Acceso compartido a la inteligencia artificial con operaciones unificadas de los modelos
- Para los ingenieros de inteligencia artificial, MaaS proporciona un acceso más rápido a los modelos de alto rendimiento a través de las API, lo que elimina la necesidad de descargar los modelos, gestionar las dependencias o solicitar asignaciones de GPU a través de solicitudes de seguimiento de incidentes de TI extensas.
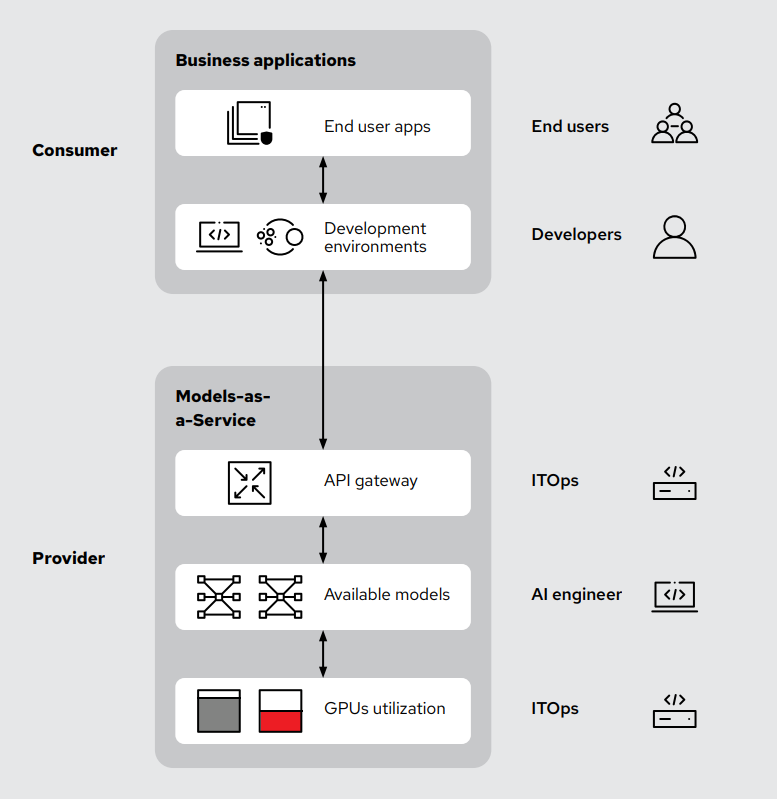
El MaaS funciona estableciendo un equipo de operaciones de inteligencia artificial como el propietario central de los recursos de inteligencia artificial compartidos. Los modelos se implementan en una plataforma flexible (como Red Hat® OpenShift® AI u otras similares) y, luego, se exponen a través de una puerta de enlace de API. Esta configuración permite que varios usuarios, desarrolladores y unidades comerciales ofrezcan acceso simplificado a los usuarios finales y, al mismo tiempo, cumplan con las prioridades de seguridad y control de los equipos de TI y finanzas. Esta priorización puede incluir funciones de devolución de cargos y la posibilidad de utilizar modelos sin necesidad de tener acceso directo al hardware ni conocimientos técnicos especializados. El objetivo es proporcionar un acceso sencillo a los modelos de inteligencia artificial y no a los recursos necesarios para ejecutarlos, como las GPU y las unidades de procesamiento tensorial (TPU). Todo esto sin dejar de cumplir con los requisitos de cumplimiento y rendimiento de la empresa, y sin comprometer el acceso de los usuarios finales.
En la práctica, los usuarios solo interactúan con las API que ofrecen respuestas generadas por los modelos. Así como los proveedores públicos de inteligencia artificial eliminan las complejidades del hardware de los usuarios finales, las implementaciones internas de MaaS ofrecen la misma sencillez. Los usuarios no gestionan la infraestructura de hardware o software directamente, no esperan a que se resuelva una solicitud de seguimiento de incidentes en su nombre ni se quedan al margen mientras se configura un entorno para ellos. En su lugar, los equipos de operaciones de TI e inteligencia artificial gestionan el ciclo de vida del modelo, la seguridad, las actualizaciones y el ajuste de la infraestructura desde un solo lugar, lo que ofrece a los usuarios un acceso optimizado pero controlado.
Esta unificación no solo optimiza las operaciones internas de inteligencia artificial, sino que también mejora el enfoque y el control de la seguridad. El acceso a los modelos de inteligencia artificial se controla estrictamente mediante la gestión de credenciales a través de una puerta de enlace de API. Las empresas pueden realizar un seguimiento del uso, configurar los mecanismos internos de devolución de cargos, asegurarse de que se sigan las pautas de cumplimiento normativo de privacidad y establecer límites operativos claros sin problemas, lo que hace que la inteligencia artificial empresarial sea manejable y práctica. El seguimiento del uso de los tokens (de entrada y de salida) es el método más preciso y detallado, y mucho más exacto que cualquier indicador de la GPU.
Control del uso, limitación del acceso y gestión de los costos
- Los ingenieros de TI y plataformas se benefician de la supervisión unificada, que evita las implementaciones no autorizadas de modelos, aplica estándares de seguridad y cumplimiento, y simplifica la gestión del ciclo de vida y de la infraestructura.
- Para los equipos de finanzas, el seguimiento concentrado del uso y los mecanismos internos de devolución de cargos reducen el desperdicio y hacen que el uso de la GPU sea más predecible y transparente. Esto ayuda a evitar gastos excesivos debido a la infrautilización de las asignaciones de hardware por equipo.
En un MaaS, el control se obtiene principalmente a través de la integración de una puerta de enlace de API a la infraestructura de inteligencia artificial, lo que permite que los equipos gestionen y supervisen el uso de la inteligencia artificial con gran detalle.
Las implementaciones tradicionales de inteligencia artificial suelen carecer de gestión o ser ineficientes, ya que las personas o los equipos implementan los modelos de forma independiente sin una supervisión unificada. Este enfoque fragmentado puede generar ineficiencias costosas, con recursos de GPU inactivos o infrautilizados. Al colocar una puerta de enlace de API en el centro de la infraestructura de inteligencia artificial, se crea un punto de acceso controlado entre los usuarios y los modelos.
Esta configuración facilita el seguimiento preciso del uso, hasta el nivel de token individual. Los equipos pueden identificar claramente cuánto consume cada usuario, equipo o aplicación, y atribuir los costos de la GPU y la infraestructura con precisión. Por ejemplo, las empresas pueden determinar si un usuario o una aplicación en particular está utilizando los recursos de manera excesiva y tomar medidas correctivas, como limitar el uso o asignar costos a través de mecanismos internos de devolución de cargos.
Las funciones de limitación que ofrece la puerta de enlace de API garantizan un rendimiento uniforme y evitan el agotamiento de los recursos. La limitación del uso permite que los equipos de TI gestionen la intensidad de los accesos, lo cual evita que un solo usuario monopolice los recursos de la GPU o afecte el rendimiento de los demás usuarios.
Además, las puertas de enlace de API ofrecen control de acceso y gestión de credenciales detallados. Los usuarios internos pueden generar credenciales para acceder a los modelos de inteligencia artificial de forma independiente, lo cual simplifica las tareas administrativas. Las credenciales también se pueden revocar o modificar en menos tiempo para responder a los cambios en los requisitos de seguridad o los patrones de uso.
Como resultado, se logra una mayor transparencia en la gestión de costos y una rendición de cuentas más clara. Los equipos de TI pueden asignar los gastos de GPU e infraestructura con precisión a los equipos o las unidades comerciales que los consumen.
Compatibilidad con todos los modelos, los aceleradores y las nubes
Uno de los principios fundamentales del enfoque de MaaS es el control. Permite que las empresas seleccionen e implementen una gran variedad de modelos de inteligencia artificial, elijan sus aceleradores de hardware preferidos y trabajen dentro de sus entornos locales o de nube actuales. Este enfoque brinda a las empresas la libertad de implementar la inteligencia artificial de acuerdo con sus necesidades técnicas, requisitos de seguridad y preferencias operativas.
- Las empresas enfrentan limitaciones estrictas a la hora de adoptar la inteligencia artificial. Estas suelen incluir:
- restricciones por servicios de nube específicos;
- dependencia de los ecosistemas de modelos propietarios;
- limitaciones por infraestructuras de hardware fijas.
- MaaS aborda estas limitaciones de varias maneras:
- Admite modelos open source o propietarios, modelos entrenados de forma personalizada y LLM conocidos, como Llama y Mistral.
- No se limita a los modelos basados en texto, sino que incluye el análisis predictivo, la visión artificial, las herramientas de transcripción de audio y otros casos prácticos de inteligencia artificial generativa multimodal, como la generación de imágenes o videos.
- MaaS sigue siendo independiente de los aceleradores de hardware, por lo que:
- Las empresas pueden seleccionar las GPU u otros aceleradores que se adapten a sus cargas de trabajo, estructuras de costos y necesidades de rendimiento.
- Los equipos unificados de inteligencia artificial pueden tomar decisiones importantes sobre el tamaño y la implementación, lo que mejora la eficiencia y reduce los errores de los usuarios con menos conocimientos técnicos.
- La gestión concentrada permite:
- optimizar la asignación y el uso de la infraestructura;
- reducir los gastos operativos y prevenir los errores de configuración de los recursos.
- MaaS admite la implementación en todos los entornos, entre los que se incluyen:
- las instalaciones, la nube híbrida, los entornos aislados y las nubes públicas, lo cual es especialmente valioso para los sectores altamente regulados que requieren soberanía de los datos, cumplimiento normativo o controles de seguridad estrictos.