
L'adoption et le développement de l'IA se sont accélérés avec l'IA générative et l'IA agentique, qui touchent désormais le grand public. Face à l'émergence de nouveaux marchés, les entreprises peinent à tirer parti de l'IA pour obtenir un retour sur investissement concret. Bien que les GPU aient dominé l'infrastructure, l'augmentation des coûts et la diminution de la disponibilité en raison de la demande ont incité les dirigeants à rechercher des alternatives qui répondent toujours aux exigences de performance et aux normes de satisfaction de la clientèle.
Parallèlement, les développeurs et les ingénieurs qui travaillent sur l'IA sont confrontés à des difficultés liées à la configuration d'une infrastructure complexe et chronophage, ainsi qu'à la création de piles logicielles et d'architectures pour une inférence optimale des grands modèles linguistiques (LLM) avec la génération augmentée de récupération (RAG). La facilité d'utilisation, la sécurité des données propriétaires, et même la façon de se lancer dans la construction de l'IA, sont des défis techniques qui peuvent empêcher les développeurs d'entrer dans l'IA.
La collaboration entre Intel et Red Hat combine les performances des processeurs Xeon à l'évolutivité de Red Hat OpenShift AI, offrant ainsi une base protégée et flexible pour le déploiement de l'IA agentique dans l'entreprise. Sur cette plateforme, les clients peuvent créer des modèles d'IA et d'apprentissage automatique et des applications de manière plus sécurisée à l'échelle dans des environnements de cloud hybride.
Pour simplifier le processus d'adoption, Intel a créé un certain nombre de guides de démarrage rapide pour l'IA. Les guides de démarrage rapide pour l'IA sont des exemples de cas d'utilisation commerciale réels qui peuvent être déployés rapidement sur Xeon avec OpenShift, accélérant ainsi le développement et la mise sur le marché. Ces guides de démarrage rapide sont disponibles dans le catalogue AI Quickstarts.
Pourquoi l'IA sur Xeon ?
Bien que les GPU aient dominé l'apprentissage profond, l'IA générative et l'IA agentique, l'inférence peut utiliser des plateformes de calcul plus petites et plus rentables pour répondre aux exigences fonctionnelles et de performances. Les processeurs sont depuis toujours la plateforme de choix pour le traitement et l'analyse des données, ainsi que pour l'apprentissage automatique classique. Cela comprend la régression, la classification, le clustering et les arbres de décision, à l'aide de méthodes telles que les machines à vecteurs de support, XGBoost et K-means. Les cas d'utilisation incluent les prévisions financières et de vente au détail, la détection des fraudes et l'optimisation de la chaîne d'approvisionnement. À long terme, cette approche contribue à la gestion des coûts de l'infrastructure d'IA. Intel Xeon est bien positionné en tant que nœud principal pour ces types de plateformes plus petites.
Fonctionnalités matérielles d'Intel Xeon
Les fonctionnalités matérielles sont ce qui distingue Xeon en tant que plateforme de processeur viable pour l'IA. Le jeu d'instructions Advanced Matrix Extensions (AMX) et la bande passante mémoire élevée avec les modules Multiplexed Rank Dual In-line Memory Modules (MRDIMM) sont les principaux composants qui permettent à Xeon de se démarquer.
Le composant AMX a été introduit dans les processeurs Intel® Xeon® Scalable de 4e génération en tant qu'accélérateur d'IA intégré, un bloc matériel dédié sur les cœurs, afin d'effectuer des calculs matriciels au lieu de dépendre d'un accélérateur distinct. Il prend en charge les types de données de précision inférieure, notamment Bfloat16 (BF16) et INT8. L'un des principaux avantages de BF16 est l'amélioration des performances sans sacrifier la précision par rapport à FP32. Les accélérations avec AMX réduisent la consommation d'énergie et l'utilisation des ressources, et accélèrent le développement grâce à ses optimisations intégrées aux frameworks d'IA tels que PyTorch et TensorFlow.
Les systèmes de recommandation, le traitement du langage naturel, l'IA générative, l'IA agentique et la vision par ordinateur bénéficient tous d'AMX, ce qui augmente la valeur métier et la satisfaction de l'utilisateur final.

Figure 1 : Intel® AMX comprend des tuiles de registre 2D avec des instructions de multiplication de matrices TMUL pour calculer de grandes matrices en une seule opération.
Dans l'inférence d'IA et de LLM, le goulot d'étranglement de la mémoire est la mise en cache clé-valeur (KV) due à la forte demande de mémoire. MRDIMMS répond à ce problème en faisant passer la complexité du calcul de quadratique à linéaire, offrant ainsi une bande passante mémoire supérieure de plus de 37 % à celle des RDIMMS. Cela améliore le débit de la mémoire et réduit la latence lors du traitement des tâches gourmandes en données pendant l'inférence de l'IA. Dans les systèmes où la mémoire GPU est limitée, les processeurs Xeon peuvent décharger les données KV, libérant ainsi de coûteuses ressources GPU tout en maintenant des performances élevées.
Xeon présente plusieurs cas d'utilisation pratiques dans l'IA : inférence, RAG et traitement sécurisé des données, et IA agentique. À la fois fonctionnelle et performante, Xeon est une plateforme dotée d'un logiciel de support pour répondre aux besoins de l'IA sans nécessiter de GPU.
Cas d'utilisation de Xeon 1 : Inférence d'IA
L'inférence LLM alimente des applications telles que les chatbots d'entreprise, la synthèse de documents, les assistants de code et les pipelines RAG. Pour les entreprises de taille moyenne et les organisations qui recherchent une IA générative rentable sans investissements importants dans les GPU, Xeon peut être une option plus intéressante. Xeon fonctionne de manière optimale avec les LLM de petite à moyenne taille et les modèles MOE (mixture-of-experts) jusqu'à 13 milliards de paramètres, tout en respectant des normes telles que le délai d'attente jusqu'au premier jeton (TTFT) de trois secondes et le délai d'attente par jeton de sortie de 100 ms.
Intel travaille en étroite collaboration avec la communauté open source pour optimiser l'inférence de l'IA, notamment vLLM et SGLang. vLLM est un moteur de service d'inférence pour un débit élevé et une efficacité de la mémoire élevée. Le tableau de bord vLLM pour Xeon sur Pytorch.org contient des chiffres de performance publiés de LLM populaires, notamment Llama-3.1-8B-Instruct sur Xeon. Intel continue d'améliorer les performances et d'ajouter la prise en charge à une liste de modèles validés. SGLang est un autre framework de service rapide qu'Intel s'efforce d'intégrer à Xeon.
Cas d'utilisation de Xeon 2 : RAG et traitement sécurisé des données
RAG est efficace pour obtenir des résultats précis des LLM sans avoir à réentraîner les modèles. La base de connaissances est créée en préparant les données à l'aide de l'analyse de documents, du découpage et de l'extraction de métadonnées afin de créer des incorporations qui sont ensuite stockées dans une base de données vectorielle. Toutes les opérations peuvent être effectuées en toute sécurité grâce aux extensions Intel® Trust Domain Extensions (TDX), une technologie d'informatique confidentielle basée sur le matériel. TDX utilise des machines virtuelles (VM) isolées matériellement pour protéger les données et les applications contre tout accès non autorisé. Cela permet aux entreprises d'exploiter rapidement les données propriétaires disponibles pour l'automatisation du support client, la récupération de documents et la recherche juridique. La latence de récupération est faible et les requêtes simultanées peuvent être traitées avec Xeon.

Figure 2 : Intel® TDX utilise des extensions matérielles pour gérer et chiffrer la mémoire afin de protéger la confidentialité et l'intégrité des données.
Cas d'utilisation de Xeon 3 : IA agentique
Les agents d'IA suivent une logique séquentielle de planification, d'action, d'observation et de réflexion. Elle utilise une charge de travail mixte impliquant l'inférence LLM et l'exécution d'outils, des requêtes de base de données aux appels d'API en passant par l'accès aux fichiers. Xeon prend en charge les serveurs MCP (Model Context Protocol), les API agentiques LlamaStack, LangChain et CrewAI. L'automatisation des opérations informatiques, l'aide à la décision financière et les agents de la chaîne d'approvisionnement sont des cas d'utilisation métier ciblés.
Xeon sur OpenShift : Nouveautés
Red Hat OpenShift AI est une plateforme d'IA de niveau entreprise pour la gestion du cycle de vie complet de la création, de la formation et du déploiement de modèles et d'applications d'IA à l'échelle dans le cloud hybride, sur site et dans les environnements périphériques. Parmi les technologies incluses dans OpenShift AI, vLLM offre une diffusion de modèles optimisée à haut débit et à faible latence tout en réduisant les coûts matériels. Il existe une collection de modèles tiers optimisés, prêts pour la production et validés qui donnent aux équipes de développement plus de contrôle sur l'accessibilité et la visibilité des modèles afin de répondre aux exigences de sécurité et de politique. Tout cela peut être déployé automatiquement avec des outils avancés pour lancer vos projets d'IA et réduire la complexité opérationnelle. Dans l'ensemble, les applications d'IA peuvent être mises en production à grande échelle plus rapidement.
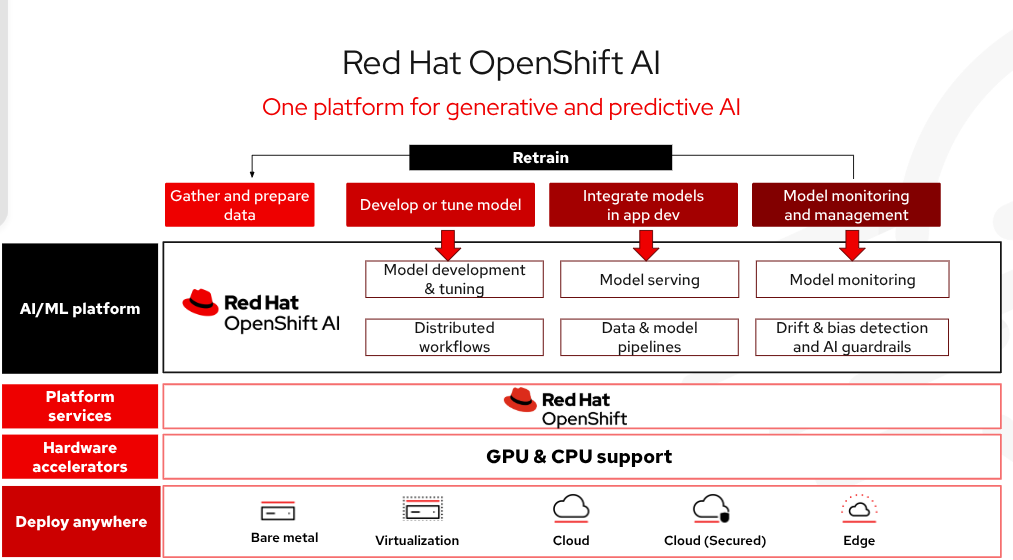
Figure 3 : Red Hat OpenShift AI est une plateforme flexible et évolutive d'intelligence artificielle (IA) et d'apprentissage automatique (AA) qui permet aux entreprises de créer et de fournir des applications compatibles avec l'IA à l'échelle dans des environnements de cloud hybride.
Fonctionnalités
La gestion de l'infrastructure d'IA prendra moins de temps, car les modèles à hautes performances peuvent être facilement déployés avec Models-as-a-Service (MaaS) et accessibles avec des points de terminaison API. Il existe une flexibilité dans le cloud hybride en tant que logiciel autogéré protégé et flexible sur du matériel nu, des environnements virtuels ou toutes les principales plateformes de cloud public. Red Hat a testé et intégré des outils courants d'IA/ML open source et de diffusion de modèles afin qu'ils soient faciles à utiliser pour les développeurs. OpenShift AI inclut également llm-d, un framework open source pour l'inférence d'IA distribuée à l'échelle.
Image de processeur vLLM
Intel a mis à disposition une image vLLM pour processeur sur Dockerhub construite sur l'image de base universelle de Red Hat. L'image est construite avec AMX activé. Par conséquent, les processeurs Xeon® Scalable® de 4e génération ou plus récents sont nécessaires pour exécuter cette image. Désormais, de nombreux modèles open source peuvent être déployés rapidement et exécuter l'inférence avec un débit élevé et une faible latence dès le départ.
Démarrages rapides pour l'IA
Disponibles dans le catalogue de démarrage rapide de l'IA sur redhat.com, sont des exemples de cas d'utilisation métier prêts à l'emploi qui exécutent les modèles de manière optimale avec vLLM sur Xeon, optimisé par OpenShift AI. Les développeurs peuvent considérer ces exemples comme des points de départ et les personnaliser en fonction de leurs besoins ou les utiliser tels quels. Les premières versions préliminaires de plusieurs démarrages rapides d'IA sont disponibles sur GitHub et s'exécutent prêtes à l'emploi sur Xeon, tous les démarrages rapides finalisés étant publiés via le catalogue de démarrage rapide d'IA.
- Serveur MCP LlamaStack : déploie les LLM avec vLLM à l'aide de serveurs MCP tels que les outils de rapports météorologiques et de RH.
- LLM CPU Serving : un assistant de chat léger pour le leadership et la stratégie de l'IA servant un petit modèle de langage
- RAG : utilisez la génération augmentée de récupération pour améliorer les LLM avec des sources de données spécialisées pour des réponses plus précises et tenant compte du contexte
- Appel d'outil vLLM : déploie les LLM à l'aide de vLLM avec l'appel de fonction
Étapes suivantes
L'IA sur Xeon est facilitée avec Red Hat OpenShift AI. L'environnement géré et protégé configure l'infrastructure d'IA nécessaire au développement, au déploiement et à l'observabilité.
- Consultez le tableau de bord vLLM pour Xeon pour connaître les chiffres de performance et la documentation vLLM pour créer/télécharger les images vLLM pour le processeur avec la prise en charge d'AMX.
- Utilisez le vLLM pour le processeur basé sur l'image de base universelle Red Hat à partir de DockerHub.
- Consultez la liste des modèles pris en charge pour Xeon.
- Explorez le catalogue de démarrage rapide de l'IA pour des exemples prêts à l'emploi et visitez le Github de démarrage rapide de l'IA pour les démarrages rapides de l'IA qui sont encore en cours de développement.
- Consultez le site Red Hat OpenShift AI.
Produit
Red Hat AI
À propos de l'auteur
Plus de résultats similaires
Les menaces liées à l'IA évoluent. Vos défenses doivent en faire autant.
L'avenir de l'IA nécessite une base hybride
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud