Aujourd'hui, il est essentiel de pouvoir fournir en continu des services aux clients en limitant le nombre de pannes, voire en les éliminant complètement. Le module complémentaire Red Hat Enterprise Linux (RHEL) High Availability Add-On peut vous aider à atteindre cet objectif en améliorant la fiabilité, l'évolutivité et la disponibilité des systèmes de production. Pour ce faire, les clusters haute disponibilité éliminent les points de défaillance uniques et basculent les services d'un nœud de cluster vers un autre lorsqu'un nœud cesse de fonctionner.
Dans cet article, nous allons voir comment utiliser le rôle système RHEL ha_cluster pour configurer un cluster haute disponibilité qui exécute un serveur HTTP Apache avec stockage partagé en mode actif/passif.
Les rôles système RHEL sont un ensemble de rôles et de modules Ansible inclus dans RHEL pour fournir des workflows cohérents et rationaliser l'exécution des tâches manuelles. Pour en savoir plus sur la mise en cluster haute disponibilité avec RHEL, consultez la documentation sur la configuration et la gestion de clusters haute disponibilité.
Présentation de l'environnement
L'environnement de référence utilisé ici se compose d'un système de nœuds de contrôle nommé controlnode et de deux nœuds gérés, rhel8-node1 et rhel8-node2. Tous exécutent RHEL 8.6. Les deux nœuds gérés sont alimentés par un commutateur APC dont le nom d'hôte est apc-switch.
Je souhaite créer un cluster nommé rhel8-cluster, composé des nœuds rhel8-node1 et rhel8-node2. Ce cluster exécutera un serveur HTTP Apache en mode actif/passif avec une adresse IP flottante qui servira des pages d'un système de fichiers ext4 monté sur un volume logique LVM (Logical Volume Manager). Le fencing est assuré par apc-switch.
Les deux nœuds de cluster sont connectés à un périphérique de stockage partagé avec un système de fichiers ext4 monté sur un volume logique LVM. Un serveur HTTP Apache a été installé et configuré sur les deux nœuds. Reportez-vous aux chapitres sur la configuration d'un volume LVM avec un système de fichiers ext4 dans un cluster Pacemaker et sur la configuration d'un serveur HTTP Apache de la documentation relative à la configuration et la gestion de clusters haute disponibilité.
J'ai déjà configuré un compte de service Ansible sur les trois serveurs, nommé ansible. J'ai également configuré l'authentification par clé SSH afin que le compte ansible sur controlnode puisse se connecter à chacun des nœuds. En outre, le compte de service ansible a été configuré de manière à pouvoir accéder au compte root via la commande sudo sur chaque nœud. J'ai aussi installé les paquets rhel-system-roles et ansible sur controlnode. Pour en savoir plus sur ces tâches, consultez l'article de blog sur les rôles système RHEL.
Définition du fichier d'inventaire et des variables de rôle
Depuis le système controlnode, il faut commencer par créer une structure de répertoire :
[ansible@controlnode ~]$ mkdir -p ha_cluster/group_vars
Ces répertoires seront utilisés comme suit :
- Le répertoire ha_cluster contiendra le playbook et le fichier d'inventaire.
- Le fichier ha_cluster/group_vars contiendra des fichiers de variables pour les groupes d'inventaire qui s'appliqueront aux hôtes dans les groupes d'inventaires Ansible respectifs.
Je dois définir un fichier d'inventaire Ansible pour lister et regrouper les hôtes que je souhaite configurer avec le rôle système ha_cluster. Je crée donc le fichier d'inventaire sous ha_cluster/inventory.yml en saisissant le contenu suivant :
---
all:
children:
rhel8_cluster:
hosts:
rhel8-node1:
rhel8-node2:L'inventaire définit un groupe d'inventaires nommé rhel8_cluster et attribue les deux nœuds gérés à ce groupe.
Ensuite, je définis les variables de rôle qui contrôleront le comportement du rôle système ha_cluster lors de son exécution. Le fichier README.md pour le rôle ha_cluster, accessible sous /usr/share/doc/rhel-system-roles/ha_cluster/README.md, contient des informations importantes sur le rôle, notamment une liste des variables de rôle disponibles et des instructions d'utilisation.
L'une des variables à définir pour le rôle ha_cluster est la variable ha_cluster_hacluster_password. Elle définit le mot de passe de l'utilisateur hacluster. J'utilise Ansible Vault pour chiffrer sa valeur afin qu'elle ne soit pas stockée en texte clair.
[ansible@controlnode ~]$ ansible-vault encrypt_string 'your-hacluster-password' --name ha_cluster_hacluster_password
New Vault password:
Confirm New Vault password:
ha_cluster_hacluster_password: !vault |
$ANSIBLE_VAULT;1.1;AES256 376135336466646132313064373931393634313566323739363365616439316130653539656265373663636632383930323230343731666164373766353161630a303434316333316264343736336537626632633735363933303934373666626263373962393333316461616136396165326339626639663437626338343530360a39366664336634663237333039383631326263326431373266616130626333303462386634333430666333336166653932663535376538656466383762343065
Encryption successfulRemplacez la variable your-hacluster-password par le mot de passe de votre choix. Quand vous exécuterez la commande, vous devrez renseigner un mot de passe Vault qui pourra être utilisé pour déchiffrer la variable lors de l'exécution du playbook. Après avoir indiqué un mot de passe Vault et l'avoir saisi une seconde fois pour le confirmer, la variable chiffrée s'affichera dans la sortie. Elle sera ensuite placée dans le fichier de variables, créé à l'étape suivante.
À présent, pour définir les variables des nœuds de cluster listés dans le groupe d'inventaires rhel8_cluster, je crée un fichier sous ha_cluster/group_vars/rhel8_cluster.yml en saisissant le contenu suivant :
---
ha_cluster_cluster_name: rhel8-cluster
ha_cluster_hacluster_password: !vault |
$ANSIBLE_VAULT;1.1;AES256
3761353364666461323130643739313936343135663237393633656164393161306535
39656265373663636632383930323230343731666164373766353161630a3034343163
3331626434373633653762663263373536393330393437366662626337396239333331
6461616136396165326339626639663437626338343530360a39366664336634663237
3330393836313262633264313732666161306263333034623866343334306663333361
66653932663535376538656466383762343065
ha_cluster_fence_agent_packages:
- fence-agents-apc-snmp
ha_cluster_resource_primitives:
- id: myapc
agent: stonith:fence_apc_snmp
instance_attrs:
- attrs:
- name: ipaddr
value: apc-switch
- name: pcmk_host_map
value: rhel8-node1:1;rhel8-node2:2
- name: login
value: apc
- name: passwd
value: apc
- id: my_lvm
agent: ocf:heartbeat:LVM-activate
instance_attrs:
- attrs:
- name: vgname
value: my_vg
- name: vg_access_mode
value: system_id
- id: my_fs
agent: ocf:heartbeat:Filesystem
instance_attrs:
- attrs:
- name: device
value: /dev/my_vg/my_lv
- name: directory
value: /var/www
- name: fstype
value: ext4
- id: VirtualIP
agent: ocf:heartbeat:IPaddr2
instance_attrs:
- attrs:
- name: ip
value: 198.51.100.3
- name: cidr_netmask
value: 24
- id: Website
agent: ocf:heartbeat:apache
instance_attrs:
- attrs:
- name: configfile
value: /etc/httpd/conf/httpd.conf
- name: statusurl
value: http://127.0.0.1/server-status
ha_cluster_resource_groups:
- id: apachegroup
resource_ids:
- my_lvm
- my_fs
- VirtualIP
- WebsiteLe rôle ha_cluster va alors créer un cluster nommé rhel8-cluster sur les nœuds.
Un périphérique de fencing, myapc, de type stonith:fence_apc_snmp, sera défini dans le cluster. Ce périphérique est accessible à l'adresse IP apc-switch en utilisant le nom de connexion apc et le mot de passe apc. Il alimente les nœuds de cluster : rhel8-node1 est connecté au socket 1 et rhel8-node2 est connecté au socket 2. Étant donné qu'aucun autre périphérique de fencing ne sera utilisé, j'ai défini la variable ha_cluster_fence_agent_packages. Cette action remplace sa valeur par défaut et empêche ainsi l'installation d'autres agents de fencing.
Quatre ressources seront exécutées dans le cluster :
- Le groupe de volumes LVM my_vg sera activé par la ressource my_lvm de type ocf:heartbeat:LVM-activate.
- Le système de fichiers ext4 sera monté à partir du périphérique de stockage partagé /dev/my_vg/my_lv sur /var/www par la ressource my_fs de type ocf:heartbeat:Filesystem.
- L'adresse IP flottante 198.51.100.3/24 pour le serveur HTTP sera gérée par la ressource VirtualIP de type ocf:heartbeat:IPaddr2.
- Le serveur HTTP sera représenté par une ressource Website de type ocf:heartbeat:apache. Son fichier de configuration sera stocké sous /etc/httpd/conf/httpd.conf et la page d'état de surveillance sera accessible à l'adresse http://127.0.0.1/server-status.
Toutes les ressources seront placées dans un groupe apachegroup pour les exécuter sur un seul nœud et les démarrer dans l'ordre spécifié : my_lvm, my_fs, VirtualIP, Website.
Création du playbook
L'étape suivante consiste à créer le fichier de playbook sous ha_cluster/ha_cluster.yml en saisissant le contenu suivant :
---
- name: Deploy a cluster
hosts: rhel8_cluster
roles:
- rhel-system-roles.ha_clusterCe playbook appelle le rôle système ha_cluster pour tous les systèmes définis dans le groupe d'inventaires rhel8_cluster.
Exécution du playbook
À ce stade, tout est en place et je suis prêt à lancer le playbook. Pour cette démonstration, j'utilise un nœud de contrôle RHEL et j'exécute le playbook à partir de la ligne de commande. J'utilise la commande cd pour accéder au répertoire ha_cluster, puis la commande ansible-playbook pour exécuter le playbook.
[ansible@controlnode ~]$ cd ha_cluster/ [ansible@controlnode ~]$ ansible-playbook -b -i inventory.yml --ask-vault-pass ha_cluster.yml
J'indique que le playbook ha_cluster.yml doit être exécuté, qu'il doit s'exécuter en tant que root (indicateur -b), que le fichier inventory.yml doit être utilisé comme inventaire Ansible (indicateur -i), et qu'un mot de passe Vault doit être fourni pour déchiffrer la variable ha_cluster_hacluster_password (indicateur --ask-vault-pass).
Une fois l'exécution du playbook terminée, il faut vérifier qu'aucune tâche n'a échoué :
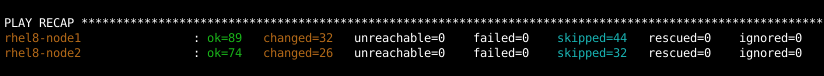
Validation de la configuration
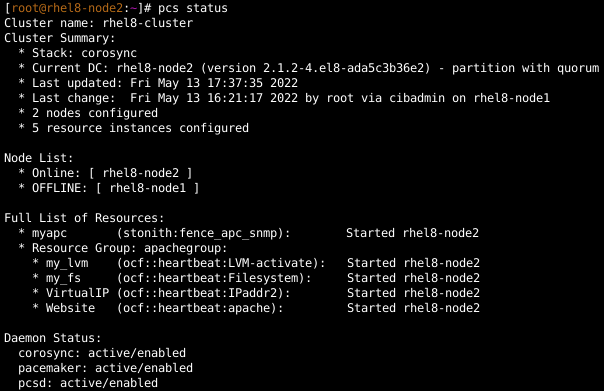
Pour confirmer que le cluster a été configuré et qu'il exécute les ressources, je me connecte au nœud rhel8-node1 et j'affiche l'état du cluster :

Je vérifie également l'état sur le nœud rhel8-node2, qui affiche la même sortie.
Ensuite, j'ouvre un navigateur web et je me connecte à l'adresse IP 198.51.100.3 pour vérifier que le site web est accessible.
Pour tester le basculement, je retire un câble réseau du nœud rhel8-node1. Au bout d'un moment, le cluster bascule et isole le nœud rhel8-node1. Je me connecte au nœud rhel8-node2 et j'affiche l'état du cluster. Il montre que toutes les ressources ont migré depuis le nœud rhel8-node1 vers le nœud rhel8-node2. Je charge à nouveau le site web dans le navigateur pour vérifier qu'il est toujours accessible.
Je reconnecte le nœud rhel8-node1 au réseau et le redémarre pour qu'il rejoigne le cluster.
Conclusion
Le rôle système RHEL ha_cluster peut vous aider à configurer rapidement et de manière cohérente des clusters RHEL haute disponibilité qui exécutent différentes charges de travail. Dans cet article, j'ai expliqué comment utiliser ce rôle pour configurer un serveur HTTP Apache qui exécute un site web à partir d'un périphérique de stockage partagé en mode actif/passif.
Red Hat propose de nombreux rôles système RHEL qui peuvent vous aider à automatiser d'autres aspects importants de votre environnement RHEL. Pour découvrir d'autres rôles, consultez cette liste des rôles système RHEL disponibles et commencez dès maintenant à gérer vos serveurs RHEL de façon plus efficace, cohérente et automatisée.
Pour en savoir plus sur Red Hat Ansible Automation Platform, découvrez notre livre numérique intitulé Le manuel de l'architecte de l'automatisation.
À propos de l'auteur

Tomas Jelinek is a Software Engineer at Red Hat with over seven years of experience with RHEL High Availability clusters.
Plus de résultats similaires
Planification de votre parcours de mise à niveau vers Red Hat Ansible Automation Platform 2.6
Favoriser la stabilité à long terme : Présentation de Red Hat Enterprise Linux Extended Life Cycle, Premium
Technically Speaking | Taming AI agents with observability
You Can’t Automate The Difficult Decisions | Code Comments
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud