パフォーマンスモニタリングとは何ですか
モニタリングには、少なくとも種類が二つあります:
-
アベイラビリティモニタリング: あるシステムやサービスが動いているかどうか
-
パフォーマンスモニタリング:システム関係の値は何ですか。例:システムの負荷、ネットワークのスループット
この記事では、Performance Co-Pilot (PCP) をパフォーマンスモニタリングに使っていかに簡単に日々の問題を解決できるかを見ていきます。次の記事では、例えばアプリケーションのデータのようなカスタムのメトリクスを PCP を使ってモニタリングする方法を見ていきます。
どうしてPCPにしましたか?
PCPと従来のツールの関係はこちらをご覧下さい。現在のソフトと比べましょう:
-
sar は昔から Red Hat Enterprise Linux (RHEL) に入っているソフトです。使い方が簡単ですが、様々な問題があります。例えば、あるバージョンの sar で保存されたデータを分析するためには、全く同じバージョンの sar をインストールする必要があります。
-
collectl collectl は小さくて便利な Perl スクリプトです。色々なケースで役に立ちますが、他のツールのような柔軟性に欠けます。
-
Performance Co-Pilot (PCP) は RHEL 上で、パフォーマンスデータを保存する為に、レッドハットのおすすめのソフトです。PCP が20年以上前に誕生して以来、様々な Performance Metrics Domain Agents (PMDA) が開発されました。PMDA はシステムの様々なソースからパフォーマンスデータを収集するエージェントです。PCP は RHEL6 と RHEL7 の標準レポジトリに含まれます。pmdiff などの分析のためのツールや pmchart、pmrep など保存したデータを表示するためツールも入っています。RHEL7 では、PCP のパフォーマンスデータは sosreport にも含まれます。
-
最近、prometheus というソフトが流行っています。Kubernetes とよく統合されており、OpenShift 3.10 に TechPreview として 入っています。「システムの負荷が高くなった」などの通知や将来のデータの予想も出来ます。
-
netdata も最近のソフトです。パフォーマンスデータを直接視覚化する機能が多いです。
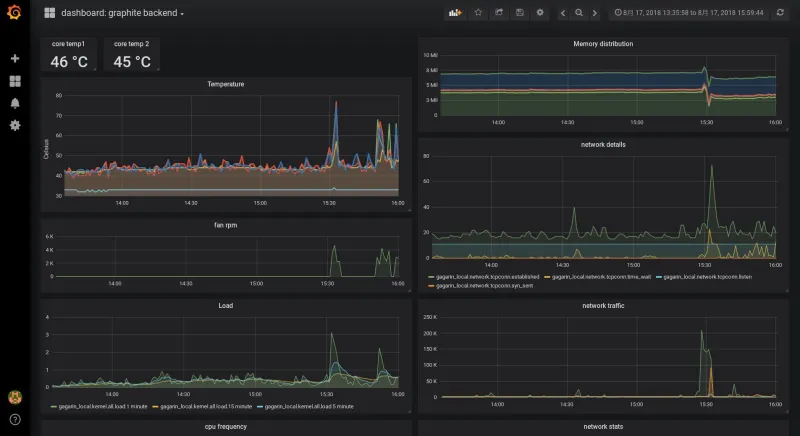
graphite/grafana を使って PCP のメトリクスを視覚化するとこのようになります:
基本的な PCP のインストール
PCPパッケージはRHEL の標準レポジトリに入っていますが、optional チャネルの pcp-zeroconf パッケージも使いましょう。そのパッケージが基本的なシステムのメトリクスを設定してくれます。まずは optional レポジトリを有効化しましょう。
# subscription-manager repos --enable=rhel-7-server-optional-rpmsPCP のコンポーネントは様々なパッケージに分散されているので、必要なものだけをインストールする事ができます。「yum search pcp」は PCP のパッケージの一覧を出力します。pcp-zeroconf は依存関係で他のパッケージもインストールします。
# yum install pcp-zeroconf pcp-system-toolsインストールの過程で、いくつかのコンポーネントが既に設定され、起動しています。ps axf を実行すると、そのプロセスが表示されます。
-
pmcd デーモンは PCP における通信の中心として動作します。
-
PMDA は、パフォーマンスデータ(metrics)を監視し pmcd に報告します
-
pmlogger はパフォーマンスデータをディスクに保存します
さらに、パフォーマンスデータにアクセスするためのツールが入っている pcp-system-tools パッケージをインストールしました。たったこれだけで、システムはすでにパフォーマンスデータを /var/log/pcp/pmlogger ディレクトリに保存しています!
パフォーマンスデータはどうやって読めば良いですか?
ここまでで何ができるでしょうか。現時点で
# pminfoを実行し PMDA が現在監視しているメトリクスを知ることができます。このコマンドは単に pmcd デーモンと通信しているだけであり、ディスクに保存されたデータにアクセスしているわけではありません。「-fT」パラメータでヘルプと現在のメトリクス値を表示することができます。
pcp-zeroconf によって、pmlogger が /var/log/pcp/pmlogger/<hostname> 配下にデータを保存するよう設定が行われました。そのディレクトリにおいて末尾が 「0」 のファイルがアーカイブファイルです。次のコマンドを使うと、アーカイブされたメトリクスを見ることができます。
# pminfo -a <archivefile> | less「-a」を追加することで、pminfo がアーカイブファイルを使うようになります。それから
# pmrep kernel.cpuを使うと、現在の kernel.cpu 関係のメトリクスが見えます。
# pmrep -a <archivefile> kernel.cpuを使うと、pmlogger がそれらのメトリクスを記録するよう設定されていれば、同じメトリクスをアーカイブファイルから読めます。
ユーザーはメトリクスを使って、必要なツールが作成出来ます。例えば、atop というコマンドが PCP metrics を使って作成されました。「pcp atop」と実行すると、PCP のメトリクスを使って、atop と同等の出力が得られます。「pcp iostat」と実行すると、I/O のデータが読めます。
PCP のアーカイブデータにより更なる柔軟性が得られます。「pcp atop」で過去のデータを参照することができるのです。例えば、「システム XYZ で 10時40分頃にパフォーマンスの問題があった」との電話が来たら、そのシステムにログインするか、PCP のアーカイブファイルをそこから転送するかして、次のコマンドを使えます。
# pcp atop -r <archivefile> -b 10:40そうすることで、そのシステムにおける10時40分からの atop の出力を見ることができます。
どの metrics が大切ですか?
例えば上の例のように10時40分頃のシステムの問題の報告を受けたと想像してみましょう。PCP アーカイブファイルを自分のシステムにコピーして、調べます。メトリクスはどのぐらい入っていますか。
[chris@rhel7u5a ~]# pminfo -a 20180815.09.28.0|wc -l
606
[chris@rhel7u5a ~]#
RHEL 7.5 ではデフォルトで 606 のメトリクスが、そして RHEL 7.6 では 1000 以上入っています!
このうちどのメトリクスが調査の役に立つでしょうか。つまり、どの metrics が10時40分に異常でしたか。
pmdiff を使いましょう。システムが正常に動作していた時間帯を「-S」と「-T」パラメータで、問題が起こっていた時間帯を「-B」と「-E」で指定しましょう。
[chris@rhel7u5a ~]# pmdiff -S 09:30 -T 10:30 -B 10:39 -E 10:42 20180815.09.28.0
20180815.09.28.0 20180815.09.28.0 Ratio Metric-Instance
09:30-10:30 10:39-10:42
0.000 0.055 |+| kernel.percpu.cpu.user ["cpu2"]
0.001 0.203 >100 kernel.percpu.cpu.sys ["cpu2"]
0.005 0.251 50.20 kernel.all.cpu.sys
0.002 0.068 34.00 kernel.all.cpu.user
0.002 0.068 34.00 kernel.all.cpu.vuser
0.001 0.034 34.00 kernel.percpu.cpu.sys ["cpu1"]
0.004 0.099 24.75 kernel.all.load ["1 minute"]
0.810 18.75 23.15 xfs.perdev.allocs.free_block ["/dev/mapper/root"]
11906 197904 16.62 xfs.perdev.xstrat.bytes ["/dev/mapper/root"]
2.919 48.32 16.55 xfs.perdev.allocs.alloc_block ["/dev/mapper/root"]
26.88 270.0 10.04 kernel.percpu.intr ["cpu2"]
0.001 0.009 9.00 kernel.percpu.cpu.user ["cpu1"]
0.002 0.014 7.00 kernel.percpu.cpu.sys ["cpu3"]
[..]
これによると、当時 CPU やファイルシステムがビジーだったようです。その時のプロセスについて調べましょう。
[chris@rhel7u5a ~]# pminfo -T -a 20180815.09.28.0 proc|less表示されたメトリクスの proc.runq.runnable とproc.runq.blocked が面白そうです。
@rhel7u5a ~]# pmrep -a 20180815.09.28.0 -S @10:41:15 -T @10:43:18 \
-p proc.runq.runnable proc.runq.blocked | less
p.r.runnable p.r.blocked
count count
10:41:15 2 0
10:41:16 2 0
10:41:17 3 0
10:41:18 3 0
10:41:19 3 0
[..]
10:43:15 3 0
10:43:16 3 0
10:43:17 2 0
10:43:18 2 0
出力されたデータによると、普段は2つのプロセスが runnable ステータスになっているものの、問題発生時にはrunnableなプロセスが3つ存在しており、数分後にまた2つになっているようです。pmlogger は全部のプロセスの名前も保存してくれます。「pminfo -T proc」と実行すると、「proc.psinfo.sname」というメトリクがあります。これにより全てのプロセスの状態を知ることができます。問題発生の直前、問題発生中、問題発生後にどのプロセスが実行中だったか見てみましょう。
[chris@rhel7u5a ~]# pminfo -f -a 20180815.09.28.0 -O @10:40:15 \
proc.psinfo.sname | grep R
inst [7115 or "007115 /var/lib/pcp/pmdas/proc/pmdaproc"] value "R"
[chris@rhel7u5a ~]# pminfo -f -a 20180815.09.28.0 -O @10:41:19 \
proc.psinfo.sname | grep R
inst [7115 or "007115 /var/lib/pcp/pmdas/proc/pmdaproc"] value "R"
inst [18345 or "018345 md5sum"] value "R"
[chris@rhel7u5a ~]# pminfo -f -a 20180815.09.28.0 -O @10:43:18 \
proc.psinfo.sname | grep R
inst [7115 or "007115 /var/lib/pcp/pmdas/proc/pmdaproc"] value "R"
[chris@rhel7u5a ~]#
モニタリングのための PMDA プロセスが3回とも表示されており、それに加えて問題発生時のみ md5sum プロセスも表示されています。残念ながら、デフォルトの設定では proc.schedstat.cpu_time という metric を記録していません。仮に記録していれば、この md5sum プロセスが10:41に最も多くの CPU 時間を使ったという事が分かりました。pmlogger の設定でそのメトリクスを記録することもできます。
保存された PCP データを使って、より詳細な情報を得られます。プロセスのユーザーの名前が分かったら、そのユーザーにアクティビティーの背景について聞いてみましょう。。PCP さん、助けてくれてありがとう!
まとめ
RHEL で PCP を簡単に使えるという事が分かりました。今現在のデータや保存された(or アーカイブ)データにもアクセスしました。これから、自分のソフトの metric かシステムの温度センサーかディスクの温度をモニターしたら、どうですか。次回の記事では、カスタムメトリクスのモニタリングや収集したデータからのグラフの作成について見ていきます。
-
この記事では、PCP の概要をご紹介しています: Introduction to storage performance analysis with PCP
-
おすすめのmanページ:PCPIntro(1), pminfo(1), pmrep(1), pmdiff(1)
この記事は様々な言語でご覧いただけます。
-
Click here to read this article in English.
-
Klicken Sie hier, um diesen Artikel auf Deutsch zu lesen.
執筆者紹介

Christian Horn is a Senior Technical Account Manager at Red Hat. After working with customers and partners since 2011 at Red Hat Germany, he moved to Japan, focusing on mission critical environments. Virtualization, debugging, performance monitoring and tuning are among the returning topics of his daily work. He also enjoys diving into new technical topics, and sharing the findings via documentation, presentations or articles.
類似検索
エージェント型のパラドックスとハイブリッド AI の事例
過去を管理するのをやめて、IT の未来を構築しましょう
Collaboration In Product Security | Compiler
Keeping Track Of Vulnerabilities With CVEs | Compiler
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください