The success of edge computing depends on improving efficiencies at the scale at which it is deployed, and power is its single most significant operational expense. However, existing approaches to edge computing tie compute resources to specific closed cloud ecosystems, and are limited in hardware specifications to that which fits a predetermined business model based on increased consumption rather than efficiency.
Power is arguably the single most significant operational expense of a data center, which carries through to micro data centers at the edge. Rising energy costs can drastically impact operating margins and the financial performance of enterprises and telecommunications providers alike. It would make sense then, that if power consumption becomes more efficient, capital and operating expenses can be reduced. This efficiency is crucial in the move to edge computing, but it requires the ability to observe, analyze and optimize power consumption architecture. To do this, we address the issue from three perspectives:
- Dynamic scaling of computing resources, based on observed metrics
- New advancements in Software Defined Memory (SDM), which allow consolidation of large amounts of dynamic random access memory (DRAM) to fewer servers, saving excess power of refresh cycles
- Edge-native architecture that can interconnect for availability, reducing the need for redundant hardware (and power) at each site.
Edge design can change compute
Combining Red Hat OpenShift with SDM and ephemeral overlay networks has the potential to broaden compute design from simply cloud-assumptive to also include edge-assumptive patterns. Edge deployments have keen restrictions for power and performance to make them useful, engendering the need for superior responsiveness to specialized needs. Rather than providing generic cloud infrastructure, susceptible to latency across distance, this approach can dynamically configure resources to better meet these exacting and specific needs, responsive to the most challenging latency obligations facing edge workloads, including AI.
Coupling decentralized compute with restrictions for size, space, and power, and latency represents a significant challenge to basic cloud infrastructure, as well as an opportunity for locally adaptive AI across many of the most diverse and restrictive of application terrains.
Red Hat supports this design in a multitude of ways, including an architecture based on Kove:SDM™ from Kove with Red Hat hybrid cloud technologies, such as Red Hat Service Interconnect, based on the Skupper project.
Dynamic scaling of compute
The Kubernetes-based Efficiency Power Level Exporter (Kepler) project was founded by Red Hat’s emerging technologies group with early contributions from IBM Research and Intel. Kepler uses cloud-native methodologies to capture power-use metrics. These metrics can be used by service providers to optimize energy consumption as they work to address their evolving sustainability objectives1. Recent testing has shown power savings of 30% by reducing the CPU frequency based on demand while running in power save mode. In edge computing, where there are likely to be significant stretches of idleness, this becomes significant, because, applied during idle time, this type of savings does not even impact the application.
Advancements in SDM
SDM or virtualized memory, is an architecture that allows servers to draw exactly what they need from a shared memory pool. These pools can contain large amounts of memory that would greatly exceed memory modules contained within a single server, or dynamically and temporarily add memory to servers when they need a bit more .
Kove has spent two decades building SDM technology. As a Red Hat partner, Kove:SDM™ is optimized for use with Red Hat products, and the Kove Operator for Red Hat OpenShift enables very seamless access for all hosts in a cluster to SDM with no software modification. Kove has also spent years designing, developing, perfecting and patenting methods for extending CPU cache hierarchies so that SDM performance is not affected by memory pool distance.
Kove:SDM™ is more efficient in terms of resource utilization as it can dynamically adjust memory capacity to differing requirements and burst on-demand when and however needed. Service providers who utilize Kove:SDM™ within their network deployments can benefit from increased power savings within their network infrastructure. This is because by reducing the amount of memory in most of the servers and consolidating it into only a small number of memory target servers, the amount of power used in DRAM refresh is reduced. Further, due to the increased locality of reference provided by these smaller servers, we have measured that the memory frequency used does not cause measurable performance differences, which can drive additional savings.
Using these two memory optimization techniques can yield 20% power savings, independently of compute scaling. In other words, even if one needs to run an application at full speed without any compute power optimization, it is still possible to achieve this 20%. Combining the techniques can provide potentially 50% total power savings. We would like to acknowledge the tremendous assistance provided in obtaining these results from SuperMicro, whose collaboration allowed us to use their BigTwin systems to measure these results.
Figure 1. Test Description [Variables: CPU Governor, Memory Frequency, Idle vs. Busy]
![Figure 1. Test Description [Variables: CPU Governor, Memory Frequency, Idle vs. Busy]](/rhdc/managed-files/ultra-low-power-architecture-edge-img1.png)
Figure 2. Test Results [Variable Isolation: CPU Governor, Memory Frequency, CPU Governor + Memory Frequency]
![Figure 2. Test Results [Variable Isolation: CPU Governor, Memory Frequency, CPU Governor + Memory Frequency]](/rhdc/managed-files/ultra-low-power-architecture-edge-img2.png)
Figure 3. Test Performance Data
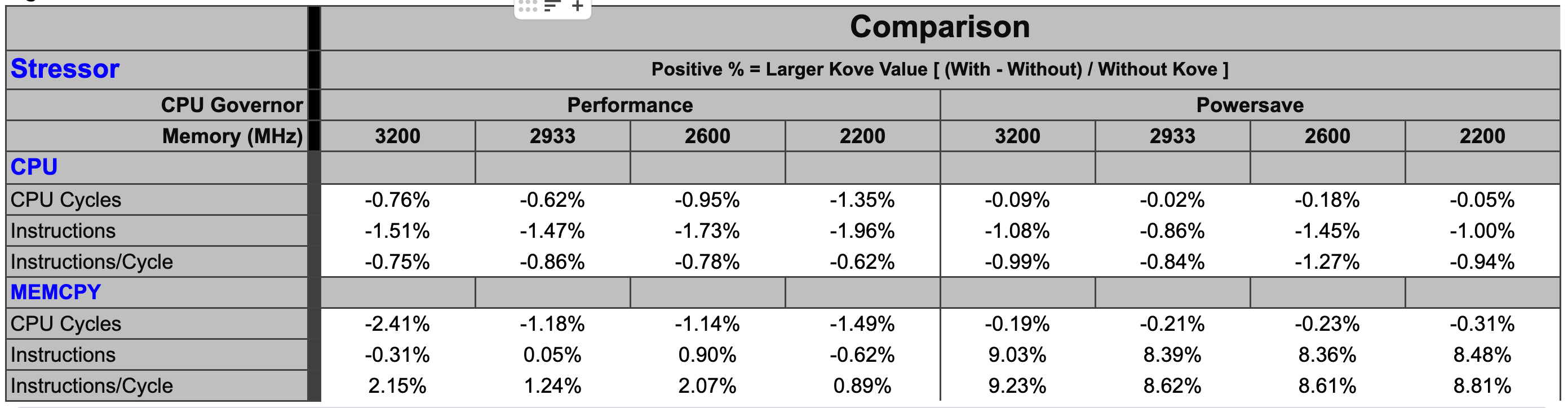
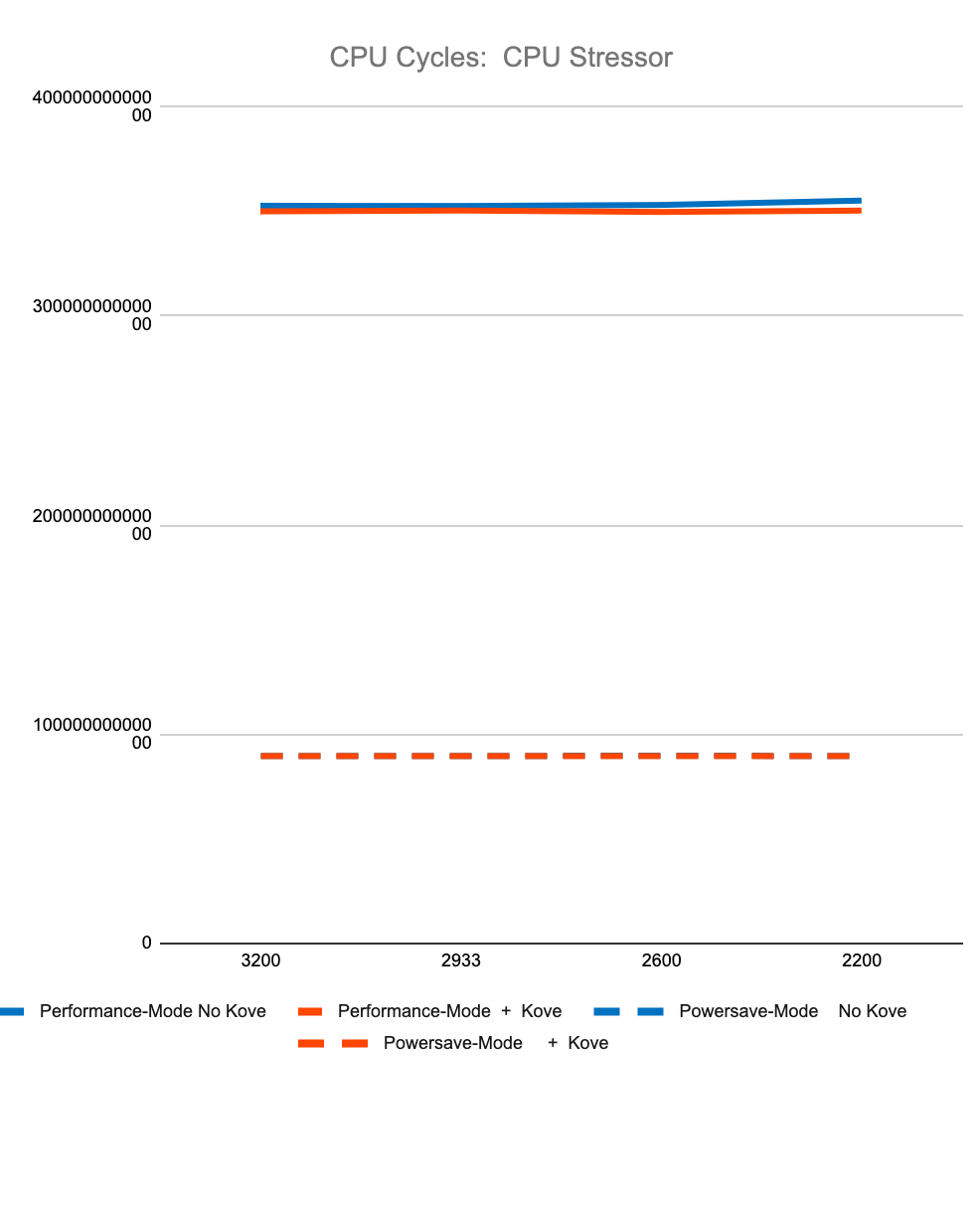
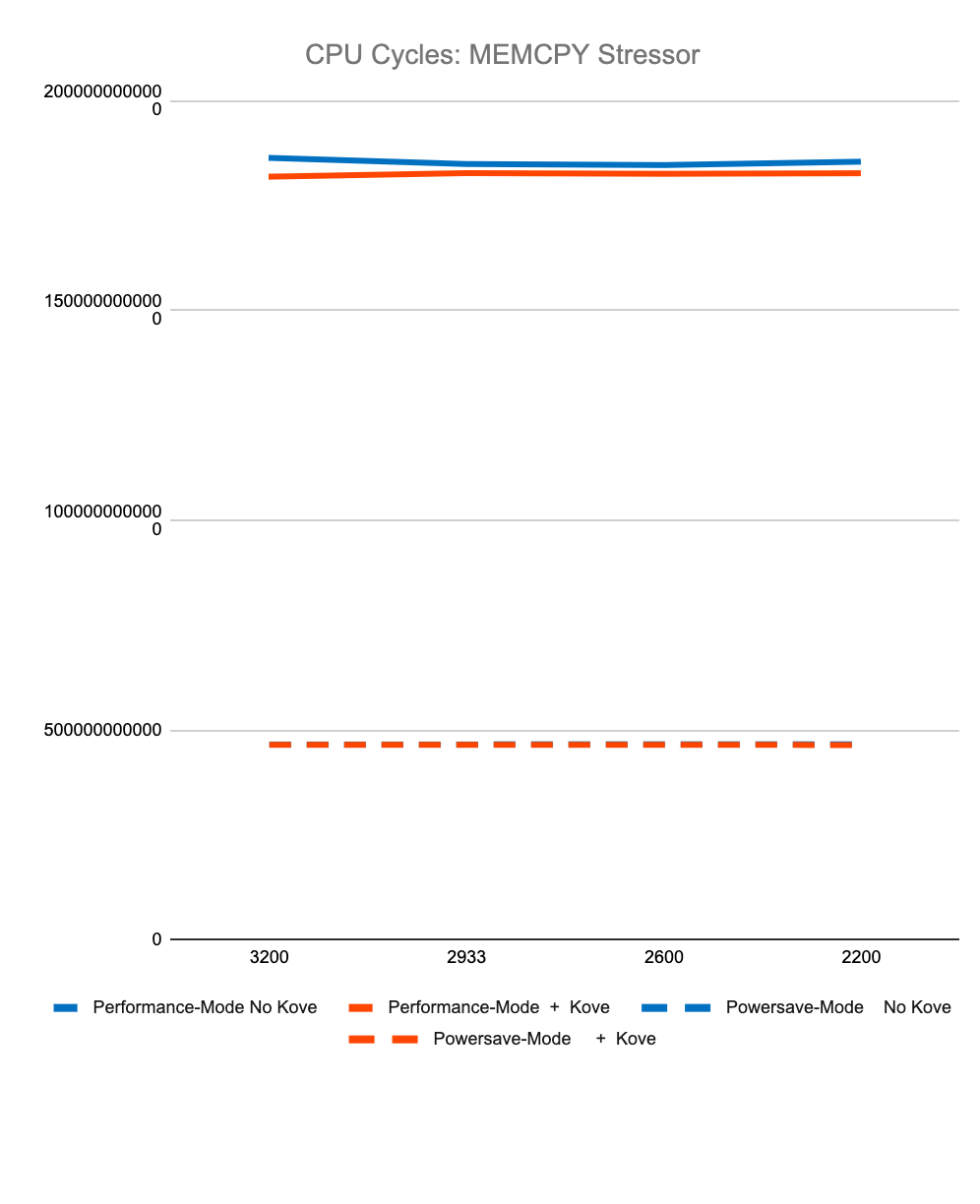
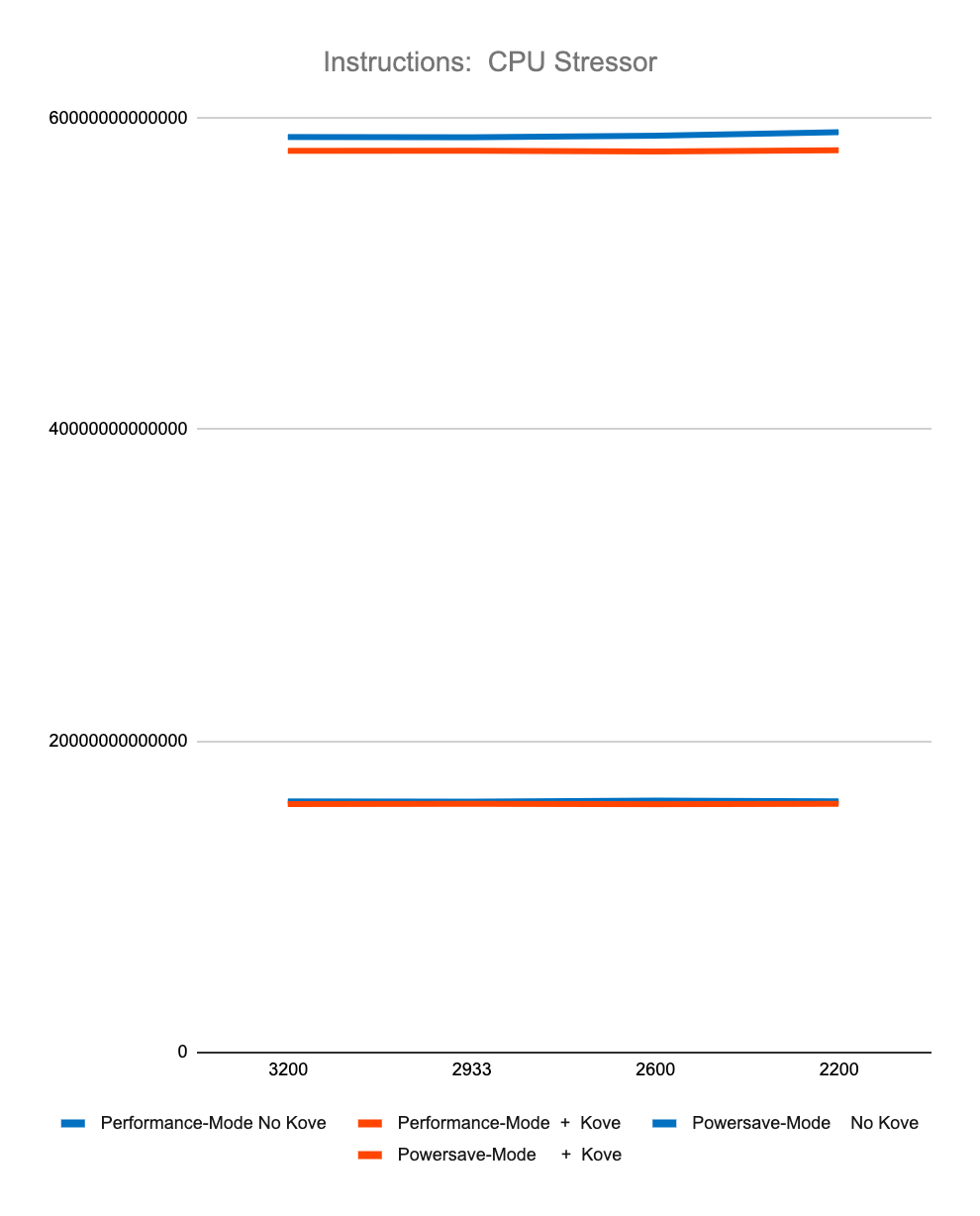
Figure 3 shows less than 2% difference in StressNG tracked metrics when adding Kove:SDM™, in terms of CPU cycles, instructions, and instructions per cycle, for both CPU and memory. These results were tested over billions of operations, 7 times, and then averaged to eliminate experimental skew.
|
|
|

|

|
|
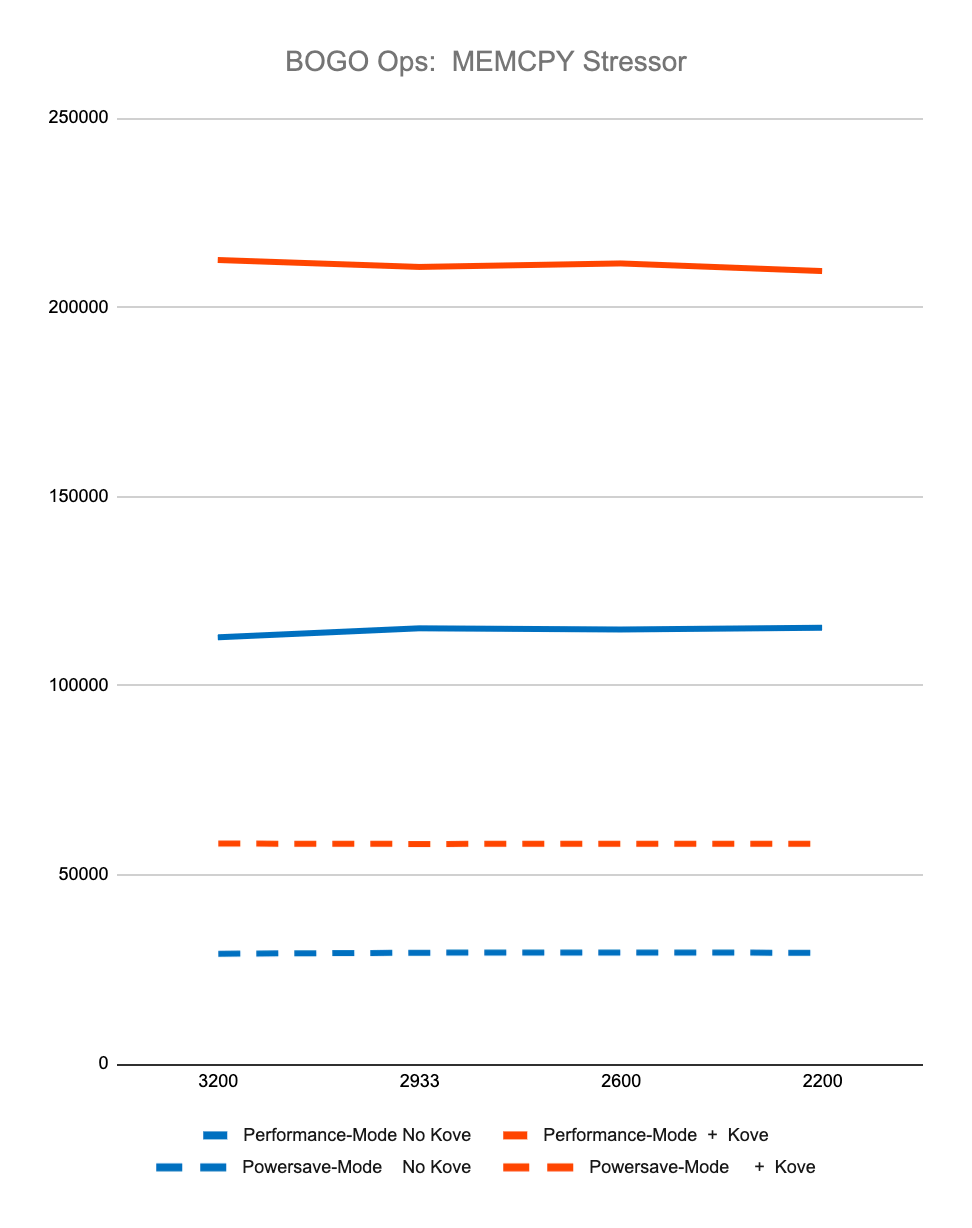
The first 4 graphs above show consistently that regardless of memory speed of pooled memory (3200 – 2200 MHz), pooled memory using Kove:SDM™ has negligible performance impact for CPU performance, and in fact can even be faster than local memory for memory performance.
Graph 5 shows the relative amount of CPU overhead for using the Kove:SDM™ algorithm. Graph 6 shows that, as a result of using this algorithm, there is a massive improvement in efficiency of memory access, due to the optimizations of CPU cache hierarchies mentioned earlier. One can think about this as being similar to what happens in storage virtualization, where spindles of multiple spinning disks are optimized for striping, yielding faster performance. But in this case, this happens with memory, with nanosecond consistency. This delivers superior to local memory performance, not just storage or “storage-class” memory, but actual local DRAM.
These results were measured over billions of tests, with different speed memory, consistently showing superior to local DRAM memory performance. Specifically, using StressNG’s measurement of relative performance (BOGO Ops):
CPU Stressor, results in:
5.80% lesser performance with Kove in Performance-mode
5.66% lesser performance with Kove in Powersave-mode
Memory Stressor, is:
88.52% faster with Kove compared to local memory
99.96% faster with Kove compared to local memory
All results were tested over billions of operations, run 7 times, and then averaged, to eliminate experimental skew.
Edge-native availability architecture that can be interconnected with stronger security
Telco networks traditionally needed duplicate hardware (and paid its associated power cost) to achieve high availability. With edge computing, it is possible to consider a new approach, where nearby edge environments can be interconnected and act as fail over sites for each other. Advantages of such an active-to-active approach are that the capacity is always available rather than sitting idle, and hardware is not wasted when designated only as spares. Unlike centralized data centers, in edge computing it is challenging to do this with traditional network architectures, due to the differing IP addresses of each site and the associated management complexity.
Traditional IP-based security techniques are not well-suited for ephemeral networking overlays and dynamic resource combinations on the edge. In traditional IT design, security policies are centralized within VPN and firewall functions. These policy mechanisms become extremely complex, error-prone and time-consuming as the number of sites increase, as happens in edge environments. This can be especially true when dealing with any-to-many resource configurations, where one edge cluster may need to share data or computation with any other edge cluster across a city.
Additionally, the capex and opex of stranding memory across cities and countries, drives cost and reduces the opportunity for AI to expand utility at the edge, leading to questions as to the ROI on today’s AI investments. AI always needs memory, and if memory is constrained to servers, server costs rise to support AI adoption.
Using Kove:SDM™ with Red Hat OpenShift, memory can be shared across resources, providing an opportunity to expand utilization for memory-hungry applications by sharing memory resources. It is the perfect complement to modern, dynamic security technologies like Red Hat Service Interconnect, because when a service is redirected to a different cluster to be processed, the cluster does not need to be massively over-provisioned to handle it.
Red Hat Service Interconnect creates an abstraction layer with greater security between the applications and their networks without requiring any virtual private network (VPN) or special firewall privileges. This layer can span edge, hybrid and multicloud environments regardless of their location and connects applications, including legacy applications that will not be moved to a cloud or Kubernetes environment, as part of a zero-trust network access (ZTNA) framework, as IP addresses are never published. Application portability across different environments is also achievable, as the abstraction layer is not locked to any associated networking.
With this abstraction layer, service providers can create locationless services that exist both in a primary site and in other sites. In case of failure, another instance in another site is selected without any additional network or load balancer orchestration. Furthermore, one can also horizontally scale network deployments. Traditionally, scalability is achieved vertically by adding more servers at a location, but network edge locations often have space and power constraints. Horizontal scaling allows service providers to interconnect their various diverse edge locations, effectively creating a constellation of distributed edge nodes that can work together and pool resources independently of any centralized cloud.
How Red Hat can help
Red Hat’s open hybrid cloud strategy allows service providers to run any application or workload with greater consistency across nearly any footprint and cloud environment. Utilizing our open hybrid cloud technologies gives service providers the ability to deliver current and future service and applications while optimizing their energy consumption..
Interconnect all of your data
Red Hat’s ultra-low power architecture and platform for edge and multi-access edge computing (MEC) deployments builds on the latest innovations from our open hybrid cloud strategy (built on the innovation of open source projects like Kepler and Skupper) and our robust partner ecosystem to build a power-efficient edge platform that can interconnect data regardless of location.
Our solution creates an application-aware fabric that has the ability to interconnect data and applications together between different providers and environments. These include Amazon Web Services (AWS) Elastic Kubernetes Service (EKS), Microsoft Azure Kubernetes Service (AKS), Google Cloud Platform (GCP) Google Kubernetes Engine (GKE), VMware Tanzu and Alibaba Cloud Container Service for Kubernetes (ACK).
More simplicity for data access
Having the ability to access data regardless of location is often expensive to implement due to high levels of design and integration work needed, further exacerbated when dealing with networks at scale. We simplify this with Red Hat Service Interconnect by routing application data with greater security at a higher level within the protocol stack.
Create intelligence at the edge
With an application-aware fabric, details concerning an application’s behavior can be integrated with other technologies such as AI. This generates insights that can be used for further improvements, and which can be fed into federated learning models. These AI applications can then be hosted at the various cloud locations and where the data and applications reside, resulting in different entities using their data collaboratively to train models without having to directly share that data or pool it in a centralized location.
Red Hat has a number of solutions that are designed to help service providers innovate at the edge. Red Hat OpenShift, built on Red Hat Enterprise Linux, propels cloud-native applications across any cloud environment to support 5G, RAN, edge and MEC deployment scenarios. Red Hat OpenShift AI offers a flexible, scalable MLOps platform with tools to build, deploy, and manage AI-enabled applications. It provides a fully supported environment in which to rapidly develop, train and test ML models across the hybrid cloud before deploying in production.
With the right solutions in place, service providers can gain and maintain a leadership position and outperform the competition, while reducing operational costs including the power consumption of their networks.
1 Achieving those objectives, of course, depends on a wide variety of factors, including, e.g., the geographic location and electric grid dependencies of the service provider.
Sobre los autores

Sanjay Aiyagari is a Principal Architect for Edge Computing at Red Hat working primarily with service providers and financial services businesses. With a long background in networking (Cisco) and virtualization (VMware), at Red Hat he is now helping enterprises use these capabilities to build out secure edge-based AI systems. Prior to Red Hat, he ran product management and strategy for Siaras, a startup and pioneer in the multicloud networking space. Before that he spent six years at VMware, where he advised the world’s largest telcos in virtualizing their critical real-time network functions. Beyond typical product delivery roles at Cisco, he also contributed as one of the earliest key members to the OASIS AMQP specification, which is widely used in cloud management, financial trading, transportation and military systems today. He has contributed to numerous industry groups, including OASIS, the ENI group of ETSI, and the IOWN global forum, and is currently running the Enterprise Neurosystem's Secure Connectivity working group, as well as contributing to inputs for the White House's National AI Research Resource and the UN Framework Convention on Climate Change Technology Executive Committee.
Mr. Aiyagari has a BS in Electrical Engineering from Cornell University and an MS in Computer Science from Columbia University.

Alexis de Talhouët is a Telco Solutions Architect at Red Hat, supporting North America telecommunication companies. He has extensive experience in the areas of software architecture and development, release engineering and deployment strategy, hybrid multi-cloud governance, and network automation and orchestration.

Jay Cromer is an Associate Principal Solution Architect at Red Hat working with the North American Telco, Media and Entertainment Industries. Jay has a background spanning more than 20 years in the Telecommunications industry with a focus on networking, cloud and automation.
Más como éste
Simplify Red Hat Enterprise Linux provisioning in image builder with new Red Hat Lightspeed security and management integrations
Simplifying modern defence operations with Red Hat Edge Manager
What Can Video Games Teach Us About Edge Computing? | Compiler
Can Kubernetes Help People Find Love? | Compiler
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube