

InstructLab est un projet communautaire qui permet de contribuer aux grands modèles de langage (LLM) et de les améliorer plus facilement grâce à la génération de données synthétiques. Il aide les équipes de développement à relever plusieurs défis, notamment la complexité de la contribution aux LLM, la prolifération des modèles causée par les « forks » et le manque de gouvernance directe de la communauté. Soutenu par Red Hat et IBM Research, le projet InstructLab s'appuie sur de nouvelles méthodes de réglage de l'alignement basées sur des données synthétiques pour améliorer les performances et l'accessibilité des modèles. Dans cet article, nous nous intéressons au problème et aux défis techniques que pose actuellement le réglage fin traditionnel des modèles, ainsi qu'à la solution qu'offre InstructLab.
Le problème : des données de mauvaise qualité et une utilisation inefficace des ressources de calcul
L'intensification de la concurrence dans le domaine des LLM incite les différents acteurs à créer des modèles de plus en plus grands, entraînés à partir d'énormes quantités d'informations disponibles librement sur Internet. Cependant, en raison de la présence d'informations redondantes et de données en langage non naturel, cette approche n'enrichit pas les fonctionnalités de base du modèle.
Par exemple, 80 % des jetons textuels utilisés pour entraîner le LLM GPT-3 (sur lequel reposent les versions ultérieures) proviennent de Common Crawl, qui inclut de très nombreuses pages web. Cet ensemble de données est réputé contenir un mélange de textes de haute qualité, de textes de mauvaise qualité, de scripts et d'autres données en langage non naturel. On estime qu'une grande partie de ces données est inutile ou inintéressante (d'après une analyse de Common Crawl).
La forte présence de ces données superflues empêche d'utiliser efficacement les ressources de calcul, ce qui occasionne des coûts d'entraînement élevés obligeant les utilisateurs à payer plus pour ces modèles, ainsi que des difficultés pour mettre en œuvre les modèles dans des environnements locaux.
D'après nos observations, de plus en plus de modèles contenant moins de paramètres sont créés pour privilégier la qualité et la pertinence des données, qui jouent un rôle plus important que la quantité totale de paramètres. Lorsque la sélection des données est plus précise et préparée, les modèles sont plus performants, nécessitent moins de ressources de calcul et produisent des résultats de meilleure qualité.
La solution d'InstructLab : un processus perfectionné de génération de données synthétiques
La particularité du projet InstructLab est qu'il permet de générer de grandes quantités de données pour l'entraînement à partir d'un petit ensemble de données. Il utilise la méthode LAB (Large-scale Alignment for chatBots), qui améliore les LLM en réduisant au minimum les données générées par l'humain et les coûts de calcul. Les utilisateurs peuvent ainsi apporter leur contribution de manière intuitive, en comptant sur la génération de données synthétiques pour améliorer les données à l'aide d'un modèle.

Principaux avantages de l'approche d'InstructLab :
Sélection des données en fonction de la taxonomie
Tout commence par la création d'une taxonomie, c'est-à-dire une structure hiérarchique qui organise les différents domaines de compétences et de connaissances. Cette taxonomie sert de feuille de route pour sélectionner les premiers exemples générés par l'humain, qui serviront de données de départ pour le processus de génération de données synthétiques. Les données sont organisées dans une structure qui aide à identifier facilement ce que le modèle connaît déjà et ce qu'il peut apprendre, réduisant ainsi les informations redondantes et désordonnées. Cette approche permet également de cibler un modèle pour un cas d'utilisation ou des besoins spécifiques, en se basant uniquement sur des fichiers YAML au format simple de questions-réponses.

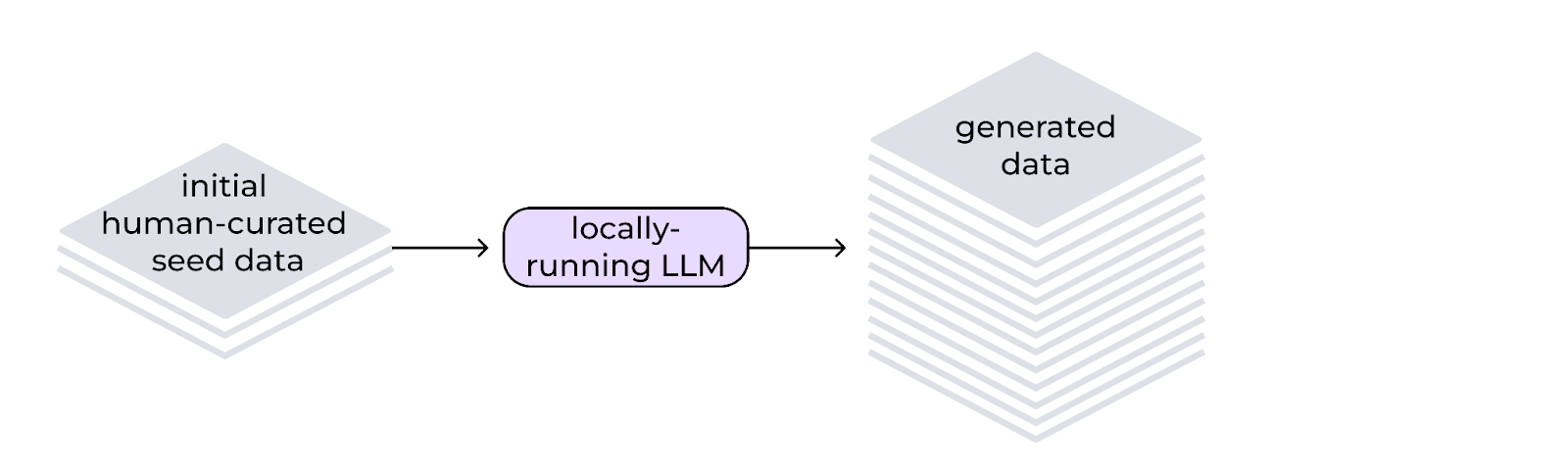
Processus de génération de données synthétiques
À partir des données d'origine, InstructLab exploite un modèle de type professeur pour générer de nouveaux exemples dans le cadre du processus de génération de données. Ce processus n'utilise pas des connaissances stockées par le modèle professeur, mais des modèles particuliers d'instructions génératives qui enrichissent considérablement l'ensemble de données. Ces modèles permettent également de s'assurer que les nouveaux exemples conservent la structure et l'objet des données d'origine sélectionnées par l'utilisateur. La méthode LAB utilise deux générateurs de données synthétiques :
- Skills-SDG (Skills Synthetic Data Generator) : utilise des modèles d'instructions génératives pour la génération d'instructions, l'évaluation, la génération de réponses et l'évaluation finale des paires
- Knowledge-SDG : génère des données d'instruction pour les domaines non couverts par le modèle professeur à l'aide de sources de connaissances externes, afin de fournir une base aux données générées
Avec cette méthode, il n'est donc plus nécessaire d'utiliser autant de données annotées manuellement. L'utilisation de petits exemples uniques et générés par l'humain comme référence permet de sélectionner des centaines, des milliers, voire des millions de paires de question-réponse pour influencer les pondérations et les biais du modèle.
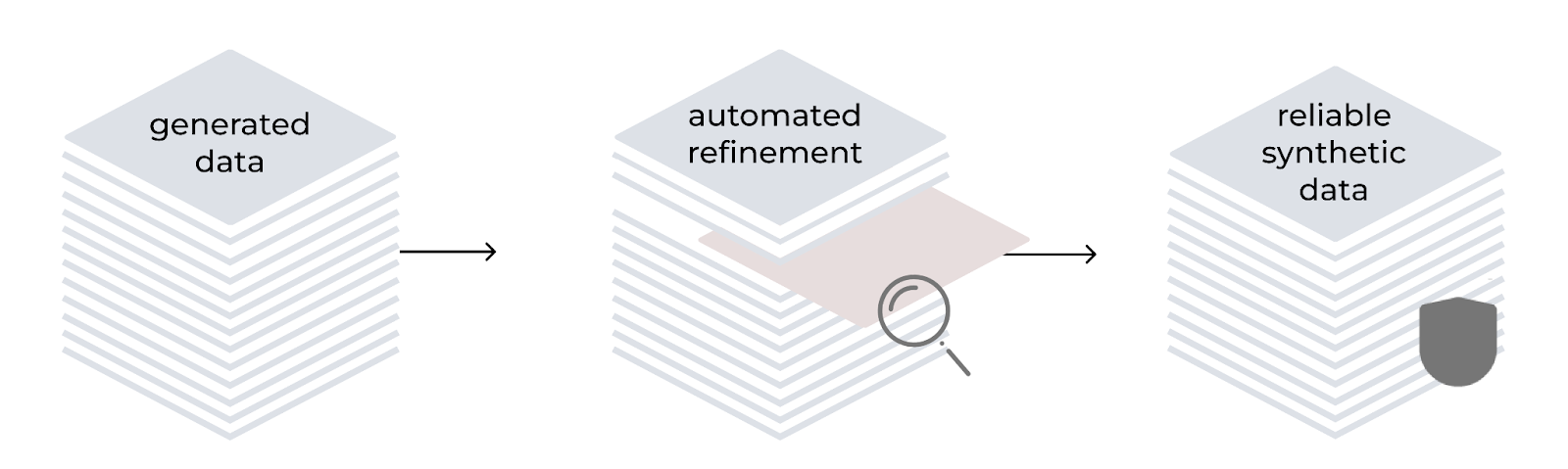
Perfectionnement automatisé
La méthode LAB comprend un processus automatisé de perfectionnement pour améliorer la qualité et la fiabilité des données d'entraînement synthétiques. Conformément à la hiérarchie définie dans la taxonomie, elle utilise le modèle comme générateur et évaluateur. Le processus englobe la génération d'instructions, le filtrage des contenus, la génération de réponses et l'évaluation des paires à l'aide d'un système de notation à trois points. Pour les tâches qui impliquent des connaissances spécialisées, les contenus générés se fondent sur des documents sources fiables afin d'éviter toute inexactitude.
Processus de réglage en plusieurs phases
InstructLab met en œuvre un processus d'entraînement en plusieurs phases pour améliorer progressivement les performances du modèle. Cette approche contribue à la stabilité de l'entraînement. Un tampon de relecture prévient également les oublis catastrophiques, ce qui permet au modèle d'apprendre et de s'améliorer en continu. Les données synthétiques générées sont utilisées dans le cadre d'un processus de réglage en deux phases :
- Réglage des connaissances : phase d'intégration de nouvelles informations factuelles lors d'un entraînement axé sur les réponses courtes puis longues, ainsi que sur les compétences de base
- Réglage des compétences : phase d'amélioration de la capacité du modèle à appliquer les connaissances à une variété de tâches et de contextes, en mettant l'accent sur les compétences de composition

Le processus repose sur de faibles taux d'apprentissage, de longues périodes d'échauffement et de grands lots efficaces pour garantir la stabilité.
Cycle d'amélioration par itération
Le processus de génération de données synthétiques est conçu pour être itératif. À mesure que de nouvelles contributions sont apportées à la taxonomie, elles peuvent être utilisées pour générer de nouvelles données synthétiques, et ainsi améliorer davantage le modèle. Ce cycle d'amélioration continue permet de s'assurer que le modèle reste à jour et pertinent.
Résultats et importance d'InstructLab
InstructLab est un projet majeur, car il offre les moyens d'atteindre des performances de pointe avec des modèles professeurs accessibles au public, plutôt qu'avec des modèles propriétaires. Dans les tests de performances, la méthode InstructLab a donné des résultats prometteurs. Appliqués à Llama-2-13b (à la base de Labradorite-13b) et à Mistral-7B (à la base de Merlinite-7B), les modèles entraînés avec la méthode LAB ont obtenu des scores MT-Bench supérieurs à ceux des meilleurs modèles actuels, dont le réglage fin a été effectué sur leurs modèles de base respectifs. Ils ont également démontré d'excellentes performances dans d'autres domaines, notamment pour les indicateurs MMLU (test de la compréhension linguistique multitâche), ARC (évaluation des capacités de raisonnement) et HellaSwag (évaluation de l'inférence logique).

Collaboration et accessibilité de la communauté
L'un des principaux avantages d'InstructLab est sa nature Open Source. Son objectif est de faciliter l'accès à l'IA générative pour que tout le monde puisse façonner l'avenir des modèles. Parce que son interface en ligne de commande est compatible avec le matériel courant, comme les ordinateurs portables, il est facilement accessible aux développeurs et aux divers contributeurs. En outre, le projet InstructLab encourage l'implication de la communauté : les membres peuvent ajouter de nouvelles connaissances ou compétences à un modèle de base, régulièrement assemblé et publié sur Hugging Face. N'hésitez pas à consulter le modèle le plus récent ici.

Le processus de génération de données synthétiques d'InstructLab, basé sur la méthode LAB, marque un progrès significatif dans le domaine de l'IA générative. En enrichissant les LLM avec de nouvelles capacités et de nouveaux domaines de connaissances, InstructLab favorise une approche plus collaborative et plus efficace du développement de l'IA. Si vous souhaitez en savoir plus sur le projet, rendez-vous sur instructlab.ai ou consultez ce guide de démarrage pour essayer InstructLab sur votre machine.
À propos des auteurs
Cedric Clyburn (@cedricclyburn), Senior Developer Advocate at Red Hat, is an enthusiastic software technologist with a background in Kubernetes, DevOps, and container tools. He has experience speaking and organizing conferences including DevNexus, WeAreDevelopers, The Linux Foundation, KCD NYC, and more. Cedric loves all things open-source, and works to make developer's lives easier! Based out of New York.
Legare Kerrison is a Technical Marketing Manager and Developer Advocate working on Red Hat's Artificial Intelligence offerings. She is passionate about open source AI and making technical knowledge accessible to all. She is based out of Boston, MA.
Plus de résultats similaires
Au-delà de l'automatisation : pourquoi la montée des vulnérabilités de sécurité liées à l'IA exige une expertise technique humaine
Amélioration des capacités post-quantiques de SSH dans Red Hat Enterprise Linux
Untangling Networks | Compiler
Technically Speaking | Defining sovereign AI with open source
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud