Overview
Current development cycles face many challenges such as an evolving landscape of application architecture (Monolithic to Microservices), the need to frequently deploy features, and new IaaS and PaaS environments. This causes many issues throughout the organization, from the development teams all the way to operations and management.
In this blog post, we will show you how you can set up a local system that will support MongoDB, MongoDB Ops Manager, and OpenShift. We will walk through the various installation steps and demonstrate how easy it is to do agile application development with MongoDB and OpenShift.
MongoDB is the next-generation database that is built for rapid and iterative application development. Its flexible data model—the ability to incorporate both structured or unstructured data—allows developers to build applications faster and more effectively than ever before. Enterprises can dynamically modify schemas without downtime, resulting in less time preparing data for the database, and more time putting data to work. MongoDB documents are more closely aligned to the structure of objects in a programming language. This makes it simpler and faster for developers to model how data in the application will map to data stored in the database, resulting in better agility and rapid development.
MongoDB Ops Manager (also available as the hosted MongoDB Cloud Manager service) features visualization, custom dashboards, and automated alerting to help manage a complex environment. Ops Manager tracks 100+ key database and systems health metrics including operations counters, CPU utilization, replication status, and any node status. The metrics are securely reported to Ops Manager where they are processed and visualized. Ops Manager can also be used to provide seamless no-downtime upgrades, scaling, and backup and restore.
Red Hat OpenShift is a complete open source application platform that helps organizations develop, deploy, and manage existing and container-based applications seamlessly across infrastructures. Based on Docker container packaging and Kubernetes container cluster management, OpenShift delivers a high-quality developer experience within a stable, secure, and scalable operating system. Application lifecycle management and agile application development tooling increase efficiency. Interoperability with multiple services and technologies and enhanced container and orchestration models let you customize your environment.
Below we included two videos that can give a great intro for the rest of the post.
The first video covers Red Hat OpenShift and MongoDB.
The second video we have a demo of Red Hat Ansible and MongoDB.
Blog Environment
In order to follow this examples you will need to meet a number of requirements. You will need a system with 16 GB of RAM and a RHEL 7.2 Server (we used an instance with a GUI for simplicity). The following software is also required:
- Ansible
- Vagrant
- VirtualBox
Ansible Install
Ansible is a very powerful open source automation language. What makes it unique from other management tools, is that it is also a deployment and orchestration tool. In many respects, aiming to provide large productivity gains to a wide variety of automation challenges. While Ansible provides more productive drop-in replacements for many core capabilities in other automation solutions, it also seeks to solve other major unsolved IT challenges.
We will install the Automation Agent onto the servers that will become part of the MongoDB replica set. The Automation Agent is part of MongoDB Ops Manager.
In order to install Ansible using yum you will need to enable the EPEL repository. The EPEL (Extra Packages for Enterprise Linux) is repository that is driven by the Fedora Special Interest Group. This repository contains a number of additional packages guaranteed not to replace or conflict with the base RHEL packages.
The EPEL repository has a dependency on the Server Optional and Server Extras repositories. To enable these repositories you will need to execute the following commands:
$ sudo subscription-manager repos --enable rhel-7-server-optional-rpms
$ sudo subscription-manager repos --enable rhel-7-server-extras-rpms
To install/enable the EPEL repository you will need to do the following:
$ wget https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
$ sudo yum install epel-release-latest-7.noarch.rpm
Once complete you can install ansible by executing the following command:
$ sudo yum install ansible
Vagrant Install
Vagrant is a command line utility that can be used to manage the lifecycle of a virtual machine. This tool is used for the installation and management of the Red Hat Container Development Kit.
Vagrant is not included in any standard repository, so we will need to install it. You can install Vagrant by enabling the SCLO repository or you can get it directly from the Vagrant website. We will use the latter approach:
$ wget https://releases.hashicorp.com/vagrant/1.8.3/vagrant_1.8.3_x86_64.rpm
$ sudo yum install vagrant_1.8.3_x86_64.rpm
VirtualBox Install
The Red Hat Container Development Kit requires a virtualization software stack to execute. In this blog we will use VirtualBox for the virtualization software.
VirtualBox is best done using a repository to ensure you can get updates. To do this you will need to follow these steps:
- You will want to download the repo file::
$ wget http://download.virtualbox.org/virtualbox/rpm/el/virtualbox.repo
$ mv virtualbox.repo /etc/yum.repos.d - Install VirtualBox:
$ sudo yum install VirtualBox-5.0
Once the install is complete you will want to launch VirtualBox and ensure that the Guest Network is on the correct subnet as the CDK has a default for it setup. The blog will leverage this default as well. To verify that the host is on the correct domain:
- Open VirtualBox, this should be under you Applications->System Tools menu on your desktop
- Click on File->Preferences
- Click on Network
- Click on the Host-only Networks, and a popup of the VirtualBox preferences will load.
- There should be a vboxnet0 as the network, click on it and click on the edit icon (looks like a screwdriver on the left side of the popup)
- Ensure that the IPv4 Address is 10.1.2.1
- Ensure the IPv4 Network Mask is 255.255.255.0
- Click on the DHCP Server tab
- Ensure the server address is 10.1.2.100
- Ensure the Server mask is 255.255.255.0
- Ensure the Lower Address Bound is 10.1.2.101
- Ensure the Upper Address Bound is 10.1.2.254
- Click on OK
- Click on OK
CDK Install
Docker containers are used to package software applications into portable, isolated stores. Developing software with containers helps developers create applications that will run the same way on every platform. However modern microservice deployments typically use a scheduler such as Kubernetes to run in production. In order to fully simulate the production environment, developers require a local version of production tools. In the Red Hat stack, this is supplied by the Red Hat Container Development Kit (CDK).
The Red Hat CDK is a customized virtual machine that makes it easy to run complex deployments resembling production. This means complex applications can be developed using production grade tools from the very start, meaning developers are unlikely to experience problems stemming from differences in the development and production environments.
This blog post walks through installation and configuration of the Red Hat CDK. We will create a containerized multi-tier application on the CDK’s OpenShift instance and go through the entire workflow. By the end of this blog post you will know how to run an application on top of OpenShift and will be familiar with the core features of the CDK and OpenShift.
Let’s get started…
Installing the CDK
The prerequisites for running the CDK are Vagrant and a virtualization client (VirtualBox, VMware Fusion, libvirt). Make sure that both are up and running on your machine.
Start by going to Red Hat Product Downloads (note that you will need a Red Hat subscription to access this). Select ‘Red Hat Container Development Kit’ under Product Variant, and the appropriate version and architecture. You should download two packages:
- Red Hat Container Tools
- RHEL Vagrant Box (for your preferred virtualization client)
The Container Tools package is a set of plugins and templates that will help you start the Vagrant box. In the components subfolder you will find Vagrant files that will configure the virtual machine for you. The plugins folder contains the Vagrant add-ons that will be used to register the new virtual machine with the Red Hat subscription and to configure networking.
Unzip the container tools archive into the root of your user folder and install the Vagrant add-ons.
$ cd ~/cdk/plugins
$ vagrant plugin install vagrant-registration vagrant-adbinfo landrush vagrant-service-manager
You can check if the plugins were actually installed with this command:
$ vagrant plugin list
Add the box you downloaded into Vagrant. The path and the name may vary depending on your download folder and the box version:
$ vagrant box add --name cdkv2 \
~/Downloads/rhel-cdk-kubernetes-7.2-13.x86_64.vagrant-virtualbox.box
Check that the vagrant box was properly added with the box list command:
$ vagrant box list
We will use the Vagrantfile that comes shipped with the CDK and has support for OpenShift.
$ cd $HOME/cdk/components/rhel/rhel-ose/
$ ls README.rst Vagrantfile
In order to use the landrush plugin to configure the DNS we need to add the following two lines to the Vagrantfile exactly as below (i.e. PUBLIC_ADDRESS is a property in the Vagrantfile and does not need to be replaced) :
config.landrush.enabled = true
config.landrush.host_ip_address = "#{PUBLIC_ADDRESS}"
This will allow us to access our application from outside the virtual machine based on the hostname we configure. Without this plugin, your applications will be reachable only by IP address from within the VM.
Save the changes and start the virtual machine :
$ vagrant up
During initialization you will be prompted to register your Vagrant box with your RHEL subscription credentials.
Let’s review what just happened here. On your local machine you now have a working instance of OpenShift running inside a virtual machine. This instance can talk to the Red Hat Registry to download images for the most common application stacks. You also get a private Docker registry for storing images. Docker, Kubernetes, OpenShift and Atomic App CLIs are also installed.
Now that we have our Vagrant box up and running, it’s time to create and deploy a sample application to OpenShift, and create a continuous deployment workflow for it.
The OpenShift console should be accessible at https://10.1.2.2:8443 from a browser on your host (this IP is defined in the Vagrantfile). By default the login credentials will be openshift-dev/devel. You can also use your Red Hat credentials to login.
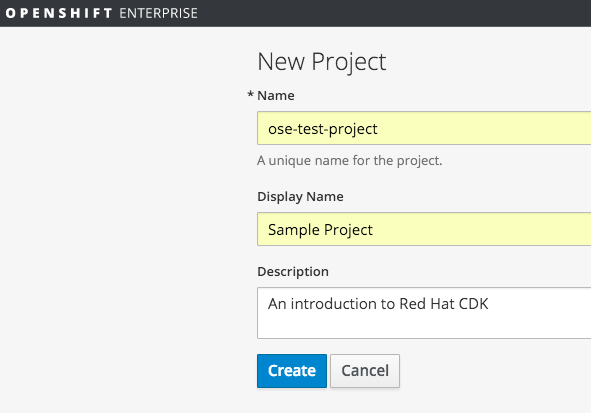
In the console, we create a new project:
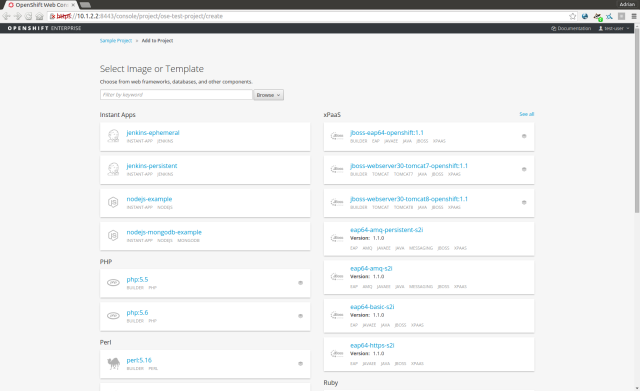
Next we create a new application using one of the built-in ‘Instant Apps’. Instant Apps are predefined application templates that pull specific images. These are an easy way to quickly get an app up and running. From the list of Instant Apps, select “nodejs-mongodb-example” which will start a database (mongodb) and a web server (Node.js).
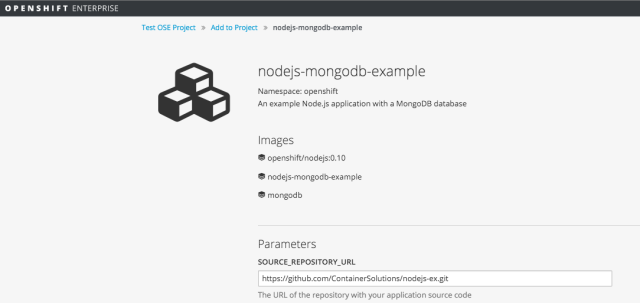
For this application we will use the source code from the OpenShift GitHub repository located here:https://github.com/openshift/nodejs-ex. If you want to follow along with the webhook steps later, you’ll need to fork this repository into your own. Once you’re ready, enter the URL of your repo into the SOURCE_REPOSITORY_URL field:
There are two other parameters that are important to us – GITHUB_WEBHOOK_SECRET and APPLICATION_DOMAIN:
- GITHUB_WEBHOOK_SECRET: this field allows us to create a secret to use with the GitHub webhook for automatic builds. You don’t need to specify this, but you’ll need to remember the value later if you do.
- APPLICATION_DOMAIN: this field will determine where we can access our application. This value must include the Top Level Domain for the VM, by default this value is rhel-ose.vagrant.dev. You can check this by running vagrant landrush ls.
Once these values are configured, we can ‘Create’ our application. This brings us to an information page which gives us some helpful CLI commands as well as our webhook URL. Copy this URL as we will use it later on.
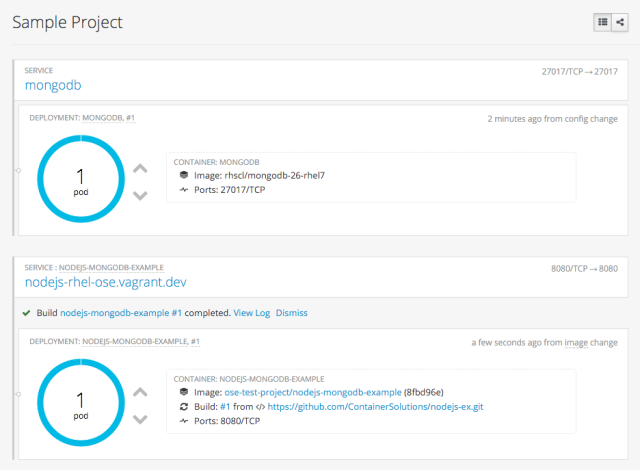
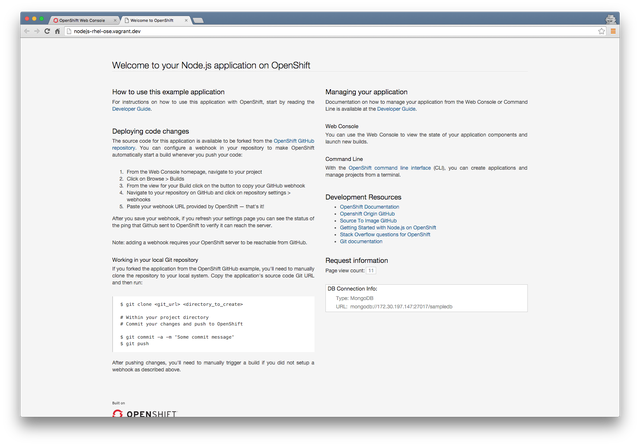
OpenShift will then pull the code from GitHub, find the appropriate Docker image in the Red Hat repository, and also create the build configuration, deployment configuration, and service definitions. It will then kick off an initial build. You can view this process and the various steps within the web console. Once completed it should look like this:
In order to use the Landrush plugin there is additional steps that are required to configure dnsmasq. To do that you will need to do the following:
- Ensure dnsmasq is installed
$sudo yum install dnsmasq
- Modify the vagrant configuration for dnsmasq:
$sudo sh -c 'echo "server=/vagrant.test/127.0.0.1#10053" > /etc/dnsmasq.d/vagrant-landrush'
- Edit /etc/dnsmasq.conf and verify the following lines are in this file:
conf-dir=/etc/dnsmasq.d
listen-address=127.0.0.1 - Restart the dnsmasq service
$ sudo systemctl restart dnsmasq
- Add nameserver 127.0.0.1 to /etc/resolv.conf
Great! Our application has now been built and deployed on our local OpenShift environment. To complete the Continuous Deployment pipeline we just need to add a webhook into our GitHub repository we specified above, which will automatically update the running application.
To set up the webhook in GitHub, we need a way of routing from the public internet to the Vagrant machine running on your host. An easy way to achieve this is to use a third party forwarding service such as ultrahook or ngrok. We need to set up a URL in the service that forwards traffic through a tunnel to the webhook URL we copied earlier.
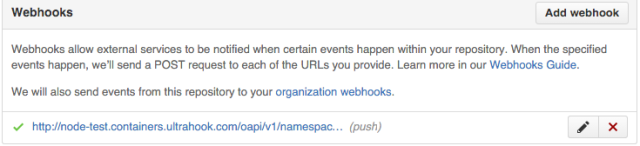
Once this is done, open the GitHub repo and go to Settings -> Webhooks & services -> Add webhook. Under Payload URL enter the URL that the forwarding service gave you, plus the secret (if you specified one when setting up the OpenShift project). If your webhook is configured correctly you should see something like this:
To test out the pipeline, we need to make a change to our project and push a commit to the repo.

Any easy way to do this is to edit the views/index.html file, e.g:
(Note that you can also do this through the GitHub web interface if you’re feeling lazy). Commit and push this change to the GitHub repo, and we can see a new build is triggered automatically within the web console. Once the build completes, if we again open our application we should see the updated front page.

We now have Continuous Deployment configured for our application.
Throughout this blog-post we’ve used the OpenShift web interface. However, we could have performed the same actions using the OpenShift console (oc) at the command-line. The easiest way to experiment with this interface is to ssh into the CDK VM via the Vagrant ssh command.
Before wrapping up, it’s helpful to understand some of the concepts used in Kubernetes, which is the underlying orchestration layer in OpenShift.
Pods
A pod is one or more containers that will be deployed to a node together. A pod represents the smallest unit that can be deployed and managed in OpenShift. The pod will be assigned its own IP address. All of the containers in the pod will share local storage and networking.
A pod lifecycle is defined, deploy to node, run their container(s), exit or removed. Once a pod is executing then it cannot be changed. If a change is required then the existing pod is terminated and recreated with the modified configuration.
For our example application we have a Pod running the application. Pods can be scaled up/down from the OpenShift interface.
Replication controllers manage the lifecycle of Pods.They ensure that the correct number of Pods are always running by monitoring the application and stopping or creating Pods as appropriate.
Services
Pods are grouped into services. Our architecture now has four services: three for the database (MongoDB) and one for the application server JBoss.
Deployments
With every new code commit (assuming you set-up the GitHub webhooks) OpenShift will update your application. New pods will be started with the help of replication controllers running your new application version. The old pods will be deleted. OpenShift deployments can perform rollbacks and provide various deploy strategies.
Conclusion
It’s hard to overstate the advantages of being able to run a production environment in development and the efficiencies gained from the fast feedback cycle of a Continuous Deployment pipeline.
In this post we have shown how to use the Red Hat CDK to achieve both of these goals within a short-time frame. By the end of the post, we had a Node.js and MongoDB application running in containers, deployed using the OpenShift PaaS. This is a great way to quickly get up and running with containers and microservices and to experiment with OpenShift and other elements of the Red Hat container ecosystem.
MongoDB VirtualBox
In this section we will create the virtual machines that will be required to setup the replica set. We will not walk through all of the steps of setting up Red Hat as this is prerequisite knowledge.
What we will be doing is creating a base RHEL 7.2 minimal install and then using the VirtualBox interface to clone the images. We will do this so that we can easily install the replica set using the MongoDB Automation Agent.
We will also be installing a no password generated ssh keys for the Ansible Playbook install of the automation engine.
Please perform the following steps:
- In VirtualBox create a new guest image and call it RHEL Base. We used the following information:
- Memory 2048 MB
- Storage 30GB
- 2 Network cards
- Nat
- Host-Only
- Do a minimal Red Hat install, we modified the disk layout to remove the /home directory and added the reclaimed space to the / partition
Once this is done you should attach a subscription and do a yum update on the guest RHEL install.
The final step will be to generate new ssh keys for the root user and transfer the keys to the guest machine. To do that please do the following steps:
- Become the root user
$ sudo -i
- Generate your ssh keys. Do not add a passphrase when requested.
# ssh-keygen
- You need to add the contents of the id_rsa.pub to the authorized_keys file on the RHEL guest. The following steps were used on a local system and are not best practices for this process. In a managed server environment your IT should have a best practice for doing this. If this is the first guest in your VirtualBox then it should have an ip of 10.1.2.101, if it has another ip then you will need to replace for the following. For this blog please execute the following steps
# cd ~/.ssh/
# scp id_rsa.pub 10.1.2.101:
# ssh 10.1.2.101
# mkdir .ssh
# cat id_rsa.pub > ~/.ssh/authorized_keys
# chmod 700 /root/.ssh
# chmod 600 /root/.ssh/authorized_keys - SELinux may block sshd from using the authorized_keys so update the permissions on the guest with the following command
# restorecon -R -v /root/.ssh
- Test the connection by trying to ssh from the host to the guest, you should not be asked for any login information.
Once this is complete you can shut down the RHEL Base guest image. We will now clone this to provide the MongoDB environment. The steps are as follows:
- Right click on the RHEL guest OS and select Clone
- Enter the Name 7.2 RH Mongo-DB1
- Ensure to click the Reinitialize the MAC Address of all network cards
- Click on Next
- Ensure the Full Clone option is selected
- Click on Clone
- Right click on the RHEL guest OS and select Clone
- Enter the Name 7.2 RH Mongo-DB2
- Ensure to click the Reinitialize the MAC Address of all network cards
- Click on Next
- Ensure the Full Clone option is selected
- Click on Clone
- Right click on the RHEL guest OS and select Clone
- Enter the Name 7.2 RH Mongo-DB3
- Ensure to click the Reinitialize the MAC Address of all network cards
- Click on Next
- Ensure the Full Clone option is selected
- Click on Clone
The final step for getting the systems ready will be to configure the hostnames, host-only ip and the hosts files. We will need to also ensure that the systems can communicate on the port for MongoDB, so we will disable the firewalld which is not meant for production purposes but you will need to contact your IT departments on how they manage opening of ports.
Normally in a production environment you would have the servers in an internal DNS system, however for the sake of this blog we will use hosts files for the purpose of names. We want to edit the /etc/hosts file on the three MongoDB guests as well as the hosts.
The information we will be using will be as follows:
| VirtualBox Guest Name | hostname | IPv4 address |
| 7.2 RH Mongo-DB1 | mongo-db1 | 10.1.2.10 |
| 7.2 RH Mongo-DB2 | mongo-db2 | 10.1.2.11 |
| 7.2 RH Mongo-DB3 | mongo-db3 | 10.1.2.12 |
To do so on each of the guests do the following:
- Login
- Find your host only network interface by looking for the interface on the host only network 10.1.2.0/24
# sudo ip addr
- Edit the network interface, in our case the interface was enp0s8
# sudo vi /etc/sysconfig/network-scripts/ifcfg-enp0s8
- You will want to change the ONBOOT and BOOTPROTO to the following and add the three lines for ip address, netmask and Broadcast. Note: the ip address should be based upon the table above.They should match the info below
ONBOOT=yes
BOOTPROTO=static
IPADDR=10.1.2.10
NETMASK-255.255.255.0
BROADCAST=10.1.2.255 - Disable the firewall by:
# systemctl stop firewalld
# systemctl disable firewalld - Edit the hostname using the appropriate values from the table above.
# hostnamectl set-hostname "mongo-db1" --static
- Edit the hosts file adding the following to etc/hosts, you should also do this on the guest
10.1.2.10 mongo-db1
10.1.2.11 mongo-db2
10.1.2.12 mongo-db3 - Restart the guest
- Try to ssh by hostname
- Also try pinging each guest by hostname from guests and host
Ops Manager
MongoDB Ops Manager can be leveraged throughout the development, test, and production lifecycle, with critical functionality ranging from cluster performance monitoring data, alerting, no-downtime upgrades, advanced configuration and scaling, as well as backup and restore. Ops Manager can be used to manage up to thousands of distinct MongoDB clusters in a tenants-per-cluster fashion — isolating cluster users to specific clusters.
All major MongoDB Ops Manager actions can be driven manually through the user interface or programmatically through the REST API, where Ops Manager can be deployed by platform teams offering Enterprise MongoDB as a Service back-ends to application teams.
Specifically, Ops Manager can deploy any MongoDB cluster topology across bare metal or virtualized hosts, or in private or public cloud environments. A production MongoDB cluster will typically be deployed across a minimum of three hosts in three distinct availability areas — physical servers, racks, or data centers. The loss of one host will still preserve a quorum in the remaining two to ensure always-on availability.
Ops Manager can deploy a MongoDB cluster (replica set or sharded cluster) across the hosts with Ops Manager agents running, using any desired MongoDB version and enabling access control (authentication and authorization) so that only client connections presenting the correct credentials are able to access the cluster. The MongoDB cluster can also use SSL/TLS for over the wire encryption.
Once a MongoDB cluster is successfully deployed by Ops Manager, the cluster’s connection string can be easily generated (in the case of a MongoDB replica set, this will be the three hostname:port pairs separated by commas). An OpenShift application can then be configured to use the connection string and authentication credentials to this MongoDB cluster.
To use Ops Manager with Ansible and OpenShift
- Install and use a MongoDB Ops Manager, and record the URL that it is accessible at (“OpsManagerCentralURL”)
- Ensure that the MongoDB Ops Manager is accessible over the network at the OpsManagerCentralURL from the servers (VMs) where we will deploy MongoDB. (Note that the reverse is not necessary; in other words Ops Manager does not need to be able to reach into the managed VMs directly over the network).
- Spawn servers (VMs) running Red Hat Enterprise Linux, able to reach each other over the network at the hostnames returned by “hostname -f” on each server respectively, and the MongoDB Ops Manager itself, at the OpsManagerCentralURL.
- Create an Ops Manager Group, and record the group’s unique identifier (“mmsGroupId”) and Agent API key (“mmsApiKey”) from the group’s ‘Settings’ page in the user interface.
- Use Ansible to configure the VMs to start the MongoDB Ops Manager Automation Agent (available for download directly from the Ops Manager). Use the Ops Manager UI (or REST API) to instruct the Ops Manager agents to deploy a MongoDB replica set across the three VMs.
Ansible Install
By having three MongoDB instances that we want to install the automation agent it would be easy enough to login and run the commands as seen in the Ops Manager agent installation information. However we have created an ansible playbook that you will need to change to customize.
The playbook looks like:
- hosts: mongoDBNodes
vars:
OpsManagerCentralURL:
mmsGroupId:
mmsApiKey:
remote_user: root
tasks:
- name: install automation agent RPM from OPS manager instance @ {{ OpsManagerCentralURL }}
yum: name={{ OpsManagerCentralURL }}/download/agent/automation/mongodb-mms-automation-agent-manager-latest.x86_64.rhel7.rpm state=present
- name: write the MMS Group ID as {{ mmsGroupId }}
lineinfile: dest=/etc/mongodb-mms/automation-agent.config regexp=^mmsGroupId= line=mmsGroupId={{ mmsGroupId }}
- name: write the MMS API Key as {{ mmsApiKey }}
lineinfile: dest=/etc/mongodb-mms/automation-agent.config regexp=^mmsApiKey= line=mmsApiKey={{ mmsApiKey }}
- name: write the MMS BASE URL as {{ OpsManagerCentralURL }}
lineinfile: dest=/etc/mongodb-mms/automation-agent.config regexp=^mmsBaseUrl= line=mmsBaseUrl={{ OpsManagerCentralURL }}
- name: create MongoDB data directory
file: path=/data state=directory owner=mongod group=mongod
- name: ensure MongoDB MMS Automation Agent is started
service: name=mongodb-mms-automation-agent state=started
You will need to customize it with the information you gathered from the Ops Manager.
You will need to create this file as your root user and then update the /etc/ansible/hosts file and add the following lines:
[mongoDBNodes]
mongo-db1
mongo-db2
mongo-db3
Once this is done you are ready to run the ansible playbook. This playbook will contact your Ops Manager Server, download the latest client, update the client config files with your APiKey and Groupid, install the client and then start the client. To run the playbook you need to execute the command as root:
ansible-playbook –v mongodb-agent-playbook.yml
Use MongoDB Ops Manager to create a MongoDB Replica Set and add database users with appropriate access rights
- Verify that all of the Ops Manager agents have started in the MongoDB Ops Manager group’s Deployment interface
- Navigate to "Add” > ”New Replica Set" and define a Replica Set with desired configuration (MongoDB 3.2, default settings).
- Navigate to "Authentication & SSL Settings" in the "..." menu and enable MongoDB Username/Password (SCRAM-SHA-1) Authentication
- Navigate to the "Authentication & Users" panel and add a database user to the sampledb
- Add the testUser@sampledb user, with password set to "password", and with Roles: readWrite@sampledb dbOwner@sampledb dbAdmin@sampledb userAdmin@sampledb Roles.
- Click Review & Deploy.
OpenShift Continuous Deployment
In our previous posts, we’ve explored the Red Hat container ecosystem, the Red Hat Container Development Kit (CDK),OpenShift as a local deployment and OpenShift in production. In this final post of the series, we’re going to take a look at how a team can take advantage of the advanced features of OpenShift in order to automatically move new versions of applications from development to production — a process known as Continuous Delivery (or Continuous Deployment, depending on the level of automation).
OpenShift supports different setups depending on organizational requirements. Some organizations may run a completely separate cluster for each environment (e.g. dev, staging, production) and others may use a single cluster for several environments. If you run a separate OpenShift PaaS for each environment, they will each have their own dedicated and isolated resources, which is costly but ensures isolation (a problem with the development cluster cannot affect production).
However, multiple environments can safely run on one OpenShift cluster through the platform’s support for resource isolation, which allows nodes to be dedicated to specific environments. This means you will have one OpenShift cluster with common masters for all environments, but dedicated nodes assigned to specific environments. This allows for scenarios such as only allowing production projects to run on the more powerful / expensive nodes.
OpenShift integrates well with existing Continuous Integration / Continuous Delivery tools. Jenkins, for example, is available for use inside the platform and can be easily added to any projects you’re planning to deploy. For this demo however, we will stick to out-of-the-box OpenShift features, to show workflows can be constructed out of the OpenShift fundamentals.
A Continuous Delivery Pipeline with CDK and OpenShift Enterprise
The workflow of our continuous delivery pipeline is illustrated below:
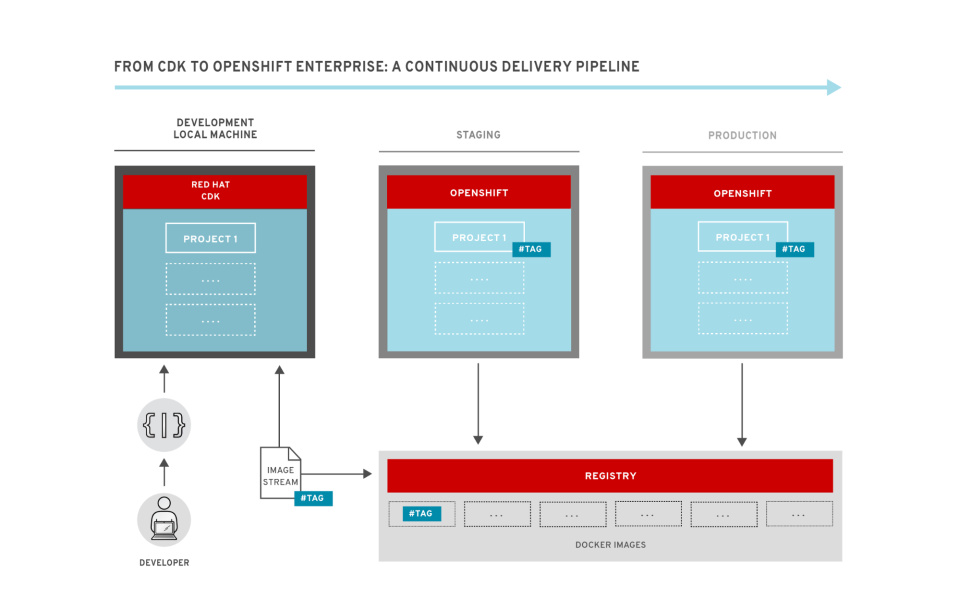
The diagram shows the developer on the left, who is working on the project in their own environment. In this case, the developer is using Red Hat’s CDK running on their local-machine, but they could equally be using a development environment provisioned in a remote OpenShift cluster.
To move code between environments, we can take advantage of the image streams concept in OpenShift. An image stream is superficially similar to an image repository such as those found on Docker Hub – it is a collection of related images with identifying names or “tags”. An image stream can refer to images in Docker repositories (both local and remote) or other image streams.
However, the killer feature is that OpenShift will generate notifications whenever an image stream changes, which we can easily configure projects to listen and react to. We can see this in the diagram above – when the developer is ready for their changes to be picked up by the next environment in line, they simply tag the image appropriately, which will generate an image stream notification that will be picked up by the staging environment. The staging environment will then automatically rebuild and redeploy any containers using this image (or images who have the changed image as a base layer). This can be fully automated by the use of Jenkins or a similar CI tool; on a check-in to the source control repository it can run a test-suite and automatically tag the image if it passes.
To move between staging and production we can do exactly the same thing – Jenkins or a similar tool could run a more thorough set of system tests and if they pass tag the image so the production environment picks up the changes and deploys the new versions. This would be true Continuous Deployment — where a change made in dev will propagate automatically to production without any manual intervention. Many organizations may instead opt for Continuous Delivery — where there is still a manual “ok” required before changes hit production. In OpenShift this can be easily done by requiring the images in staging to be tagged manually before they are deployed to production.
Deployment of an OpenShift Application
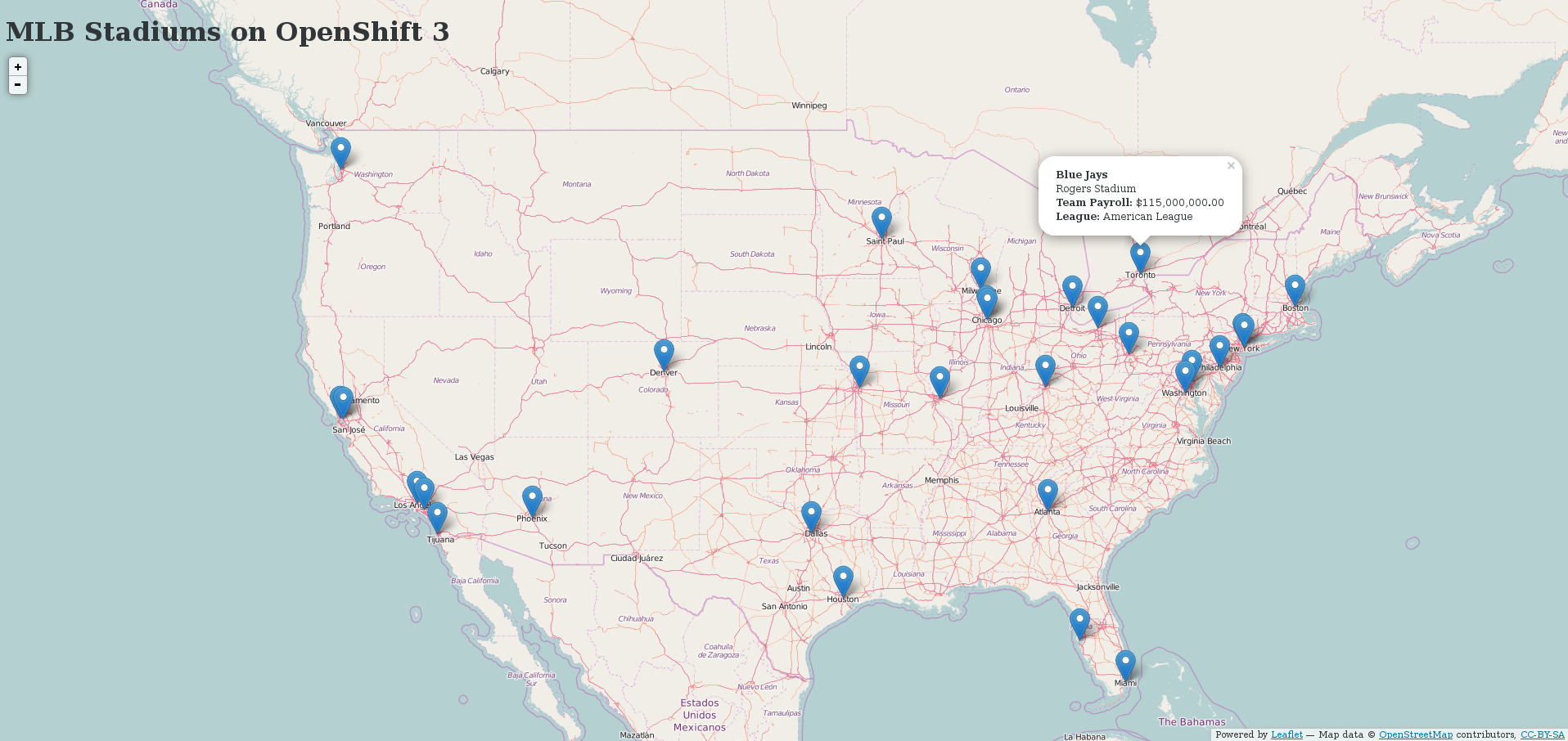
Now that we’ve reviewed the workflow, let’s look at a real example of pushing an application from development to production. We will use the simple MLB Parks application from a previous blogpost that connects to MongoDB for storage of persistent data. The application displays various information about MLB parks such as league and city on a map. The source code is available in this GitHub repository . The example assumes that both environments are hosted on the same OpenShift cluster, but it can be easily adapted to allow promotion to another OpenShift instance by using a common registry.
If you don’t already have a working OpenShift instance, you can quickly get started by using the CDK, which we also covered in an earlier blogpost. Start by logging in to OpenShift using your credentials:
$ oc login -u openshift-dev
Now we’ll create two new projects. The first one represents the production environment (mlbparks-production):
$ oc new-project mlbparks-production
Now using project "mlbparks-production" on server "https://localhost:8443".
And the second one will be our development environment (mlbparks):
$ oc new-project mlbparks
Now using project "mlbparks" on server "https://localhost:8443".
After you run this command you should be in the context of the development project (mlbparks). We’ll start by creating an external service to the MongoDB database replica-set.
Openshift allows us to access external services, allowing our projects to access services that are outside the control of OpenShift. This is done by defining a service with an empty selector and an endpoint. In some cases you can have multiple IP addresses assigned to your endpoint and the service will act a as a load balancer. This will not work with the MongoDB replica set as you will encounter issues not being able to connect to the PRIMARY node for writing purposes. To allow for this in this case you will need to create one external service for each node. In our case we have three nodes so for illustrative purposes we have three service files and three endpoint files.
Service Files:
replica-1_service.json
{
"kind": "Service",
"apiVersion": "v1",
"metadata": {
"name": "replica-1"
},
"spec": {
"selector": {
},
"ports": [
{
"protocol": "TCP",
"port": 27017,
"targetPort": 27017
}
]
}
}
replica-1_endpoints.json
{
"kind": "Endpoints",
"apiVersion": "v1",
"metadata": {
"name": "replica-1"
},
"subsets": [
{
"addresses": [
{ "ip": "10.1.2.10" }
],
"ports": [
{ "port": 27017 }
]
}
]
}
replica-2_service.json
{
"kind": "Service",
"apiVersion": "v1",
"metadata": {
"name": "replica-2"
},
"spec": {
"selector": {
},
"ports": [
{
"protocol": "TCP",
"port": 27017,
"targetPort": 27017
}
]
}
}
replica-2_endpoints.json
{
"kind": "Endpoints",
"apiVersion": "v1",
"metadata": {
"name": "replica-2"
},
"subsets": [
{
"addresses": [
{ "ip": "10.1.2.11" }
],
"ports": [
{ "port": 27017 }
]
}
]
}
replica-3_service.json
{
"kind": "Service",
"apiVersion": "v1",
"metadata": {
"name": "replica-3"
},
"spec": {
"selector": {
},
"ports": [
{
"protocol": "TCP",
"port": 27017,
"targetPort": 27017
}
]
}
}
replica-3_endpoints.json
{
"kind": "Endpoints",
"apiVersion": "v1",
"metadata": {
"name": "replica-3"
},
"subsets": [
{
"addresses": [
{ "ip": "10.1.2.12" }
],
"ports": [
{ "port": 27017 }
]
}
]
}
Using the above replica files you will need to run the following commands:
$ oc create -f replica-1_service.json
$ oc create -f replica-1_endpoints.json
$ oc create -f replica-2_service.json
$ oc create -f replica-2_endpoints.json
$ oc create -f replica-3_service.json
$ oc create -f replica-3_endpoints.json
Now that we have the endpoints for the external replica set created we can now create the MLB parks using a template. We will use the source code from our demo github repo and the s2i build strategy which will create a container for our source code (note this repository has no Dockerfile in the branch we use). All of the environment variables are in the mlbparks-template.json, so we will first create a template then create our new app. :
$ oc create -f https://raw.githubusercontent.com/macurwen/openshift3mlbparks/master/mlbparks-template.json
$ oc new-app mlbparks
--> Success
Build scheduled for "mlbparks" - use the logs command to track its progress.
Run 'oc status' to view your app.
As well as building the application, note that it has created an image stream called mlbparks for us.
Once the build has finished, you should have the application up and running (accessible at the hostname found in the pod of the web ui) built from an image stream.
We can get the name of the image created by the build with the help of the describe command:
$ oc describe imagestream mlbparks
Name: mlbparks
Created: 10 minutes ago
Labels: app=mlbparks
Annotations: openshift.io/generated-by=OpenShiftNewApp
openshift.io/image.dockerRepositoryCheck=2016-03-03T16:43:16Z
Docker Pull Spec: 172.30.76.179:5000/mlbparks/mlbparks
Tag Spec Created PullSpec Image
latest7 minutes ago 172.30.76.179:5000/mlbparks/mlbparks@sha256:5f50e1ffbc5f4ff1c25b083e1698c156ca0da3ba207c619781efcfa5097995ec
So OpenShift has built the image mlbparks@sha256:5f50e1ffbc5f4ff1c25b083e1698c156ca0da3ba207c619781efcfa5097995ec, added it to the local repository at 172.30.76.179:5000 and tagged it as latest in the mlbparks image stream.
Now we know the image ID, we can create a tag that marks it as ready for use in production (use the SHA of your image here, but remove the IP address of the registry):
$ oc tag mlbparks/mlbparks\
@sha256:5f50e1ffbc5f4ff1c25b083e1698c156ca0da3ba207c619781efcfa5097995ec \
mlbparks/mlbparks:production
Tag mlbparks:production set to mlbparks/mlbparks@sha256:5f50e1ffbc5f4ff1c25b083e1698c156ca0da3ba207c619781efcfa5097995ec.
We’ve intentionally used the unique SHA hash of the image rather than the tag latest to identify our image. This is because we want the production tag to be tied to this particular version. If we hadn’t done this, production would automatically track changes to latest, which would include untested code.
To allow the production project to pull the image from the development repository, we need to grant pull rights to the service account associated with production environment. Note that mlbparks-production is the name of the production project:
$ oc policy add-role-to-group system:image-puller \
system:serviceaccounts:mlbparks-production \
--namespace=mlbparks
To verify that the new policy is in place, we can check the rolebindings:
$ oc get rolebindings
NAME ROLE USERS GROUPS SERVICE ACCOUNTS SUBJECTS
admins /admin catalin
system:deployers /system:deployer deployer
system:image-builders /system:image-builder builder
system:image-pullers /system:image-puller system:serviceaccounts:mlbparks, system:serviceaccounts:mlbparks-production
OK, so now we have an image that can be deployed to the production environment. Let’s switch the current project to the production one:
$ oc project mlbparks-production
Now using project "mlbparks" on server "https://localhost:8443".
To start the database we’ll use the same steps to access the external MongoDB as previous:
$ oc create -f replica-1_service.json
$ oc create -f replica-1_endpoints.json
$ oc create -f replica-2_service.json
$ oc create -f replica-2_endpoints.json
$ oc create -f replica-3_service.json
$ oc create -f replica-3_endpoints.json
For the application part we’ll be using the image stream created in the development project that was tagged “production”:
$ oc new-app mlbparks/mlbparks:production
--> Found image 5621fed (11 minutes old) in image stream "mlbparks in project mlbparks" under tag :production for "mlbparks/mlbparks:production"
* This image will be deployed in deployment config "mlbparks"
* Port 8080/tcp will be load balanced by service "mlbparks"
--> Creating resources with label app=mlbparks ...
DeploymentConfig "mlbparks" created
Service "mlbparks" created
--> Success
Run 'oc status' to view your app.
This will create an application from the same image generated in the previous environment.
You should now find the production app is running at the provided hostname.
We will now demonstrate the ability to both automatically move new items to production, but we will also show how we can update an application without having to update the MongoDB schema. We have created a branch of the code in which we will now add the division to the league for the ballparks, without updating the schema.
Start by going back to the development project:
$ oc project mlbparks
Now using project "mlbparks" on server "https://10.1.2.2:8443".
And start a new build based on the commit “8a58785”:
$ oc start-build mlbparks --git-repository=https://github.com/macurwen/openshift3mlbparks/tree/division --commit='8a58785'
Traditionally with a RDBMS if we want to add a new element to in our application to be persisted to the database, we would need to make the changes in the code as well as have a DBA manually update the schema at the database. The following code is an example of how we can modify the application code without manually making changes to the MongoDB schema.
BasicDBObject updateQuery = new BasicDBObject();
updateQuery.append("$set", new BasicDBObject()
.append("division", "East"));
BasicDBObject searchQuery = new BasicDBObject();
searchQuery.append("league", "American League");
parkListCollection.updateMulti(searchQuery, updateQuery);
Once the build finishes running, a deployment task will start that will replace the running container. Once the new version is deployed, you should be able to see East under Toronto for example.
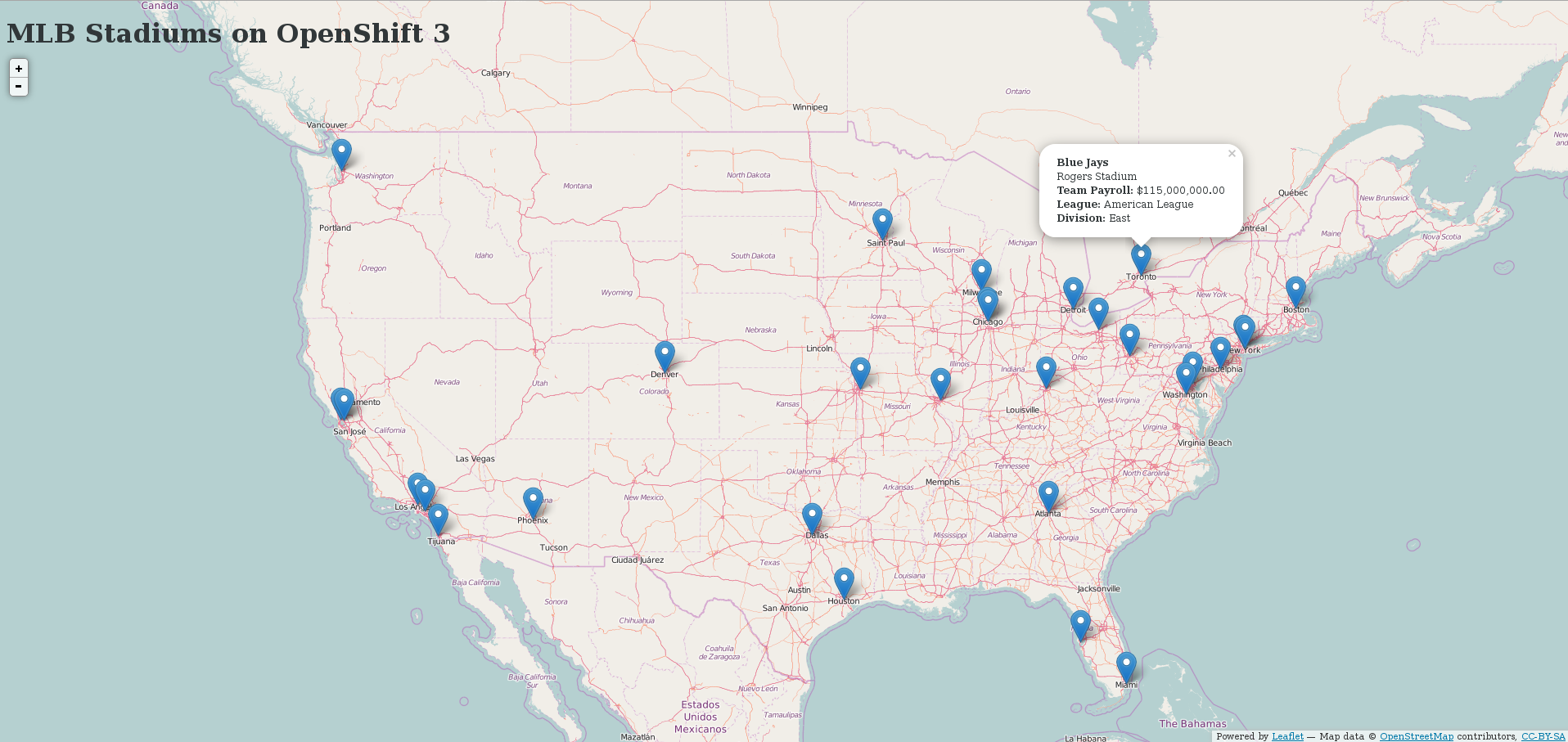
If you check the production version, you should find it is still running the previous version of the code.
OK, we’re happy with the change, let’s tag it ready for production. Again, run oc to get the ID of the image tagged latest, which we can then tag as production:
$ oc tag mlbparks/mlbparks@\
sha256:ceed25d3fb099169ae404a52f50004074954d970384fef80f46f51dadc59c95d \
mlbparks/mlbparks:production
Tag mlbparks:production set to mlbparks/mlbparks@sha256:ceed25d3fb099169ae404a52f50004074954d970384fef80f46f51dadc59c95d.
This tag will trigger an automatic deployment of the new image to the production environment.
Rolling back can be done in different ways. For this example, we will roll back the production environment by tagging production with the old image ID. Find the right id by running the oc command again, and then tag it:
$ oc tag mlbparks/mlbparks@\
sha256:5f50e1ffbc5f4ff1c25b083e1698c156ca0da3ba207c619781efcfa5097995ec \
mlbparks/mlbparks:production
Tag mlbparks:production set to mlbparks/mlbparks@sha256:5f50e1ffbc5f4ff1c25b083e1698c156ca0da3ba207c619781efcfa5097995ec.
Conclusions
Over the course of this series of posts, we’ve investigated the Red Hat container ecosystem and OpenShift Container Platform in particular. OpenShift builds on the advanced orchestration capabilities of Kubernetes and the reliability and stability of the Red Hat Enterprise Linux operating system to provide a powerful application environment for the enterprise. OpenShift adds several ideas of its own that provide important features for organizations, including source-to-image tooling, image streams, project and user isolation and a web UI. This post showed how these features work together to provide a complete CD workflow where code can be automatically pushed from development through to production combined with the power and capabilities of MongoDB as the backend of choice for applications.
À propos de l'auteur

Plus de résultats similaires
Red Hat to acquire Chatterbox Labs: Frequently Asked Questions
Key considerations for 2026 planning: Insights from IDC
Edge computing covered and diced | Technically Speaking
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud