El primer paso para solucionar un problema de rendimiento es ser capaz de diagnosticar el problema. Si no tienes métricas de rendimiento y la habilidad de analizarlos, solo puedes basarte en conjeturas. Una de las herramientas comunes para analizar la monitorización en Linux es Performance Co-Pilot (PCP), y te enseñaremos como empezar a usar PCP en Red Hat Enterprise Linux para recoger y analizar datos para solucionar problemas de performance.
¿Qué es la monitorización de rendimiento?
Hay al menos dos tipos de monitorización:
-
Monitorización de disponibilidad: está mi sistema o servicio disponible?
-
Monitorización de rendimiento: que numeros hay sobre mi sistema, p. Ej. carga o rendimiento de red?
En este artículo veremos como PCP puede usarse para monitorización de rendimiento para solventar problemas del día a día. En un segundo artículo investigaremos la monitorización de métricas personalizadas, por ejemplo datos de aplicación, con PCP.
¿Por qué PCP y no la herramienta XYZ?
Podemos encontrar en detalle como PCP engloba distintas herramientas antiguas en este artículo. Analicemos algunos de los frameworks actuales:
-
Sar ha estado disponible en Red Hat Enterprise Linux durante años para recopilar datos de rendimiento. De uso simple, tiene problemas como que los ficheros sar que genera dependen de una versión en concreto, con lo que para analizar el fichero, es necesario instalar la versión exacta de sar con la que se ha generado el fichero.
-
Collectl es una herramienta pequeña e interesante escrita en Perl que cubre algunos casos de uso, pero no tiene la flexibilidad de herramientas más avanzadas.
-
Performance Co-Pilot (PCP) es nuestra solución recomendada para guardar datos de rendimiento en Red Hat Enterprise Linux. Como PCP existe desde hace más de 20 años, se han escrito muchos agentes también conocidos como Performance Metrics Domain Agents (PMDAs) - estos son los agentes que recopilaran los datos de rendimiento de diversas fuentes en nuestro sistema. PCP se incluye en los repositorios de Red Hat Enterprise Linux 6 y 7, y viene con muchas herramientas para analizar (pmdiff etc.) y presentar (pmchart, pmrep y demás) los datos recopilados. En Red Hat Enterprise Linux 7, los datos de rendimiento de PCP son parte de sosreports.
-
Prometheus es un reciente backend para guardar métricas. Tiene una buena integración con Kubernetes estando disponible en OpenShift 3.10 como Technology Preview. Prometheus cuenta además con integración de alertas (p. ej. “Avísame si la carga es alta”) y análisis de tendencias.
-
Netdata es también bastante reciente, se enfoca en la visualización de datos de rendimiento.
La visualización de las métricas de PCP usando graphite/grafana sería algo como esto:
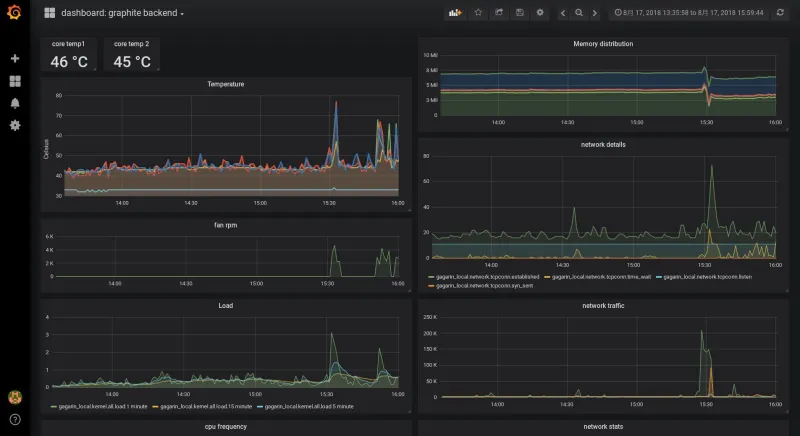
Nuestra instalación básica de PCP
Aunque los paquetes de PCP son parte de los repositorios principales de Red Hat Enterprise Linux, utilizaremos adicionalmente el paquete ‘pcp-zeroconf’ del repositorio ‘optional’. Esto configurará la monitorización básica de las métricas de sistema para nosotros. Comenzamos activando el repositorio ‘optional’:
# subscription-manager repos --enable=rhel-7-server-optional-rpmsLos componentes de PCP están divididos en distintos paquetes, permitiendote instalar únicamente aquello que realmente te hace falta. 'yum search pcp' listará todos los paquetes de PCP disponibles. El paquete 'pcp-zeroconf' instalará algunos paquetes como dependencia.
# yum install pcp-zeroconf pcp-system-toolsComo parte de la instalación, algunos componentes han sido configurados y arrancados, como se puede ver en la salida del comando ‘ps axf’:
-
El demonio pmcd trabaja como punto central de comunicación.
-
Los PMDA son usados por pmcd para monitorizar los datos de rendimiento (métricas).
-
pmlogger se utiliza para archivar datos de rendimiento.
Adicionalmente hemos instalado el paquete pcp-system-tools, que provee de herramientas para acceder a los datos de rendimiento. Y esto es todo, con estos comandos el sistema ya está monitorizando datos de rendimiento en el directorio /var/log/pcp/pmlogger!
¿Cómo acceder a los datos de rendimiento?
¿Qué podemos hacer ahora con esto? Llegados a este punto, podemos ejecutar
# pminfoy hacernos una idea de las métricas que los PMDA están actualmente monitorizando. Este comando se comunica directamente con el demonio pmcd, no accede a los ficheros guardados en el disco. Los parámetros ‘-fT’ muestran ayuda y los valores de las métricas actuales, si las hubiera.
pcp-zeroconf ha configurado pmlogger para que archive los datos bajo /var/log/pcp/pmlogger/<hostname>. Los ficheros que terminan con ‘0’ en el directorio son ficheros archivados, con el siguiente comando podemos verificar que métricas se están archivando:
# pminfo -a <fichero_archive> | less
El parámetro adicional ‘-a’ instruye a pminfo para que utilice un archivo. Utilizando
# pmrep kernel.cpu
podemos acceder a datos actualmente disponibles de la métricas kernel.cpu.* del sistema. Utilizando
# pmrep -a <archivefile> kernel.cpu
tenemos acceso a los mismos datos pero desde un archivo, siempre y cuando pmlogger esté configurado para guardar las métricas..
Los usuarios pueden crear vistas con las métricas de PCP que más les pueda interesar. Por ejemplo, la vista ‘atop’ se creó usando métricas de PCP. El comando 'pcp atop' puede usarse para tener un vista comparable a la herramienta ‘atop’ pero utilizando métricas PCP. ‘pcp iostat’ proveería datos de E/S.
Los archivos de PCP nos permiten tener una flexibilidad adicional - acceder a datos archivados de rendimiento con la vista ‘atop’. Tras recibir una llamada tipo ‘hemos tenido problemas en el sistema XYZ sobre las 10:40’ puedes acceder al sistema o copiar los archivos PCP del sistema, y utilizar
# pcp atop -r <archivefile> -b 10:40
..para ver la vista atop del sistema, con datos de las 10:40.
¿Qué métricas son importantes?
Imaginemos que recibimos una alerta sobre un problema en un sistema sobre las 10:40. Recogemos los ficheros PCP y lo investigamos. Cuantas métricas hay en este archivo?
[chris@rhel7u5a ~]# pminfo -a 20180815.09.28.0|wc -l 606 [chris@rhel7u5a ~]#
606 métricas para un Red Hat Enterprise Linux 7.5 estándar, y más de un millar en un Red Hat Enterprise Linux 7.6!
Necesitaremos ayuda para encontrar qué métricas son las interesantes para investigar. En otras palabras, qué métricas han sido distintas sobre las 10:40? ‘pmdiff’ podría ayudarnos aquí. Especificaremos una franja horario donde el sistema ha actuado de manera normal con los parámetros -S y -T, y una franja horaria donde el problema ha ocurrido con con -B y -E.
[chris@rhel7u5a ~]# pmdiff -S 09:30 -T 10:30 -B 10:39 -E 10:42 20180815.09.28.0 20180815.09.28.0 20180815.09.28.0 Ratio Metric-Instance 09:30-10:30 10:39-10:42 0.000 0.055 |+| kernel.percpu.cpu.user ["cpu2"] 0.001 0.203 >100 kernel.percpu.cpu.sys ["cpu2"] 0.005 0.251 50.20 kernel.all.cpu.sys 0.002 0.068 34.00 kernel.all.cpu.user 0.002 0.068 34.00 kernel.all.cpu.vuser 0.001 0.034 34.00 kernel.percpu.cpu.sys ["cpu1"] 0.004 0.099 24.75 kernel.all.load ["1 minute"] 0.810 18.75 23.15 xfs.perdev.allocs.free_block ["/dev/mapper/root"] 11906 197904 16.62 xfs.perdev.xstrat.bytes ["/dev/mapper/root"] 2.919 48.32 16.55 xfs.perdev.allocs.alloc_block ["/dev/mapper/root"] 26.88 270.0 10.04 kernel.percpu.intr ["cpu2"] 0.001 0.009 9.00 kernel.percpu.cpu.user ["cpu1"] 0.002 0.014 7.00 kernel.percpu.cpu.sys ["cpu3"] [..]
Parece que la CPU ha estado atareada a esa hora, y también el sistema de ficheros. Busquemos más sobre los procesos que estaban ejecutando en ese momento.
[chris@rhel7u5a ~]# pminfo -T -a 20180815.09.28.0 proc|less
Las métricas proc.runq.runnable y proc.runq.blocked parecen interesantes.
[chris@rhel7u5a ~]# pmrep -a 20180815.09.28.0 -S @10:41:15 -T @10:43:18 \ -p proc.runq.runnable proc.runq.blocked | less p.r.runnable p.r.blocked count count 10:41:15 2 0 10:41:16 2 0 10:41:17 3 0 10:41:18 3 0 10:41:19 3 0 [..] 10:43:15 3 0 10:43:16 3 0 10:43:17 2 0 10:43:18 2 0
Parece que normalmente hay 2 procesos ejecutables en el sistema, pero durante el periodo problemático había un tercer proceso, que desaparece pasados unos minutos. pmlogger está archivando la lista de procesos para nosotros. Ejecutando ‘pminfo -T proc’, hemos visto la métrica proc.psinfo.sname, que nos provee con el estado de ejecución de todos los procesos. ¿Qué procesos se estaban ejecutando justo antes del problema, durante el problema, y justo después?
[chris@rhel7u5a ~]# pminfo -f -a 20180815.09.28.0 -O @10:40:15 \ proc.psinfo.sname | grep R inst [7115 or "007115 /var/lib/pcp/pmdas/proc/pmdaproc"] value "R" [chris@rhel7u5a ~]# pminfo -f -a 20180815.09.28.0 -O @10:41:19 \ proc.psinfo.sname | grep R inst [7115 or "007115 /var/lib/pcp/pmdas/proc/pmdaproc"] value "R" inst [18345 or "018345 md5sum"] value "R" [chris@rhel7u5a ~]# pminfo -f -a 20180815.09.28.0 -O @10:43:18 \ proc.psinfo.sname | grep R inst [7115 or "007115 /var/lib/pcp/pmdas/proc/pmdaproc"] value "R" [chris@rhel7u5a ~]#
Las 3 veces podemos ver nuestros procesos PMDA ejecutándose para la monitorización, y durante la franja problemática un proceso adicional ‘md5sum’. Desafortunadamente no estamos guardando la métrica proc.schedstat.cpu_time por defecto, esa métrica nos mostraría como el proceso md5sum era el proceso que mayor consumo de CPU tenía a las 10:41. Pmlogger puede ser configurado para guardar esta métrica.
Podemos ver más detalles sobre el proceso con los datos de PCP, también el propietario del proceso y preguntar sobre el usuario para sus otras actividades. ¡Gracias por por ayudarnos con este problema de rendimiento PCP!
Reflexión final
Hemos visto lo fácil que es instalar y ejecutar PCP en Red Hat Enterprise Linux, cómo acceder a datos en vivo o a métricas archivadas. ¿Qué tal monitorizar datos personalizados de nuestras aplicaciones, sensores de temperatura o los datos SMART de un disco? Investigaremos la monitorización de métricas personalizadas en un artículo posterior, y también cómo crear gráficas de los datos recogidos.
-
Introduction to storage performance analysis with PCP proporciona una visión general sobre PCP
-
manpages recomendados: PCPIntro(1), pminfo(1), pmrep(1), pmdiff(1)
Este artículo está disponible localizado en 4 versiones: Aleman, Ingles y Japones.
-
Click here to read this article in English.
-
Klicken Sie hier, um diesen Artikel auf Deutsch zu lesen.
-
この記事の日本語版があります。
Sobre el autor

Christian Horn is a Senior Technical Account Manager at Red Hat. After working with customers and partners since 2011 at Red Hat Germany, he moved to Japan, focusing on mission critical environments. Virtualization, debugging, performance monitoring and tuning are among the returning topics of his daily work. He also enjoys diving into new technical topics, and sharing the findings via documentation, presentations or articles.
Más como éste
Friday Five — January 23, 2026 | Red Hat
Zero trust workload identity manager generally available on Red Hat OpenShift
Data Security 101 | Compiler
Technically Speaking | Build a production-ready AI toolbox
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube