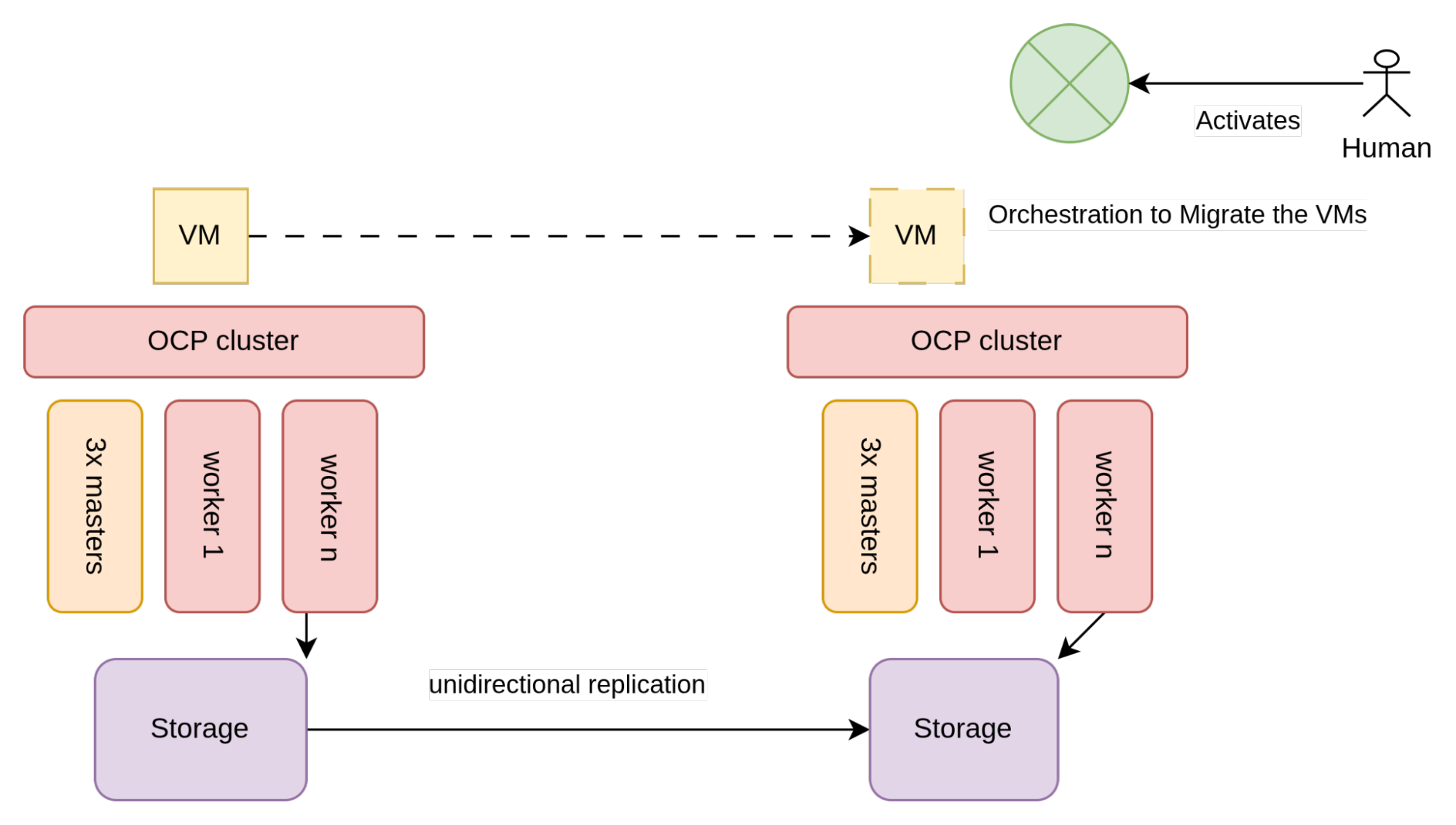
Como se ilustra en la figura 2, el almacenamiento que utilizan las máquinas virtuales, (por lo general, matrices de red de área de almacenamiento), está configurado para permitir esa replicación.
Hay dos clústeres de OpenShift diferentes en cada centro de datos, y cada uno está conectado a la matriz de almacenamiento local. Los clústeres están aislados, por lo que los únicos límites para implementar esta arquitectura los establece el proveedor de almacenamiento y, específicamente, los requisitos que deben cumplirse para facilitar la replicación unidireccional.
Aspectos importantes para la replicación de volúmenes unidireccional
La replicación de volúmenes no está estandarizada en la especificación de la interfaz de almacenamiento de contenedores (CSI) de Kubernetes. Por lo tanto, los proveedores de almacenamiento crearon definiciones de recursos personalizados (CRD) propietarias para posibilitar esta función. En general, observamos tres niveles de consolidación de los proveedores con esta función:
- La función de replicación de volúmenes no está disponible en la CSI, o sí lo está, pero no permite crear una organización adecuada para la recuperación ante desastres sin llamar directamente a la interfaz de programación de aplicaciones (API) de la matriz de almacenamiento.
- La función de replicación de volúmenes está disponible en la CSI.
- La función de replicación de volúmenes está disponible y el proveedor también gestiona la restauración de los metadatos del espacio de nombres (es decir, las máquinas virtuales y otros manifiestos presentes en el espacio de nombres).
Debido a esta fragmentación, no es sencillo escribir un proceso de recuperación ante desastres independiente del proveedor para una configuración de Regional-DR. La cantidad que se debe escribir para organizar el proceso de manera adecuada depende del proveedor de almacenamiento.
Analicemos el comportamiento de esta arquitectura en diferentes modos de fallas: falla del nodo de OpenShift, falla de la matriz de almacenamiento (fallas de los elementos) y falla de todo el centro de datos (este es un caso real de recuperación ante desastres).
Falla del nodo de OpenShift
En caso de que un nodo (o elemento) deje de funcionar, el programador de OpenShift Virtualization se encarga de reiniciar automáticamente la máquina virtual en el siguiente nodo más adecuado del clúster. En este caso, no es necesario realizar ninguna otra acción.
Falla de la matriz de almacenamiento
Si una matriz de almacenamiento se interrumpe, todas las máquinas virtuales que dependen de ella también se interrumpirán. En este caso, será necesario llevar a cabo el proceso de recuperación ante desastres. (Consulta la sección "Proceso de recuperación ante desastres" para conocer los pasos que se deben seguir).
Falla del centro de datos
Si hay un problema en el centro de datos, se debe implementar el proceso de recuperación ante desastres para reiniciar todas las máquinas virtuales que no se vieron afectadas. En este caso, la automatización desempeña un papel fundamental. Sin embargo, este proceso suele iniciarlo una persona dentro de un marco de gestión de incidentes graves. En la siguiente sección, se describen los pasos que se deben seguir.
Proceso de recuperación ante desastres
Estos procedimientos pueden ser muy complicados, pero, en términos sencillos, un proceso de recuperación ante desastres debe tener en cuenta lo siguiente:
- Los volúmenes de las máquinas virtuales que forman parte de la misma aplicación deben replicarse de manera uniforme. Esto suele significar que esos volúmenes son parte del mismo grupo de uniformidad.
- Debe ser posible controlar si los volúmenes de un grupo de uniformidad deben replicarse y en qué dirección. En circunstancias normales, se copiarán del sitio activo al sitio pasivo. Durante el proceso de conmutación por error, los volúmenes no se replican. En la fase de preparación para la conmutación por recuperación, los volúmenes se replican del sitio pasivo al sitio activo. En un proceso de conmutación por recuperación, los volúmenes no se replican.
- Debe ser posible reiniciar las máquinas virtuales en el otro centro de datos, y estas deben poder conectarse al volumen de almacenamiento replicado.
- Es posible que debas limitar el reinicio de las máquinas virtuales para evitar una tormenta de reinicios. Además, suele ser conveniente priorizar la secuencia de reinicio de las máquinas para que las aplicaciones más importantes se inicien primero o para garantizar que los elementos dependientes, como las bases de datos, se inicien antes que los servicios que dependen de ellos.
Aspectos importantes sobre los costos
Según la configuración del clúster de OpenShift, puede considerarse un sitio de recuperación ante desastres cálido o activo. Los sitios activos deben contar con suscripciones completas, mientras que los cálidos no (esto puede generar ahorro de costos).
En general, si no hay cargas de trabajo activas ejecutándose en el sitio de recuperación ante desastres, se puede considerar cálido. En particular, se pueden configurar volúmenes persistentes (PV), solicitudes de volumen persistente (PVC) e incluso máquinas virtuales que no se ejecutan, listos para iniciarse en caso de que ocurra un desastre y, aun así, conservar la designación de sitio cálido.
Configuración activa-pasiva simétrica
No es habitual tener todas las cargas de trabajo en el sitio activo, ya que las empresas suelen dividirlas por la mitad y repartirlas entre los centros de datos principales y secundarios. Esta estrategia práctica garantiza que, si ocurre un desastre, no afecte a todos los servicios a la vez. Además, la iniciativa de recuperación general se reduce según corresponda.
Cuando se distribuyen las máquinas virtuales activas entre los centros de datos, cada uno se configura para responder por la conmutación por error del otro. Esta configuración a veces se conoce como "activa-pasiva simétrica".
La configuración activa-pasiva simétrica funciona con OpenShift Virtualization y la arquitectura que analizamos anteriormente. Recuerda que, con esta configuración, ambos centros de datos se consideran activos, por lo que todos los nodos de OpenShift deben estar suscritos.
Replicación simétrica
Con la replicación simétrica, los volúmenes se copian de forma sincrónica y en ambas direcciones. Debido a esto, los dos centros de datos pueden tener volúmenes activos y aceptar tareas de escritura en ellos. Para que esto sea posible, las empresas deben tener dos centros de datos cuya latencia de red sea muy baja (por ejemplo, aproximadamente menor que cinco ms). Por lo general, esto es posible si los dos centros de datos se encuentran en la misma área metropolitana o local, por lo que esta arquitectura también se conoce como Metro-DR. En este caso, se puede utilizar la siguiente infraestructura:

En esta arquitectura, el almacenamiento que utilizan las máquinas virtuales (por lo general, una matriz SAN) se configura para llevar a cabo la replicación simétrica entre los dos centros de datos.
Esto crea una matriz de almacenamiento lógica que los abarca a ambos centros de datos. Para posibilitar la replicación simétrica, es necesario tener un "sitio testigo" que actúe como árbitro independiente para evitar casos de "cerebro dividido" (split-brain) cuando surgen fallas en la red o el sitio.
El sitio testigo no tiene que ser tan similar (en términos de latencia) a los dos centros de datos principales, ya que se usa para ayudar a tomar una decisión y para desempatar en los casos de cerebro dividido. El sitio testigo debe ser una zona de disponibilidad independiente, no debe contener cargas de trabajo de aplicaciones, no necesita tener una gran capacidad, pero sí debe tener la misma calidad de servicio que los demás centros de datos en términos de operaciones (por ejemplo, la seguridad física y lógica, la gestión de la energía y el enfriamiento).
Como el almacenamiento se extiende a todos los centros de datos, OpenShift funciona de forma distribuida entre ellos. Para implementar esto en una arquitectura de alta disponibilidad, se requieren tres zonas (sitios) de disponibilidad para el plano de control de OpenShift. Esto se debe a que la base de datos etcd interna de Kubernetes requiere al menos tres áreas de error para mantener una cantidad confiable. Por lo general, esto se implementa aprovechando el sitio testigo de almacenamiento para uno de los nodos del plano de control.
La mayoría de los proveedores de red de área de almacenamiento admiten la replicación simétrica para sus matrices de almacenamiento. Sin embargo, no todos incluyen esta función en la CSI. Suponiendo que un proveedor de almacenamiento admite la replicación simétrica en la CSI y que se cumplen los requisitos previos y las configuraciones necesarias, cuando se crea una PVC, se aprovisiona un número de unidad de lógica (LUN) de varias rutas. Este LUN incluye rutas que van a ambos centros de datos, por lo que todos los nodos de OpenShift deben configurarse para permitir la conexión a ambas matrices de almacenamiento. Por lo general, el dispositivo de varias rutas se crea de dos maneras: la primera es con una configuración de acceso asimétrico a unidades lógicas (ALUA) (Certificación de TI de Pearson, 2024), que es activa-pasiva, en la que la ruta activa lleva a la matriz más cercana; mientras que la segunda es con una configuración activa-activa, en la que se prioriza la ruta más cercana a la matriz por su alto peso.
Algunos proveedores permiten esta arquitectura cuando las conexiones de canal de fibra no son "uniformes", lo que significa que los nodos en un sitio solo pueden conectarse a la matriz de almacenamiento local. En este caso, la configuración de ALUA no se crea.
Esta topología de clústeres brinda protección contra las fallas de los elementos y los desastres. Analicemos el comportamiento de esta arquitectura en diferentes modos de falla.
Falla del nodo de OpenShift
En caso de que un nodo (o elemento) deje de funcionar, el programador de OpenShift Virtualization se encarga de reiniciar automáticamente la máquina virtual en el siguiente nodo más adecuado del clúster. En este caso, no es necesario realizar ninguna otra acción.
Falla de la matriz de almacenamiento
Los LUN de varias rutas garantizan la continuidad del servicio en caso de que una de las dos matrices de almacenamiento falle o se desconecte para su mantenimiento. En un caso de conectividad uniforme, la ruta pasiva o menos pesada de los LUN de varias rutas se usará para conectar la máquina virtual a las otras matrices. Este error es completamente transparente para las máquinas virtuales, lo que genera un ligero aumento de la latencia de E/S del disco. En un caso de conectividad no uniforme, se debe migrar la máquina virtual a un nodo con conectividad.
Falla del centro de datos
Cuando un centro de datos completo deja de estar disponible, OpenShift lo interpretará como una falla de varios nodos al mismo tiempo. La plataforma comenzará a programar las máquinas virtuales para que se ejecuten en los nodos dentro del otro centro de datos, como se describe en la sección "Falla del nodo de OpenShift".
Si hay suficiente capacidad disponible para migrar las cargas de trabajo, todas las máquinas se reiniciarán en el otro centro de datos. Las máquinas virtuales que se reinician tienen un RPO y un RTO de cero, que resulta de la suma de los siguientes tiempos:
- el tiempo que tarda OpenShift en notar que los nodos no están listos;
- el tiempo que tarda aislar los nodos;
- el tiempo que tarda reiniciar las máquinas virtuales;
- el tiempo que tarda completar el proceso de arranque de las máquinas virtuales.
Este mecanismo de recuperación ante desastres es totalmente autónomo y no requiere intervención humana. Sin embargo, no siempre es la opción recomendada. Para evitar una tormenta de reinicios, suele ser conveniente identificar las máquinas virtuales que se reinician y el momento en el que comienza el proceso.
Aspectos importantes sobre Metro-DR
Estos son algunos de los aspectos que se deben tener en cuenta sobre esta estrategia:
- Como las máquinas virtuales suelen estar conectadas a las redes de área local virtuales (VLAN) para que puedan desplazarse entre los centros de datos, es necesario que las VLAN también se extiendan entre los centros de datos locales. En algunos casos, esta opción no es recomendable.
- Por lo general, la red de gestión del sitio testigo (red de nodos de OpenShift) no se encuentra en la misma subred de capa 2 que la red de gestión de los centros de datos locales.
- Algunas corrientes de pensamiento no consideran que esta sea una solución de recuperación ante desastres completa, ya que el plano de control de OpenShift y el de la matriz de almacenamiento son dos puntos únicos de falla (SPOF). Los SPOF tienen un sentido lógico, porque, desde una perspectiva física, hay redundancia. Sin embargo, es cierto que un solo comando equivocado en OpenShift o en la matriz de almacenamiento puede, en teoría, eliminar todo el entorno. Por este motivo, esta arquitectura a veces se conecta en cadena con una arquitectura de recuperación ante desastres regional más tradicional para las cargas de trabajo más importantes.
- Si OpenShift funciona sin supervisión durante una situación de recuperación ante desastres, reprogramará automáticamente todas las máquinas virtuales del centro de datos afectado al mismo tiempo en el centro de datos en buen estado. Esto podría provocar un fenómeno conocido como "tormenta de reinicios". Hay una serie de funciones de Kubernetes que reducen este riesgo al identificar las aplicaciones que realizan la conmutación por error y el momento en que lo hacen. El concepto de las tormentas de reinicios se analizará en secciones posteriores.
Aspectos importantes sobre los costos
Con la replicación simétrica, ambos sitios deben estar suscritos por completo, ya que pertenecen a un solo clúster activo de OpenShift. Con respecto a la replicación unidireccional, cada sitio debe tener el doble de la capacidad que realmente utiliza, de manera que pueda asumir toda la carga del otro sitio si se inicia un proceso de conmutación por error.
Conclusión
La elección entre las arquitecturas de replicación unidireccional y simétrica sienta las bases para toda la estrategia de recuperación ante desastres en OpenShift Virtualization. Cada modelo tiene sus propias ventajas y desventajas en cuanto a la complejidad operativa, el costo de la infraestructura, las garantías de RPO y RTO y el potencial de la automatización. Independientemente de que elijas un diseño de clúster doble o ampliado, la arquitectura base debe ajustarse a las expectativas de la continuidad empresarial y a las limitaciones de la infraestructura. Con este panorama, la parte 2 cambia el enfoque de la infraestructura a la organización, es decir, va más allá del almacenamiento para analizar la forma en que se ubican, se reinician y se controlan las máquinas virtuales en las condiciones de un desastre.
Prueba del producto
Red Hat OpenShift Virtualization Engine | Versión de prueba
Sobre los autores
Bryon is a skilled infrastructure and software engineering specialist with deep expertise in AI/ML, Kubernetes, OpenShift, cloud-native architecture, and enterprise networking. With a strong background in storage technologies, infrastructure, and virtualisation, Bryon works across domains including system administration, AI model deployment, and platform engineering. He is proficient in C#, Golang and Python, experienced in container orchestration, and actively contributes to Red Hat-based solutions. Passionate about education and enablement, Bryon frequently develops technical workshops and training programs, particularly in AI/ML and DevOps. He is also a practising musician, blending his technical acumen with creative expression.
Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
Más como éste
Las amenazas de la inteligencia artificial se mueven rápido. Tus defensas también deberían hacerlo.
Más allá de la automatización: Motivos por los que el aumento de las vulnerabilidades de seguridad basadas en la inteligencia artificial exige una defensa técnica humana
Untangling Networks | Compiler
Technically Speaking | Defining sovereign AI with open source
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube