

InstructLab es un proyecto impulsado por la comunidad que permite simplificar la contribución a los modelos de lenguaje de gran tamaño (LLM) y mejorarlos mediante la generación de datos sintéticos. Esta iniciativa aborda varios desafíos que enfrentan los desarrolladores, como la complejidad de contribuir a los LLM, el problema de la expansión descontrolada que causan los modelos bifurcados y la falta de control directo de la comunidad. InstructLab cuenta con el respaldo de IBM Research y Red Hat y aprovecha los innovadores métodos de ajuste basados en datos sintéticos para mejorar el rendimiento y la accesibilidad. En esta sección, hablaremos sobre el problema actual y los desafíos técnicos que se encuentran a la hora de perfeccionar los modelos de forma tradicional, así como sobre el enfoque de InstructLab para resolverlos.
El desafío: los datos de baja calidad y el uso ineficiente de los recursos informáticos
A medida que aumenta la competencia en el sector de los LLM, parece que la tendencia es diseñar modelos cada vez más amplios que estén entrenados con grandes volúmenes de información del Internet público. Sin embargo, gran parte del Internet incluye información redundante o datos en lenguaje no natural que no contribuyen a las funciones principales del modelo.
Por ejemplo, el 80 % de los tokens que se utilizan para entrenar el modelo LLM GPT-3, en el que se basan las versiones posteriores, proviene de Common Crawl, que incluye una enorme variedad de páginas web. Se sabe que este conjunto de datos contiene una combinación de textos de alta y baja calidad, scripts y otros datos en lenguaje no natural. Se estima que una parte importante puede ser contenido poco útil o de baja calidad. (Análisis de Common Crawl)
Esta amplia red de datos no seleccionados provoca un uso ineficiente de los recursos informáticos, lo que genera costos de entrenamiento elevados que aumentan los gastos para los usuarios de estos modelos en el futuro. Además, su implementación en entornos locales presenta algunas dificultades.
Hemos detectado una cantidad cada vez mayor de modelos con menos parámetros en los que la calidad y la relevancia de la información son más importantes que la cantidad. Los modelos con una selección de datos más precisa e intencional tienen un mejor rendimiento, necesitan menos recursos informáticos y ofrecen resultados de mayor calidad.
La solución de InstructLab: perfeccionar la generación de datos sintéticos
InstructLab se distingue por su capacidad de generar grandes cantidades de datos que se utilizarán en procesos de entrenamiento, con solo un pequeño conjunto de datos para comenzar. Utiliza la metodología de ajuste a gran escala para chatbots (LAB), que mejora los LLM con pocos datos generados por personas y una sobrecarga informática mínima. De este modo, las personas pueden aportar datos relevantes de manera sencilla, los cuales se optimizan mediante la generación de datos sintéticos con ayuda de un modelo durante este proceso.

Características principales del enfoque de InstructLab:
Selección de datos basada en taxonomías
El proceso comienza con la creación de una taxonomía, es decir, una estructura jerárquica que organiza varias habilidades y áreas de conocimiento. La taxonomía sirve de plan para seleccionar los primeros ejemplos generados por personas, que funcionan como datos iniciales para el proceso de generación de datos sintéticos. Estos se organizan en una estructura que simplifica la exploración del conocimiento actual del modelo y la búsqueda de deficiencias que se puedan solucionar, con el fin de evitar la información redundante y desorganizada. Al mismo tiempo, permite destinar un modelo a un caso práctico o a necesidades específicas utilizando solo archivos YAML de formato sencillo de par de preguntas y respuestas.

Proceso de generación de datos sintéticos
A partir de los datos iniciales, InstructLab aprovecha un modelo maestro para crear nuevos ejemplos durante el proceso de generación de datos. Es importante tener en cuenta que este proceso no utiliza el conocimiento almacenado por el modelo maestro, sino que implementa plantillas de peticiones específicas que amplían en gran medida el conjunto de datos y garantizan que los ejemplos nuevos mantengan la estructura y la intención de los datos originales seleccionados por personas. La metodología LAB utiliza dos generadores de datos sintéticos específicos:
- Generador de datos sintéticos de habilidades (Skills-SDG): utiliza plantillas de peticiones para generar y evaluar instrucciones, así como para generar respuestas y realizar la evaluación final del par.
- Generador de datos sintéticos basado en el conocimiento: genera datos de instrucciones para las áreas que no cubre el modelo maestro mediante el uso de fuentes de conocimiento externas que sustentan los datos generados.
Este proceso reduce en gran medida la necesidad de anotar grandes cantidades de datos de forma manual. El uso de ejemplos pequeños, únicos y generados por personas como referencia permite seleccionar cientos, miles o millones de pares de preguntas y respuestas para influir en los pesos y los sesgos de los modelos.
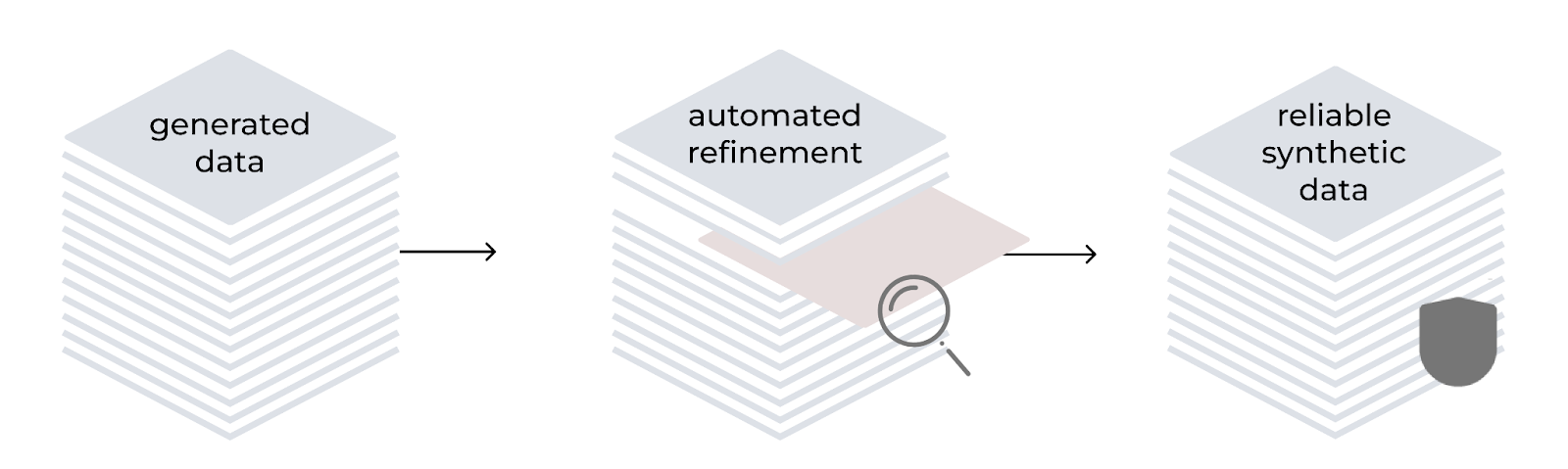
Perfeccionamiento automatizado
El método LAB incorpora un proceso de perfeccionamiento automatizado para mejorar la calidad y la fiabilidad de los datos de entrenamiento que se generan de forma sintética. Se basa en una taxonomía jerárquica y utiliza el modelo como generador y evaluador. El proceso implica generar instrucciones, filtrar contenido, generar respuestas y evaluar pares mediante un sistema de calificación de tres puntos. En el caso de las tareas basadas en el conocimiento, el contenido se basa en documentos fuente confiables, por lo que se abordan posibles imprecisiones en áreas especializadas.
Marco de perfeccionamiento de varias etapas
InstructLab implementa un proceso de entrenamiento de varias etapas para mejorar el rendimiento del modelo de forma gradual. Este enfoque permite mantener la estabilidad del entrenamiento, y un búfer de repetición de los datos evita el olvido catastrófico, de manera que el modelo pueda aprender y mejorar permanentemente. Los datos sintéticos generados se utilizan en un proceso de perfeccionamiento de dos etapas:
- Perfeccionamiento del contenido: integra la información fáctica nueva, dividida en entrenamientos con respuestas cortas y seguidas de respuestas largas y habilidades básicas.
- Perfeccionamiento de habilidades: mejora la capacidad del modelo para aplicar el conocimiento en diversas tareas y contextos, centrándose en las habilidades de composición.

El marco utiliza pequeñas tasas de aprendizaje, períodos de preparación prolongados y un gran lote de datos efectivo para garantizar la estabilidad.
Ciclo de mejora constante
El proceso de generación de datos sintéticos está diseñado para ser constante. A medida que se realizan nuevas contribuciones a la taxonomía, se pueden usar para generar datos sintéticos adicionales, lo que mejora aún más el modelo. Este ciclo constante de optimización garantiza que el modelo se mantenga actualizado y relevante.
Resultados e importancia de InstructLab
La importancia de InstructLab radica en su capacidad para lograr un rendimiento de vanguardia utilizando modelos maestro disponibles para el público en lugar de depender de los modelos propietarios. En cuanto a los indicadores, su metodología mostró resultados prometedores. Por ejemplo, cuando se implementó en Llama-2-13b (que generó Labradorite-13b) y en Mistral-7B (que generó Merlinite-7B), los modelos entrenados con LAB superaron a los mejores modelos perfeccionados a partir de sus respectivos modelos base según las puntuaciones de MT-Bench. También mantuvieron un rendimiento sólido en otros indicadores, como MMLU (prueba de comprensión del lenguaje de varias tareas), ARC (evaluación de las funciones de razonamiento) y HellaSwag (análisis de la inferencia del sentido común), entre otros.

Colaboración y accesibilidad basadas en la comunidad
Una de las ventajas más importantes de InstructLab es su naturaleza open source y el objetivo de democratizar la inteligencia artificial generativa para que todas las personas participen en la definición del futuro de los modelos. La interfaz de línea de comandos (CLI) está diseñada para ejecutarse en sistemas de hardware comunes, como las computadoras portátiles personales, que facilitan la incorporación de desarrolladores y colaboradores. Además, el proyecto InstructLab fomenta la participación de la comunidad al permitir que sus integrantes aporten nuevos conocimientos o habilidades a un modelo principal que se desarrolla con frecuencia y se lanza en Hugging Face. Consulta el modelo más reciente aquí.

El proceso de generación de datos sintéticos de InstructLab, que se basa en la metodología LAB, representa un avance importante en el campo de la inteligencia artificial generativa. Al mejorar los LLM de manera eficiente con nuevas funciones y áreas de conocimiento, este proyecto define un enfoque más colaborativo y efectivo para el desarrollo de la inteligencia artificial. Si deseas obtener más información, visita instructlab.ai o consulta esta guía de introducción para probar InstructLab en tu máquina.
Sobre los autores
Cedric Clyburn (@cedricclyburn), Senior Developer Advocate at Red Hat, is an enthusiastic software technologist with a background in Kubernetes, DevOps, and container tools. He has experience speaking and organizing conferences including DevNexus, WeAreDevelopers, The Linux Foundation, KCD NYC, and more. Cedric loves all things open-source, and works to make developer's lives easier! Based out of New York.
Legare Kerrison is a Technical Marketing Manager and Developer Advocate working on Red Hat's Artificial Intelligence offerings. She is passionate about open source AI and making technical knowledge accessible to all. She is based out of Boston, MA.
Más como éste
Preparándote para el Q-day: Cuatro pasos para preparar tu nube híbrida hoy
La nueva moneda de la velocidad empresarial
Container Roundup | Compiler
Untangling Networks | Compiler
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube