
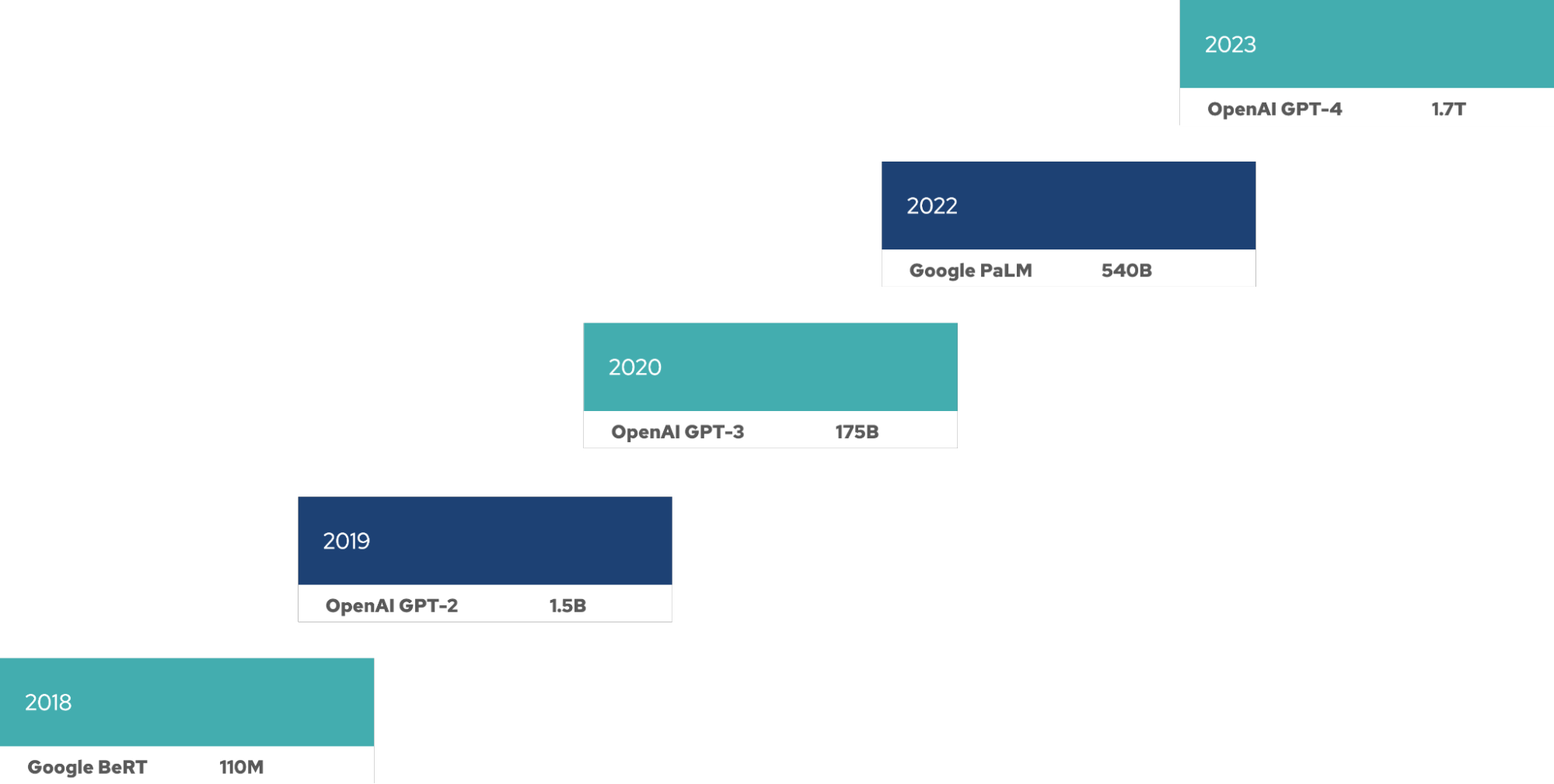
Il semblerait que tous les grands modèles de langage (LLM) gagnent en taille à chaque nouvelle version. Il faut donc un nombre important de GPU pour entraîner le modèle, et davantage de ressources sont nécessaires tout au long du cycle de vie de ces modèles pour le réglage fin, l'inférence, etc. Il existe une nouvelle loi de Moore qui s'applique à ces LLM : ils doublent en taille (selon le nombre de paramètres) tous les quatre mois.
Le coût des LLM
L'entraînement et l'exploitation d'un LLM nécessitent à la fois du temps, des ressources et de l'argent. Les exigences en matière de ressources ont des conséquences directes sur son déploiement, que ce soit sur sa propre infrastructure ou à l'aide d'un hyperscaler. En parallèle, la taille des LLM continue d'augmenter.
Par ailleurs, l'exploitation d'un LLM nécessite une quantité considérable de ressources. Le LLM Llama 3.1 contient 405 milliards de paramètres, ce qui nécessite 810 Go de mémoire (FP16) rien que pour l'inférence. La famille de modèles Llama 3.1 a été entraînée à partir de 15 000 milliards de jetons textuels dans un cluster de GPU totalisant 39 millions d'heures de GPU. Parallèlement à l'augmentation exponentielle de la taille des LLM, les besoins en calcul et en mémoire pour leur entraînement et leur exploitation augmentent également. Le réglage fin de Llama 3.1 nécessite 3,25 To de mémoire.
L'année dernière, nous avons constaté une pénurie intense de GPU, et tandis que l'écart entre l'offre et la demande se creuse, le prochain goulet d'étranglement devrait être lié à l'alimentation. Avec l'ajout de nouveaux datacenters et le doublement de la consommation électrique de chaque datacenter à presque 150 MW, il est clair que cette évolution pourrait devenir un problème pour le secteur de l'IA.
Réduction du coût des LLM
Avant de discuter de la manière de réduire le coût des LLM, prenons un exemple que nous connaissons tous. Les caméras s'améliorent constamment. De nouveaux modèles apparaissent qui permettent d'obtenir des résolutions plus élevées que jamais. Cependant, chaque fichier image brut peut atteindre 40 Mo (voire plus). À moins que vous ne soyez un professionnel des médias et que vous ayez besoin de manipuler ces images, la plupart des utilisateurs acceptent d'utiliser une version JPEG pour réduire la taille du fichier de 80 %. Il est vrai que la compression JPEG réduit la qualité de l'image des données brutes d'origine, mais dans la plupart des cas, ce format suffit. De plus, des applications spéciales sont généralement nécessaires pour traiter et afficher une image brute. Le coût de calcul des images brutes est donc plus élevé qu'avec une image JPEG.
Revenons à présent aux LLM. La taille du modèle dépend du nombre de paramètres. Une approche consiste donc à utiliser un modèle avec un nombre inférieur de paramètres. Tous les modèles Open Source fréquemment utilisés s'accompagnent d'une série de paramètres, ce qui vous permet de choisir les modèles qui conviennent le mieux à une application donnée.

Toutefois, un LLM qui possède un grand nombre de paramètres est généralement plus performant dans la plupart des tests que celui qui en contient moins. Pour réduire les besoins en ressources, il peut être préférable d'utiliser un modèle de paramètres plus grand, mais en le compressant pour en réduire la taille. Des tests ont montré que la compression GAN peut réduire le calcul de près de 20 fois.
Il existe plusieurs dizaines d'approches pour compresser un LLM, notamment la quantification, l'élagage, la distillation des connaissances et la réduction de couches.
Quantification
La quantification fait passer les valeurs numériques d'un modèle depuis un format en virgule flottante codé sur 32 bits à un type de données avec moins de précision : un nombre à virgule flottante de 16 bits, un entier de 8 bits, un entier de 4 bits, voire un entier de 2 bits. En diminuant la précision du type de données, le modèle requiert moins de bits lors des opérations, ce qui réduit les besoins en mémoire et en calcul. La quantification peut avoir lieu après ou pendant l'entraînement du modèle.
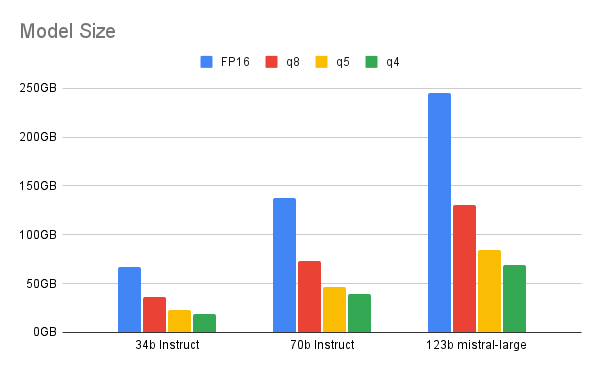
La réduction du nombre de bits implique un compromis entre la quantification et les performances. Cet article présente la plage idéale offerte par la quantification sur 4 bits pour les modèles plus grands (au moins 70 milliards de paramètres). Toute valeur inférieure entraîne un écart de performances notable entre le LLM et son équivalent quantifié. Pour un modèle plus petit, la quantification sur 6 ou 8 bits peut être un meilleur choix.
Ce processus me permet de lancer cettedémonstration de génération augmentée de récupération par LLM depuis mon ordinateur portable.
Élagage
L'élagage réduit la taille du modèle en éliminant les pondérations ou neurones moins importants. Un juste équilibre est nécessaire entre la réduction de la taille du modèle et la préservation de la précision. L'élagage peut avoir lieu avant, pendant ou après l'entraînement du modèle. L'élagage des couches va encore plus loin en supprimant des blocs entiers de couches. Dans cet article, les auteurs indiquent qu'il est possible de supprimer jusqu'à 50 % des couches en maintenant une dégradation minimale des performances.
Distillation des connaissances
Ce processus transfère les connaissances d'un grand modèle (modèle enseignant) à un modèle plus petit (modèle étudiant). Le modèle plus petit est entraîné à partir de la production du modèle plus grand au lieu de données d'entraînement plus volumineuses.
Cet article montre comment la distillation du modèle BERT de Google dans DistilBERT a permis de réduire la taille du modèle de 40 %, d'augmenter la vitesse d'inférence de 60 % et de conserver 97 % de ses capacités de compréhension du langage.
Approche hybride
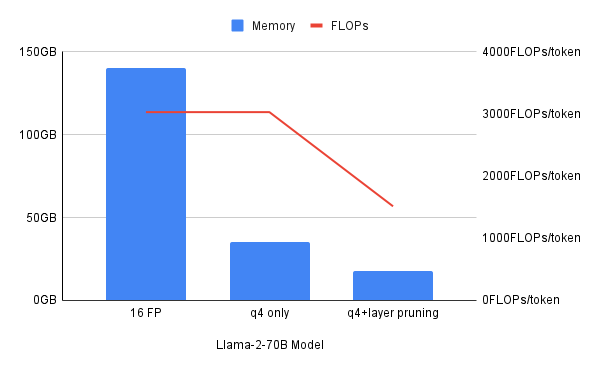
Si chacune de ces techniques de compression est utile, une approche hybride qui combine différentes techniques de compression fonctionne mieux dans certains cas. Cet article explique comment la quantification sur 4 bits permet de diviser par quatre les besoins en mémoire, mais pas les ressources de calcul mesurées en FLOPS (opérations en virgule flottante par seconde). La quantification, associée à l'élagage des couches, permet de réduire la mémoire et les ressources de calcul nécessaires.
Avantages d'un modèle plus petit
L'utilisation de modèles plus petits permet de réduire considérablement les exigences de calcul, tout en conservant un niveau élevé de performances et de précision.
- Réduction des coûts de calcul : les modèles plus petits réduisent les exigences en matière de CPU et de GPU, ce qui peut entraîner des économies considérables. Étant donné que les GPU haut de gamme peuvent coûter jusqu'à 30 000 $ pièce, toute réduction des coûts de calcul est la bienvenue.
- Diminution de l'utilisation de la mémoire : les modèles plus petits nécessitent moins de mémoire que leurs équivalents plus grands. Cette approche facilite le déploiement de modèles sur des systèmes aux ressources limitées tels que les appareils IoT (Internet des objets) ou les téléphones mobiles.
- Inférence plus rapide : les modèles plus petits peuvent se charger et s'exécuter rapidement, ce qui réduit la latence de l'inférence. Une inférence plus rapide peut faire une grande différence pour les applications en temps réel telles que les véhicules autonomes.
- Empreinte carbone réduite : la réduction des exigences de calcul des modèles plus petits permet d'améliorer l'efficacité énergétique et ainsi de réduire l'impact environnemental.
- Flexibilité du déploiement : la diminution des exigences en matière de calcul augmente la flexibilité pour le déploiement des modèles en fonction des besoins. Les modèles peuvent mieux correspondre aux besoins des utilisateurs ou des contraintes du système, notamment à la périphérie du réseau.
Les modèles plus petits et moins onéreux sont de plus en plus prisés, comme en témoignent les versions récentes de ChatGPT-4o mini (60 % moins cher que GPT-3.5 Turbo) et les innovations Open Source de SmolLM et Mistral NeMo :
- SmolLM de Hugging Face : une famille de petits modèles comptant 135 millions, 360 millions et 1,7 milliard de paramètres
- Mistral NeMo : un petit modèle comptant 12 milliards de paramètres, conçu en collaboration avec NVIDIA
Cette tendance en faveur des petits modèles de langage s'explique par les avantages susmentionnés. Il existe de nombreuses options pour les modèles plus petits : utiliser un modèle préconçu ou utiliser des techniques de compression pour réduire un LLM existant. Votre cas d'utilisation doit vous guider dans l'approche à adopter pour choisir un petit modèle. Étudiez donc bien les options qui s'offrent à vous.
À propos de l'auteur
Ishu Verma is an AI Solution Architect at Red Hat dabbling in emerging technologies like AI Ops, AI safety and security. He, along with fellow open source hackers, works on building enterprise focused solutions with open source technologies. Prior to Red Hat, Ishu worked in technical marketing at Intel on IoT Gateways and building end-to-end IoT solutions with partners.
Plus de résultats similaires
Les menaces liées à l'IA évoluent. Vos défenses doivent en faire autant.
L'avenir de l'IA nécessite une base hybride
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud