
La sécurité est un composant clé des architectures basées sur des conteneurs.
Si elle présente de nombreux aspects (comme le montre la longue liste des rubriques de la documentation officielle d'OpenShift disponible ici), parmi ses exigences de base figurent l'authentification et l'autorisation. Dans cet article, vous découvrirez comment l'authentification et l'autorisation fonctionnent dans Kubernetes et Red Hat OpenShift. Nous aborderons les interactions entre les différentes couches de l'écosystème Kubernetes : la couche d'infrastructure, la couche Kubernetes et la couche des applications conteneurisées.
Définition de l'authentification et de l'autorisation
En termes simples, l'authentification d'un système informatique est un moyen de répondre à la question « Qui êtes-vous ? », tandis que l'autorisation permet de répondre à la question « Maintenant que je sais qui vous êtes, qu'êtes-vous autorisé à faire ? ».
D'après mon expérience, dans Kubernetes, il est difficile de comprendre ces mécanismes en raison du nombre élevé de composants (utilisateurs, API, conteneurs, pods) qui interagissent entre eux. Lorsqu'il est question d'authentification, il faut d'abord déterminer quels sont les composants impliqués. Vous authentifiez-vous auprès du cluster Kubernetes ? Ou est-ce un microservice qui tente d'accéder à un autre microservice de l'environnement ? S'agit-il plutôt d'une ressource cloud située en dehors du cluster Kubernetes ? Ou est-ce un point de terminaison (une ressource cloud, un système ou une personne) qui tente d'accéder à l'une des applications exécutées dans le cluster et de l'utiliser ?
Authentification et autorisation avec OAuth 2.0 et OIDC
Imaginons qu'un utilisateur tente d'accéder à un point de terminaison. L'utilisateur peut être :
- une personne ;
- un compte machine (un pod d'application, un composant système, un pipeline logiciel ou une entité physique ou logique).
Le point de terminaison peut être :
- une API ;
- un logiciel (par exemple, une base de données) ;
- un serveur physique ou virtuel.
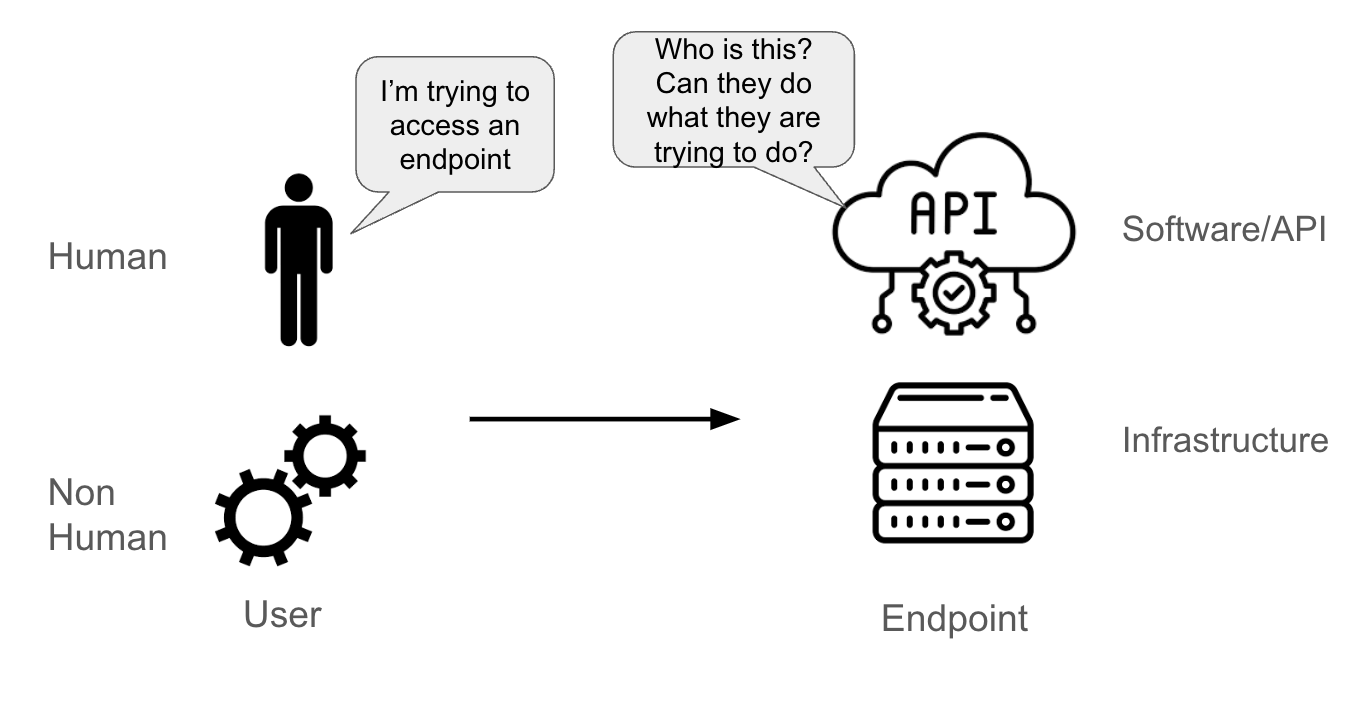
Lorsque le point de terminaison reçoit une demande de l'utilisateur, il doit pouvoir identifier :
- l'émetteur de cette requête (c'est l'étape d'authentification) ;
- les actions que cet utilisateur est autorisé à faire (c'est l'étape d'autorisation).
La documentation officielle de Kubernetes contient toute une partie sur l'authentification qui explique notamment que dans Kubernetes, l'authentification correspond au processus d'authentification des requêtes d'API adressées au serveur d'API Kubernetes. Ces requêtes peuvent être effectuées à l'aide des commandes kubectl ou oc dans un terminal, une interface utilisateur graphique ou via un appel d'API. Dans tous les cas, elles seront envoyées au serveur d'API.
Même s'il existe de nombreux protocoles et technologies d'authentification (LDAP, SAML, Kerberos, etc.), la méthode d'authentification d'API la plus efficace et couramment utilisée est l'association des protocoles OAuth 2.0 et OIDC (OpenID Connect).
OAuth 2.0 est un protocole d'autorisation (et non un protocole d'authentification) conçu pour accorder l'accès à un ensemble de ressources (par exemple, une API distante ou des données utilisateur). Pour ce faire, il utilise un jeton d'accès, c'est-à-dire une donnée qui représente l'autorisation d'accès à une ressource au nom de l'utilisateur final.
OIDC est un protocole d'authentification qui complète le framework OAuth 2.0 en y ajoutant une couche d'identification. Il fournit un mécanisme pour demander des informations spécifiques de l'utilisateur, telles que son nom ou son adresse e-mail, et permet aux utilisateurs d'accorder ou de refuser l'accès à ces informations. Ce protocole complète OAuth2 avec un champ supplémentaire renvoyé avec le jeton d'accès appelé jeton d'identification. Il s'agit d'un jeton web JSON (JWT) avec des champs spécifiques, tels que l'e-mail de l'utilisateur, signé par le serveur.
Le schéma ci-dessous montre les étapes suivies lorsqu'un utilisateur tente de configurer un ensemble d'actions dans un cluster Kubernetes à l'aide de la commande kubectl. Le processus complet est plus complexe, mais il est bien expliqué dans la documentation officielle.
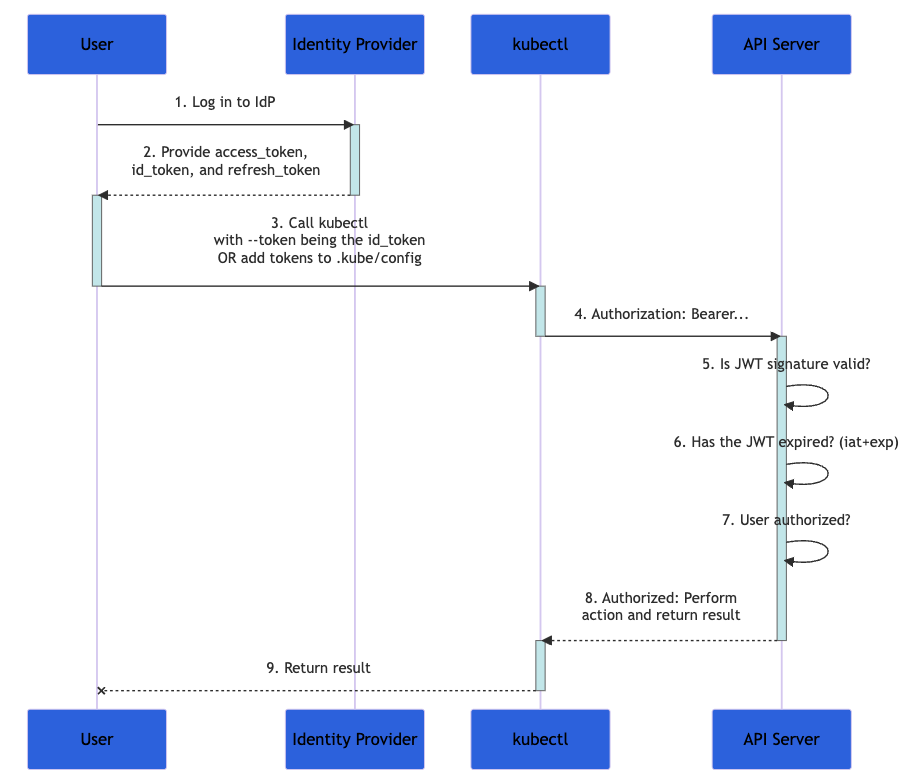
Image : schéma présentant le processus d'authentification (extrait de la documentation de Kubernetes)
- D'abord, l'utilisateur se connecte à un fournisseur d'identité.
- Le fournisseur d'identité lui fournit les jetons
access_token, id_tokenetrefresh_token. - Avec la commande
kubectl, il utilise le jetonid_tokenavec le paramètre--token, ou ajoute le jeton àkubeconfig. - La commande
kubectlenvoie le jetonid_tokendans un en-tête appelé « Authorization » au serveur d'API. - Le serveur d'API vérifie que la signature JWT est valide, que le jeton
id_tokenn'a pas expiré et que l'utilisateur est autorisé à effectuer l'action. - Le serveur d'API renvoie une réponse à la commande
kubectl, qui fournit alors des informations à l'utilisateur.
Étant donné que le jeton id_token contient toutes les données nécessaires à la validation de l'identité de l'utilisateur, Kubernetes n'a pas besoin d'interagir davantage avec le fournisseur d'identité. Il s'agit d'une solution d'authentification hautement évolutive, en particulier lorsque les requêtes sont de type stateless.
Définition du contrôle d'accès basé sur les rôles
Le contrôle d'accès basé sur les rôles, ou RBAC (Role Based Access Control), est une méthode qui permet de réguler l'accès à des ressources informatiques ou réseau en fonction du rôle de chaque utilisateur d'une entreprise. Par exemple, un administrateur système sur une plateforme pourrait avoir le droit d'apporter des modifications à l'ensemble de l'environnement (avec des effets potentiels sur chaque application du cluster). Par contre, un utilisateur qui est responsable de la gestion d'une seule application dans le cluster n'est probablement autorisé à modifier uniquement cette application.
L'image ci-dessous montre ces deux exemples d'utilisateurs. L'icône verte représente un utilisateur appartenant à l'équipe des RH, tandis que l'icône noire représente un administrateur de la plateforme. L'utilisateur des RH ne peut accéder qu'aux ressources du groupe d'applications RH, tandis que l'administrateur de la plateforme peut accéder à tous les éléments sur la plateforme.
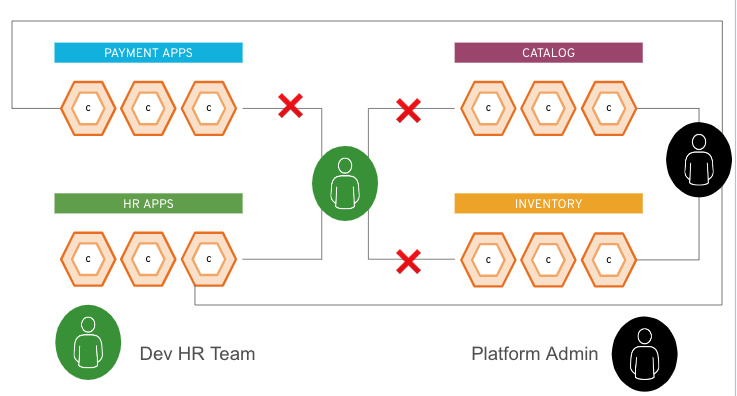
L'utilisateur des RH reçoit un jeton vert à l'étape d'autorisation, tandis que l'administrateur reçoit un jeton noir. Dans le cadre de son interaction avec le point de terminaison (le cluster Kubernetes ou l'API OpenShift), chaque utilisateur ajoute son jeton (vert ou noir) à ses requêtes. Sur la base de ce jeton, le cluster sait à quelles applications chaque utilisateur peut accéder.
Chiffrement TLS et points de terminaison
Le protocole TLS (Transport Layer Security) est le mécanisme de transport le plus couramment utilisé pour atteindre un point de terminaison Kubernetes. Il fournit un tunnel chiffré pour le protocole HTTPS.
Si vous êtes l'administrateur système d'une machine virtuelle Linux ou Windows, vous devez probablement utiliser les protocoles SSH ou RDP pour accéder à ces points de terminaison. Ces protocoles chiffrent le trafic entre vous (l'utilisateur) et le point de terminaison (le serveur Linux ou Windows). Pour les API, logiciels ou services SaaS (Software-as-a-Service) tiers, c'est le protocole de transport TLS qui est couramment utilisé.
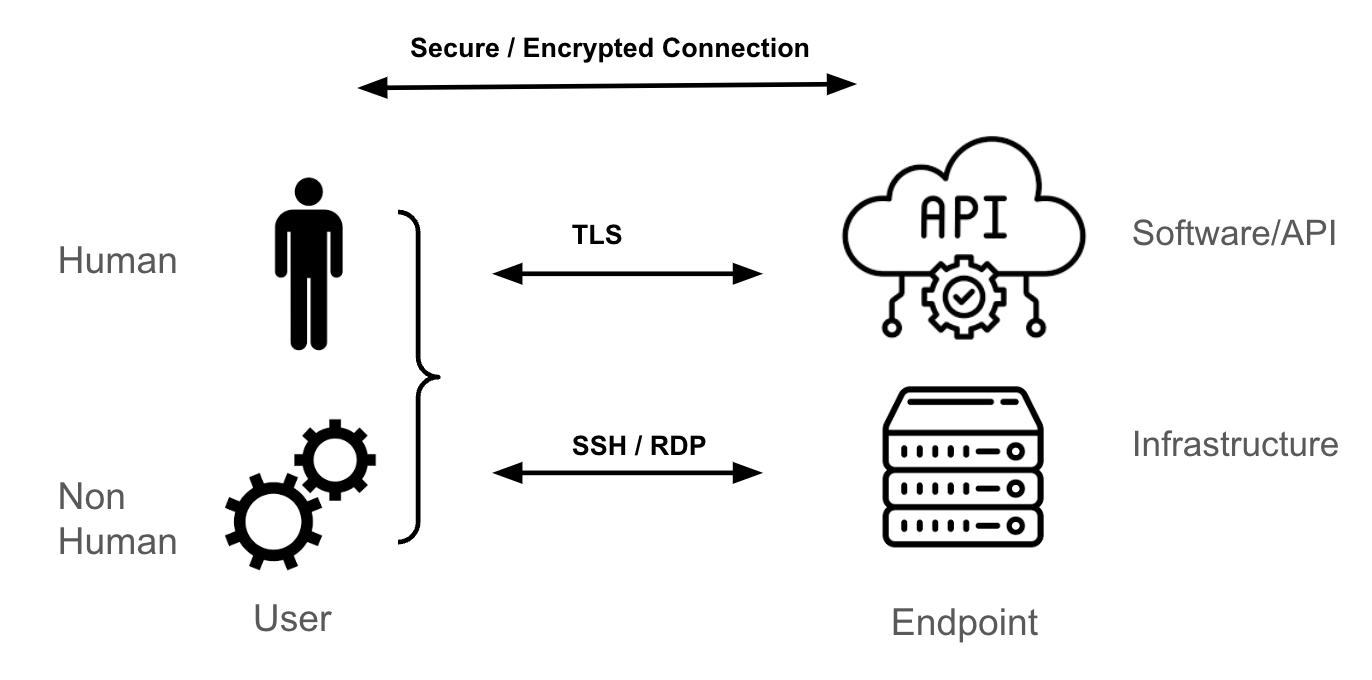
Nous ne verrons pas ici comment s'établit une session sécurisée et chiffrée entre le point de terminaison et l'utilisateur. Nous pouvons toutefois indiquer que ce processus repose sur des tunnels et des clés (ou des certificats) utilisés pour authentifier les points de terminaison (soit l'utilisateur, soit le point de terminaison, soit les deux) et pour chiffrer et déchiffrer les paquets envoyés entre les points de terminaison.
Couches d'accès à Kubernetes et OpenShift
Une fois qu'on les connaît, les concepts d'authentification, d'autorisation et de transport sont relativement simples à comprendre. Les environnements informatiques comportent toutefois plusieurs couches, et c'est là que la complexité et la confusion peuvent apparaître.
Une architecture Kubernetes comprend trois couches principales :
- la couche d'infrastructure, qui est réservée au calcul, au stockage et à la mise en réseau. Il peut s'agir d'un cloud public, d'un datacenter sur site ou en colocation, ou encore d'un mélange de tous ces éléments ;
- la couche Kubernetes, réservée à l'hébergement et à la gestion de toutes les applications conteneurisées ;
- la couche des applications conteneurisées, qui correspond à des groupes de conteneurs formant des applications spécifiques. Il peut s'agir d'applications standards, fournies par des éditeurs de logiciels indépendants, développées en interne, ou de plusieurs de ces types.
Chaque couche fournit et requiert des fonctionnalités d'authentification et d'autorisation.
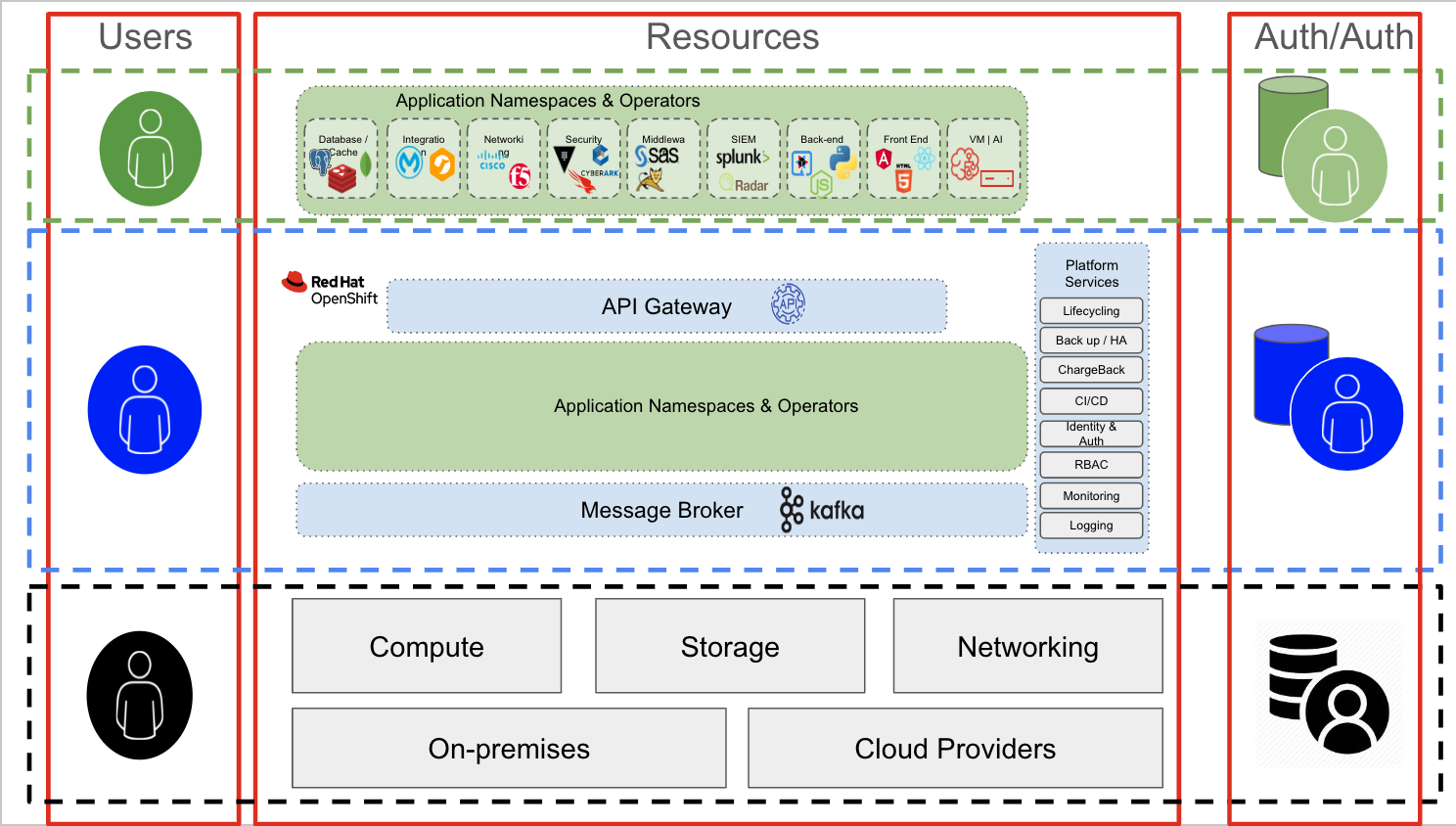
Authentification et autorisation au niveau de la couche d'infrastructure
Les utilisateurs de la couche d'infrastructure sont généralement des administrateurs système qui doivent accéder à des composants spécifiques (stockage, mise en réseau, calcul ou virtualisation).Pour accéder à cette couche (la couche inférieure représentée en noir dans l'image ci-dessus), un utilisateur de type administrateur se connecte généralement à un serveur via une connexion SSH, en utilisant des interfaces dédiées pour les nœuds de stockage, de mise en réseau ou de calcul (technologies iLO et iDRAC par exemple). Le mécanisme d'authentification peut combiner les protocoles RADIUS ou TACACS (mise en réseau), LDAP ou Kerberos (serveurs et stockage), ou d'autres mécanismes spécifiques d'un domaine.
Il est intéressant de noter que le même utilisateur administrateur de l'infrastructure peut utiliser une application (couche verte), hébergée sur OpenShift (couche bleue) pour effectuer ses tâches.
Par exemple, la pile de gestion de la mise en réseau peut être une application conteneurisée exécutée sur OpenShift. Toutefois, dans ce contexte, l'utilisateur administrateur est essentiellement un utilisateur normal (vert) qui tente d'accéder à une application (ici, la pile de gestion de la mise en réseau). Dans cette couche, les mécanismes d'authentification et d'autorisation sont différents. Par exemple, une connexion à l'application s'effectue probablement via une connexion TLS/SSL et peut nécessiter des informations d'identification pour accéder à la console de la pile de gestion du réseau.
Authentification et autorisation dans OpenShift
Pour atteindre la couche bleue (c'est-à-dire interagir avec OpenShift ou Kubernetes en général), il est nécessaire de communiquer avec le serveur d'API Kubernetes. C'est aussi bien vrai pour un utilisateur humain que pour un utilisateur machine, qu'il utilise une console d'interface utilisateur graphique ou un terminal. En fin de compte, toutes les interactions avec OpenShift ou Kubernetes passent par le serveur d'API.
L'association OAuth2/OIDC est parfaitement logique pour l'authentification et l'autorisation des API, c'est pourquoi OpenShift intègre un serveur OAuth2. Dans le cadre de la configuration de ce serveur OAuth2, il faut ajouter un fournisseur d'identité pris en charge. Celui-ci aide le serveur OAuth2 à confirmer l'identité de l'utilisateur. Une fois que cette partie a été configurée, OpenShift est prêt à authentifier les utilisateurs.
Pour un utilisateur authentifié, OpenShift crée un jeton d'accès et le renvoie à l'utilisateur. Ce jeton est appelé jeton d'accès OAuth.Un utilisateur peut utiliser un jeton d'accès OAuth à chaque interaction avec l'API OpenShift jusqu'à ce qu'il expire ou soit révoqué.
Utilisateurs et comptes de service
Un utilisateur peut être humain ou machine. Dans OpenShift, un utilisateur donné peut avoir des rôles différents sur le plan conceptuel :
- Utilisateurs standards : individus interagissant avec un cluster Kubernetes
- Utilisateurs système : individus (par exemple, un administrateur de plateforme) et composants de cluster machine (par exemple, le registre, les divers nœuds de plan de contrôle et les nœuds d'application)
- Autres utilisateurs machine : comptes de service représentant généralement des applications (à l'intérieur ou à l'extérieur du cluster) qui doivent interagir avec l'API Kubernetes (par exemple, un pipeline basé sur GitLab, GitHub ou Tekton utilisera un compte de service pour interagir avec OpenShift)
Les utilisateurs et les comptes de service peuvent être organisés en groupes dans OpenShift. Les groupes facilitent la gestion des politiques d'autorisation, car ils permettent d'octroyer des autorisations à plusieurs utilisateurs à la fois. Par exemple, vous pouvez autoriser tout un groupe à accéder aux objets d'un projet au lieu d'accorder l'accès à chacun des utilisateurs.
Un utilisateur peut être ajouté à un ou plusieurs groupes, chacun d'eux représentant un ensemble d'utilisateurs donné. La plupart des entreprises disposent déjà de groupes d'utilisateurs (par exemple, sur un serveur Active Directory). Il est possible de synchroniser les enregistrements LDAP avec les enregistrements des groupes OpenShift internes.
Contrôle d'accès basé sur les rôles et autorisation
Lorsqu'un utilisateur s'est authentifié et a reçu un jeton d'accès OAuth2, il obtient un ensemble de privilèges d'accès basés sur le RBAC. Un objet RBAC détermine si un utilisateur est autorisé à effectuer une action donnée sur une ressource. La définition du RBAC peut s'appliquer à l'échelle du cluster ou du projet.
Le RBAC est géré à l'aide des éléments suivants :
- Règles : ensembles des actions (verbes) qui peuvent être effectuées sur un ensemble d'objets. Regroupées sous l'acronyme CRUD : create, read, update, delete (créer, lire, mettre à jour, supprimer), elles représentent les opérations essentielles du stockage persistant. Dans le contexte d'une API RESTful, il s'agit des opérations POST, GET, PUT ou PATCH et DELETE du protocole HTTP.Par exemple, un utilisateur ou un compte de service peut être autorisé à créer un pod.
- Rôles : collections de règles. Il est possible d'associer ou de lier des utilisateurs et des groupes à plusieurs rôles.
- Liaisons : associations entre les utilisateurs et les groupes ayant un rôle
OpenShift inclut des rôles prédéfinis (cluster-admin et basic-user, entre autres). L'image ci-dessous (extraite de la documentation d'OpenShift) donne un aperçu du contrôle d'accès basé sur les rôles, avec des règles, des rôles et des liaisons.
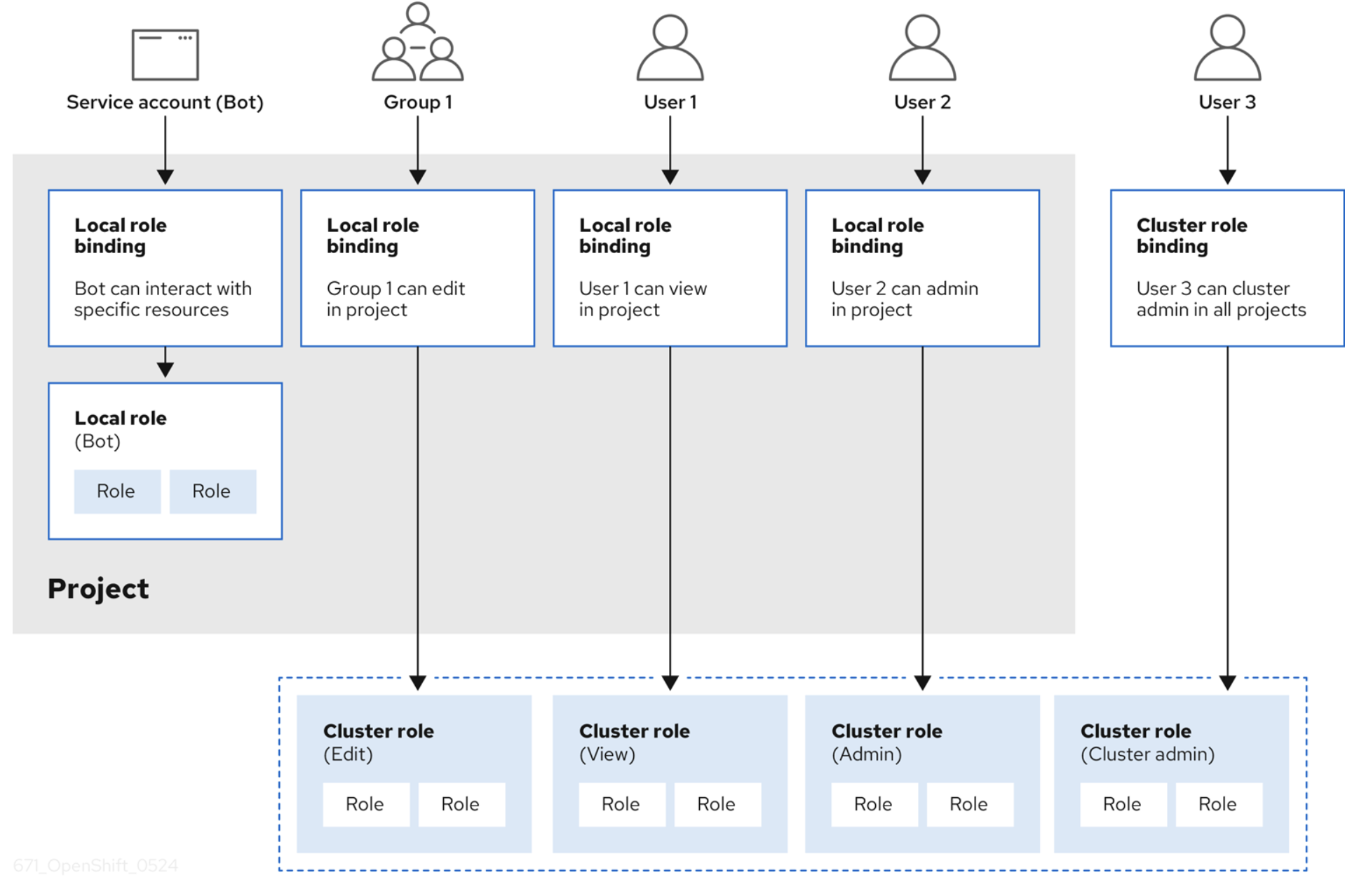
Authentification et autorisation à partir de ressources au niveau de la couche OpenShift
Une ressource de la couche Kubernetes (généralement un pod) peut nécessiter une autorisation d'accès pour les situations suivantes :
- Interaction avec l'API Kubernetes
- Interaction avec l'hôte (la couche d'infrastructure) sur lequel la ressource est hébergée
- Interaction avec des ressources situées à l'extérieur du cluster (par exemple, une ressource cloud)

Interaction avec l'API Kubernetes
Toute interaction avec l'API Kubernetes nécessite une méthode d'authentification basée sur OAuth. Un pod représente un utilisateur machine, et nécessite donc un compte de service pour interagir avec le serveur d'API.
Par défaut, un pod est associé à un compte de service. Ses informations d'identification (jetons) se situent dans le système de fichiers de chaque conteneur de ce pod, à l'emplacement /var/run/secrets/kubernetes.io/serviceaccount/token.L'utilité de ce modèle fait débat. Dans OpenShift, cette méthode est donc configurable et peut être appliquée à l'aide de politiques telles que celles de la solution Advanced Cluster Security.
Interaction avec la couche d'infrastructure hôte/Kubernetes
Ce type d'interaction ne repose pas sur les appels d'API Kubernetes. En réalité, elle est liée à la gestion des autorisations au niveau du processus (autorisations au niveau de Linux) de l'hôte sous-jacent.
La mise en correspondance des actions (autorisations) qu'un pod peut effectuer avec l'infrastructure sous-jacente et des ressources auxquelles il peut accéder s'effectue à l'aide de contraintes de contexte de sécurité (SCC). Une SCC est une ressource OpenShift qui limite un pod à un groupe de ressources et qui est similaire à la ressource du contexte de sécurité de Kubernetes.
Par exemple, un processus peut être autorisé ou non à créer un fichier à un emplacement donné, ou il peut avoir uniquement un accès en lecture à un fichier existant. Dans les deux cas, l'objectif est de limiter l'accès d'un pod à l'environnement hôte. Vous pouvez utiliser une SCC pour contrôler les autorisations du pod, de la même manière que le contrôle d'accès basé sur les rôles est utilisé pour gérer les privilèges de l'utilisateur.
Interaction avec des ressources externes
Un pod a parfois besoin d'accéder à une ressource située à l'extérieur du cluster, par exemple un système de stockage d'objets (comme un compartiment S3) pour consulter des données ou des fichiers journaux. Dans ce cas, il faut bien comprendre comment la ressource authentifie les utilisateurs et ce qu'il faut intégrer au pod qui va communiquer avec cette ressource.
Le système de gestion des identités et des accès (IAM) d'Amazon pour les rôles de comptes de service permet par exemple de fournir aux pods un ensemble d'informations d'identification pour accéder aux services sur AWS. Lorsqu'un pod est créé, un webhook injecte des variables (le chemin d'accès au jeton du compte de service Kubernetes et l'identifiant Amazon Resource Name du rôle présumé) dans le pod faisant référence au compte de service. On parle également de « mutation ». Si le rôle IAM présumé dispose des autorisations AWS requises, le pod peut exécuter les opérations du SDK d'AWS à l'aide d'informations d'identification STS temporaires.
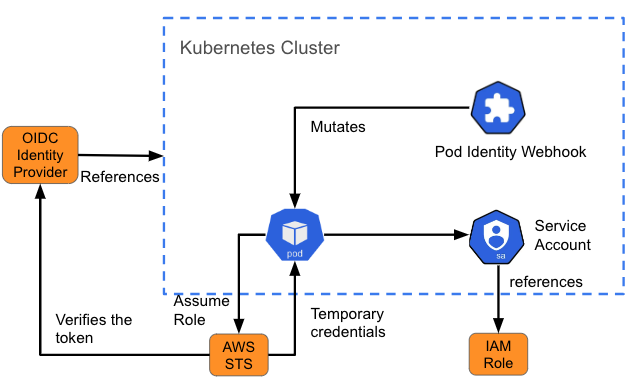
Authentification et autorisation pour les applications conteneurisées dans OpenShift
Les applications conteneurisées constituent la dernière couche. Comme pour la couche précédente, chaque conteneur peut tenter d'accéder aux éléments suivants :
- L'API Kubernetes
- Une API fournie soit par un autre conteneur au sein du cluster, soit par une ressource à l'extérieur du cluster
- Une connexion hors API (contact d'un port spécifique pour accéder à une base de données par exemple)
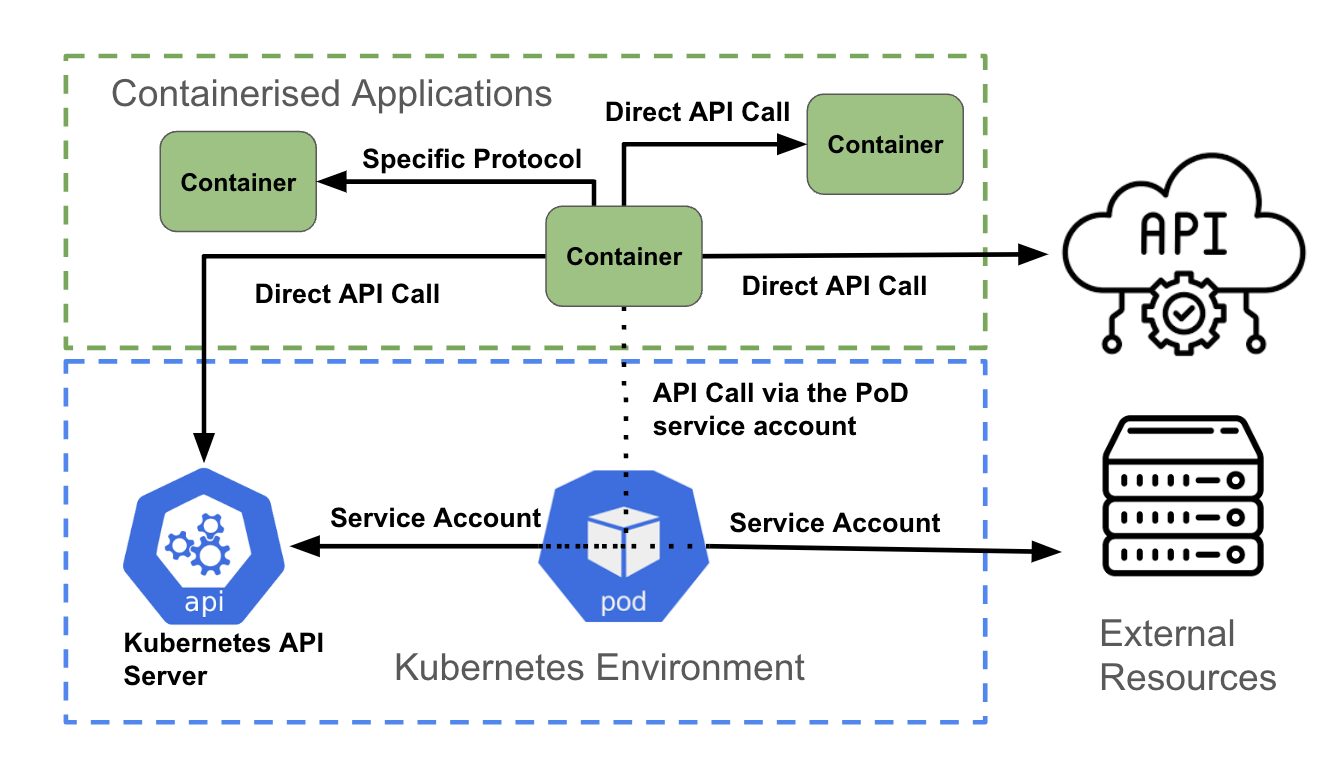
Comme le montre l'image ci-dessus, un conteneur qui accède à une API peut effectuer les actions suivantes :
- Accéder directement à une autre API à l'aide des informations d'authentification associées à l'application (avec les secrets Kubernetes, par exemple)
- Accéder directement à un point de terminaison hors API à l'aide de mécanismes d'authentification pris en charge par le point de terminaison
- Utiliser le compte de service du pod
Appel d'API direct
Un conteneur peut accéder à l'API Kubernetes en récupérant les variables d'environnement KUBERNETES_SERVICE_HOST et KUBERNETES_SERVICE_PORT_HTTPS. Pour le trafic d'API autres que Kubernetes, une application peut utiliser soit une bibliothèque cliente (par exemple, une API AWS), soit une intégration personnalisée créée par le développeur.
Communication non basée sur une API
Une application peut avoir besoin de se connecter à une base de données pour récupérer ou transférer des données. Dans ce cas, l'authentification est généralement gérée directement dans le code au sein du conteneur, et peut être mise à jour au moment de l'exécution, à l'aide de variables d'environnement, de secrets, d'objets ConfigMap, etc.
Utilisation du compte de service
Il est recommandé de s'authentifier auprès du serveur d'API Kubernetes en utilisant les informations d'identification d'un compte de service. La plupart des langages de programmation ont un ensemble de bibliothèques clientes Kubernetes prises en charge. Sur la base de ces bibliothèques, les informations d'identification du compte de service d'un pod sont utilisées pour communiquer avec le serveur d'API. OpenShift crée automatiquement un compte de service dans chaque pod, ce qui lui permet d'accéder au jeton défini.
Pour les appels d'API autres que Kubernetes, un conteneur peut également utiliser le compte de service du pod lors de l'authentification auprès d'un service d'API externe.
Authentification et autorisation
Tout ordinateur doit pouvoir identifier un utilisateur et les actions qu'il est autorisé à faire. Il s'agit de l'authentification et de l'autorisation, et vous devriez désormais comprendre comment ces deux aspects sont gérés dans Kubernetes et OpenShift.
Merci à Shane Boulden et Derek Waters pour la relecture approfondie de cet article en anglais et leurs commentaires.
À propos de l'auteur
Simon Delord is a Solution Architect at Red Hat. He works with enterprises on their container/Kubernetes practices and driving business value from open source technology. The majority of his time is spent on introducing OpenShift Container Platform (OCP) to teams and helping break down silos to create cultures of collaboration.Prior to Red Hat, Simon worked with many Telco carriers and vendors in Europe and APAC specializing in networking, data-centres and hybrid cloud architectures.Simon is also a regular speaker at public conferences and has co-authored multiple RFCs in the IETF and other standard bodies.
Plus de résultats similaires
Les menaces liées à l'IA évoluent. Vos défenses doivent en faire autant.
Au-delà de l'automatisation : pourquoi la montée des vulnérabilités de sécurité liées à l'IA exige une expertise technique humaine
Container Roundup | Compiler
Collaboration In Product Security | Compiler
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud