-
Productos y documentación Red Hat AI
Una plataforma de productos y servicios para el desarrollo y la implementación de la inteligencia artificial en la nube híbrida.
Red Hat AI Enterprise
Diseña, desarrolla e implementa aplicaciones impulsadas por la inteligencia artificial en la nube híbrida.
Red Hat AI Inference
Optimiza el rendimiento de los modelos con una stack integrada para realizar inferencias rápidas, uniformes y rentables a gran escala.
Red Hat Enterprise Linux AI
Desarrolla, prueba y ejecuta modelos de inteligencia artificial generativa para impulsar las aplicaciones empresariales.
Red Hat OpenShift AI
Diseña e implementa aplicaciones y modelos con inteligencia artificial según sea necesario en entornos híbridos.
-
Recursos de aprendizaje Conceptos básicos
- Novedades de Red Hat AI
- Why you should care about AI inference
- ¿Qué son los vLLM?
- ¿Qué es la inferencia de la inteligencia artificial?
- ¿Qué es la inteligencia artificial con agentes?
- ¿Qué es AgentOps?
- ¿Qué es llm-d?
- Más información sobre la inteligencia artificial
- Todas las publicaciones de blog sobre inteligencia artificial
Motivos para elegir Red Hat AI
-
Partners de IA
La importancia de la inferencia de la inteligencia artificial
Por decirlo de una manera sencilla, no hay inteligencia artificial sin inferencia.
La inferencia es la parte central de la inteligencia artificial generativa. Sin embargo, cuando los modelos de gran tamaño tienen que ejecutar estrategias muy ambiciosas, la complejidad se dispara.
Por este motivo, analizamos los desafíos y las oportunidades que plantea la inferencia de la inteligencia artificial, desde la optimización con vLLM hasta los marcos distribuidos open source más avanzados, como llm-d.
¿Por qué la inferencia es clave?
La inferencia es la etapa final de un proceso extenso y sofisticado de machine learning (aprendizaje automático): el momento en que el modelo genera el resultado esperado.
Y, sobre todo, es una función imprescindible para que la inteligencia artificial realmente funcione y aporte valor.
Es por eso que el hardware y el software que te permiten realizar inferencias pueden facilitar o entorpecer tu estrategia de inteligencia artificial.

Desafíos que frenan tu capacidad de ajuste
El crecimiento constante de los modelos afecta el rendimiento de la inferencia. A medida que los modelos se vuelven más complejos, este proceso se torna más lento.
Para que la inferencia sea exitosa, los modelos de inteligencia artificial deben realizar muchas operaciones matemáticas en poco tiempo. Por lo tanto, factores como el tamaño del modelo, el gran volumen de usuarios y la latencia pueden limitar el rendimiento.
Cuando los modelos requieren más datos y más memoria, el hardware y los aceleradores tienen dificultades para satisfacer tal demanda.
66 %
es el porcentaje de recursos informáticos de IA que se prevé que se destinarán a la inferencia en 2026, en contraste con el 33 % de 2023 y el 50 % de 20251.
Formas de optimizar la inferencia
Al optimizar la inferencia, los modelos de inteligencia artificial ejecutan tareas más rápido y con mayor inteligencia.
Entre los métodos de optimización se incluyen un uso más eficiente de las GPU, la decodificación especulativa, la esparsidad, la compresión de modelos mediante técnicas de cuantización y la inferencia distribuida.
Herramientas como LLM Compressor aprovechan las últimas investigaciones en compresión de modelos para reducir el tamaño de los modelos de lenguaje de gran tamaño, aumentar su eficiencia energética y acelerar su funcionamiento. De este modo, disminuyen los requisitos de hardware y mejoran la eficiencia, sin comprometer la precisión.
Optimizaciones de este tipo aseguran que la inferencia de inteligencia artificial siga siendo rentable, lo que facilita su ajuste conforme aumentan las demandas de tu equipo.
Más del 99 %
de precisión conservada durante las optimizaciones con LLM Compressor2.

2
veces más rendimiento informático con modelos comprimidos, sin comprometer la precisión3.
50 %
de ahorro en costos al optimizar modelos con LLM Compressor sin afectar el rendimiento4.

Optimización de la inferencia con vLLM
La optimización de modelos representa solo una parte del desafío. También se requiere un motor de inferencia de alto rendimiento, y, en este aspecto, vLLM resulta clave.
Los sistemas convencionales de gestión de memoria en los modelos de lenguaje de gran tamaño no organizan los datos de la mejor manera, lo que reduce su velocidad. vLLM implementa PagedAttention, una técnica que detecta valores clave repetidos para reducir el trabajo innecesario del modelo.
Esto permite al vLLM aprovechar mejor la memoria de la GPU y acelerar la inferencia de la inteligencia artificial generativa. Aumenta el rendimiento (tokens procesados por segundo) para prestar servicio a muchos usuarios a la vez.
El uso eficiente de los aceleradores permite que los modelos realicen operaciones más complejas en menos tiempo, para que los equipos puedan responder más rápido a un mayor número de usuarios y agentes.
50 %
de reducción de los parámetros con el uso de estructura de esparsidad5.

2,1
veces menor latencia de inferencia gracias a técnicas de decodificación especulativa6.
24
veces más rendimiento con vLLM respecto a la competencia7.
Motivos que explican el éxito de vLLM
vLLM aborda los desafíos centrales de la eficiencia en el uso de la GPU, reduce el costo por token y logra una latencia estable a gran escala, todo ello con un enfoque de implementación abierto y portátil.
Por eso, cuenta con una comunidad activa y dinámica. Las contribuciones de equipos comprometidos como Hugging Face, UC Berkeley, NVIDIA y Red Hat impulsan mejoras permanentes, y aseguran que el software evolucione constantemente dentro del proyecto open source.
Con compatibilidad desde el día cero con todos los modelos y aceleradores más utilizados, su accesibilidad facilita la adopción en empresas y ámbitos académicos.
Más de 10 000
commits de vLLM en GitHub*, lo que supone un aumento de más del 200 % en 2025.
La comunidad vLLM hoy
Más de 500 000
GPU implementadas de manera ininterrumpida8
Más de 200
tipos diferentes de aceleradores9
Más de 500
arquitecturas de modelos compatibles9
Más de 2200
El papel de la inferencia distribuida
Con la inferencia distribuida, los modelos de inteligencia artificial dividen la carga de trabajo entre un grupo de dispositivos interconectados.
Cuando un modelo puede satisfacer diferentes solicitudes de manera simultánea, disminuyen los requisitos de hardware y la eficiencia de la inferencia mejora.
La inferencia distribuida utiliza técnicas como el paralelismo tensorial, la programación inteligente de la inferencia y la desagregación. En combinación con vLLM, permite que la inferencia funcione como una máquina multitarea altamente eficiente.
Así, se mantiene ajustable, uniforme y fácil de supervisar.
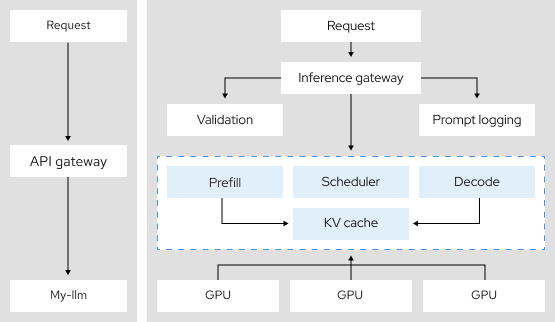
3,9 veces
más rendimiento de tokens con el paralelismo tensorial, una arquitectura de inferencia distribuida10.
¿Hay una comunidad open source para esto?
Sí, se denomina llm-d.
Es un marco open source que ofrece a los desarrolladores un plan para diseñar una inferencia distribuida a gran escala.
Gracias a su arquitectura modular, se adapta a las complejas exigencias de recursos de los modelos de lenguaje de gran tamaño complejos y sustituye los procesos manuales y fragmentados por procesos integrados y optimizados, lo que acelera la transición de la fase inicial a la de producción.
Con llm-d, la inferencia llega a Kubernetes. Su kit de herramientas estandarizado permite implementar inferencia distribuida adaptada a los casos prácticos específicos de tu empresa.
2
es el valor de referencia de consultas por segundo (QPS) que se obtiene con llm-d11.
Recursos adicionales de inteligencia artificial
Red Hat AI Inference
Acelera la transición de tus modelos de lenguaje de gran tamaño de la fase de desarrollo a la producción.
Nuestro motor de inferencia para empresas se basa en vLLM y ofrece mayor velocidad sin afectar al rendimiento.
Ajusta la capacidad en la nube híbrida con el modelo de inteligencia artificial generativa optimizado que elijas, con cualquier acelerador y en cualquier entorno de nube.

Referencias
[1] "Why AI’s Next Phase Will Likely Demand More Computing Power—Not Less ". The Wall Street Journal, 22 de enero de 2026.
[2] Kurtić, Eldar, et al. "We ran over half a million evaluations on quantized LLMs—here's what we found". Blog de Red Hat Developer, 17 de octubre de 2024.
[3] Condado, Carlos. "Un enfoque estratégico para el rendimiento de la inferencia de la inteligencia artificial". Blog de Red Hat, 15 de septiembre de 2025.
[4] Zelenović, Saša. "Aprovecha todo el potencial de los LLM: optimiza el rendimiento con los vLLM". Blog de Red Hat, 27 de febrero de 2025.
[5] Kurtić, Eldar, et al. "2:4 Sparse Llama: Smaller models for efficient GPU inference". Blog de Red Hat Developer, 28 de febrero de 2025.
[6] Marques, Alexandre, et al. "Fly Eagle(3) fly: Faster inference with vLLM & speculative decoding". Blog de Red Hat Developer, 1.º de julio de 2025.
[7] Kwon, Woosuk, et al. "vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention". Blog de vLLM, 20 de junio de 2023.
[8] Goin, Michael. "[vLLM Office Hours #38] vLLM 2025 Retrospective & 2026 Roadmap - December 18, 2025". YouTube, 8 de diciembre de 2025.
[9] Kwon, Woosuk. "Today, vLLM supports 500+ model architectures, runs on 200+ accelerator types, and powers inference at global scale". X, 26 de enero de 2026.
[10] Goin, Michael. "Distributed inference with vLLM". Red Hat Developer, 6 de febrero de 2025.
[11] Shaw, Robert. "llm-d: Kubernetes-native distributed inferencing". Red Hat Developers, 20 de mayo de 2025.