First time reader?
If this is the first time you’re reading my blog series on Control Groups (cgroups) then allow me to offer you the links to the prior entries in the series. You’ll want to peruse them first before diving into today’s topic...unless you’re familiar with cgroups already. In that case, go ahead and jump to the next section.
“World Domination With Cgroups” series:
- Part 1 - https://www.redhat.com/en/blog/world-domination-cgroups-part-1-cgroup-basics
- Part 2 - https://www.redhat.com/en/blog/world-domination-cgroups-part-2-turning-knobs
- Part 3 - https://www.redhat.com/en/blog/world-domination-cgroups-part-3-thanks-memories
- Part 4 - https://www.redhat.com/en/blog/world-domination-cgroups-part-4-all-ios
- Part 5 - https://www.redhat.com/en/blog/world-domination-cgroups-part-5-hand-rolling-your-own-cgroup
A quick note about some of the examples from those articles. In Red Hat Enterprise Linux 7.4, changes were made regarding handling of transient slices (such as user sessions). You can no longer change cgroup settings “on the fly”, permanent configuration changes are no longer possible and the drop-in files will no longer be created using systemctl set-property. Yes, I find this annoying, but it’s reflecting changes upstream so it’s important that we go along. Services are not impacted, so applications that are being started and stopped via unit files (daemons) still honor these settings. Also, you can still use the legacy tools (cgcreate, cgset) to create custom cgroups and place user sessions and processes into them to use things like CPU quotas and the like. Change is always happening but we adapt and come up with new techniques, right? Anyway, on to the main event...
Sometimes, sharing is not caring
Ok nerds, it’s time to dig into some features around cgroups that are almost like coloring outside of the lines. As I’ve talked to various Red Hat customers at events and online, I’ve heard some great questions and we’ve talked about a whole bunch of different use cases for Red Hat technology. On more than one occasion, I was asked about cgroups and this use case:
“We have an application that’s very timing sensitive and need to reduce ‘jitter’. Is it possible to use cgroups to isolate this application to a set of cores on a system?”Since I wouldn’t be writing this blog if the answer to that question was a giant “NO!”, let’s take a look at this scenario.
We’re told when we’re kids that “sharing is caring”. And in truth, that still can be the case about many things. Except my coffee. You can’t have any of my coffee. That just ain’t happening…
Anyway, as we’ve mentioned in the past, Red Hat Enterprise Linux 7 is very much like your grandmother. When we ship it and it’s installed out of the box, the configuration is very much set up for all resources on the system to be shared equally. Normally, that’s not a bad thing. BUT, the reality is that sometimes Grandma doesn’t really love little Billy like she loves little Marc. Face it, Billy’s a bit of a pain in the tail. From a computing standpoint, often we have applications or services that are much more critical than other things on a system and they need all the help that they can get to be as responsive as possible.
This is going to involve a two-step process on Red Hat Enterprise Linux 7:
-
Isolate the CPUs that we want to dedicate for our application
-
Create the cgroups and unit files to make our application land on these CPUs
All by myself - isolcpus
One of the most important jobs that the kernel performs on a Linux system is the scheduling of processes. To explain a bit deeper - a process is running code that’s part of an application or service. These processes in the end consist of a series of instructions that the computer follows to get actual work done. (Or to look at pictures of cats on the Internet. The computer itself isn’t particularly fussy about what it’s being asked to do.)
The piece of hardware executing these instructions is, of course, the Central Processing Unit (CPU for short). On modern systems, the CPU usually consists of multiple processors all working together...in this case an individual processor is referred to as a “core”. So when I say that I’m running a four core system, that means I’ve got a system with four “workers”, ready to do my will.
The scheduler by default will consider every single core a viable target for new processes that are being spawned and will assign a process to a particular core when the process is spawned. The scheduler will also attempt to balance these assignments based on load but until we invent time travel, the scheduler doesn’t have any concept of “over time, little Timmy will be spawning a bunch of processes that should be grouped together and kept isolated from other processes.”
So we need a way to tell the scheduler to not use particular cores for general purpose work. Instead, we (or some other logical process) will put specific workloads on these cores when appropriate. This can be done using the isolcpus parameter within the kernel boot line in your grub configuration file. On my four CPU test machine, here are the two grub files from /etc/default: grub.noiso (the default, which I saved as a backup) and grub (which has the change needed to isolate cores 1-3 from the scheduler. /etc/default/grub is the configuration file that grub2-mkconfig will use)
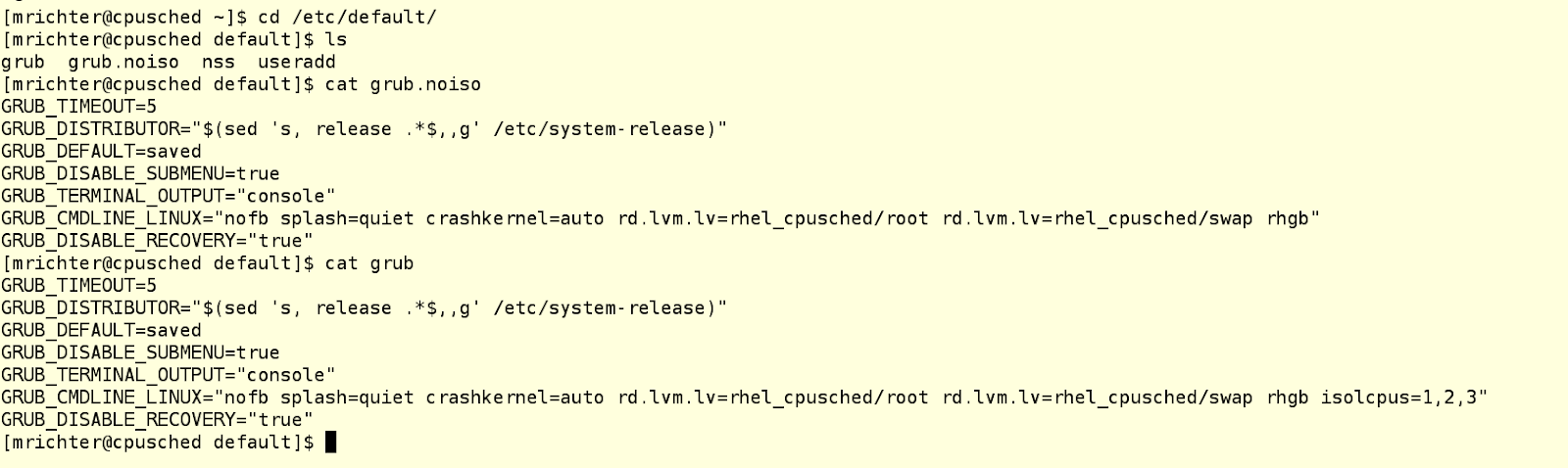
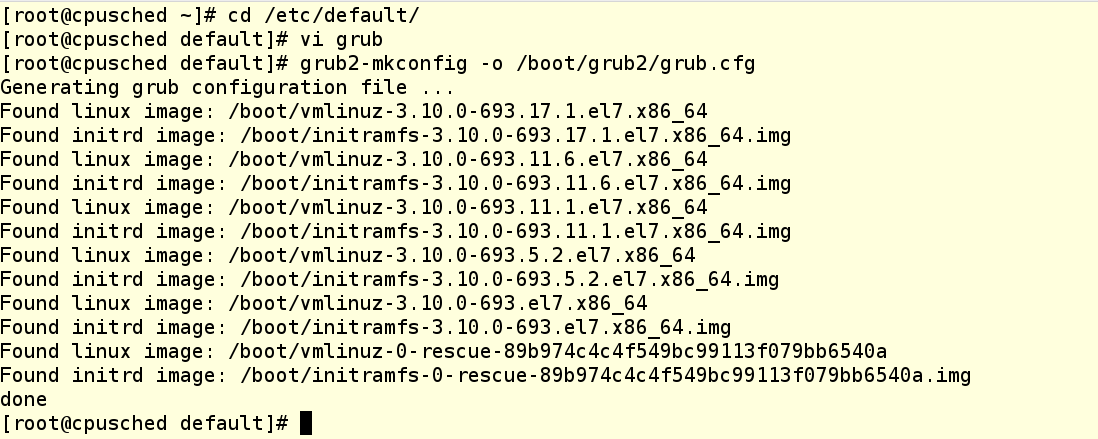
In Red Hat Enterprise Linux 7, you should never manually modify the grub.conf file that lives in /boot. Always make changes to /etc/default/grub and then rebuild the grub.conf file using the proper utility, like so:
The isolcpus parameter accepts a comma separated list of CPU cores, starting at 0. Once the system is rebooted, the kernel scheduler won’t use those cores for anything except certain system level processes that NEED to be available on the core. We can test this by spawning a few high CPU processes and then checking in top to see what the load is for each core.
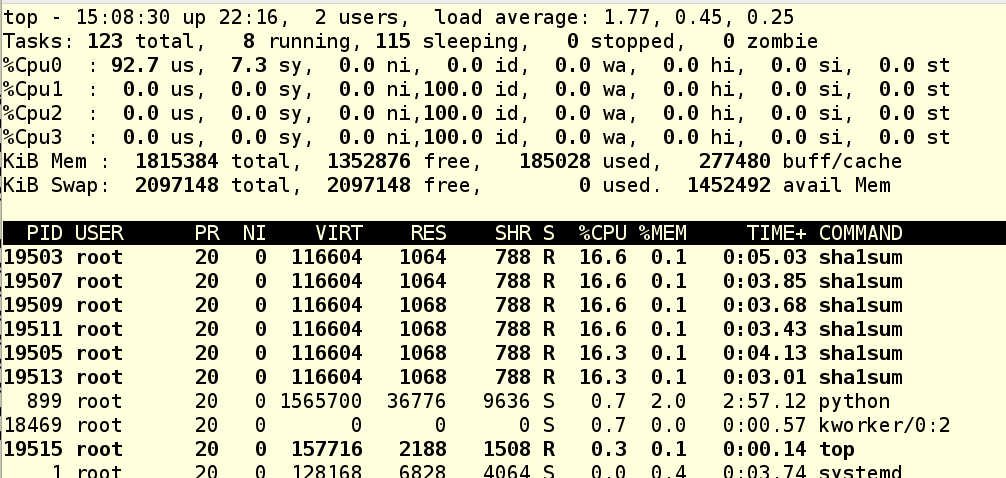
Here I’ve fired up some fake work and rather than spreading across to the other processors, the kernel is plopping all of them on CPU 0. This is a good sign, as it shows we set the boot parameter correctly.
Where we work - creating cpusets
We are now crossing over into “things you shouldn’t do without understanding why you are doing them.” Also, “things you shouldn’t deploy into production without full testing.”
The reason I bring this up is because to do this easily, we’re going to need to revisit our old friend, libcgroup-tools. As you may recall from prior blogs, this is the set of commands used to create, modify and destroy cgroups, going back to Red Hat Enterprise Linux 6. They are available to be installed on Red Hat Enterprise Linux 7 but may end up deprecated in the future. The usual guidelines around these tools:
-
Use systemd to manage cgroup controllers that are under its control (cpu, memory, and blockio).
-
Use libcgroup tools to manage all other cgroup controllers.
-
Be careful about unintended consequences.
Conceptually, a cpuset is fairly simple. It’s a list of cores on the system (starting at the number zero) that accepts tasks that will then ONLY run on those processor cores. These cores can be under the control of the regular kernel scheduler (default system behavior) or can be cores that have been isolated away from the scheduler. (...as we’ve done already on our test system.)
Let’s check out the /sys/fs/cgroup filesystem on our test box. We can see that the cpuset directory already exists, because the controller is part of the kernel (even though it’s not being managed by systemd) but there are no cgroups created under it yet, so we just see the default settings under the directory.
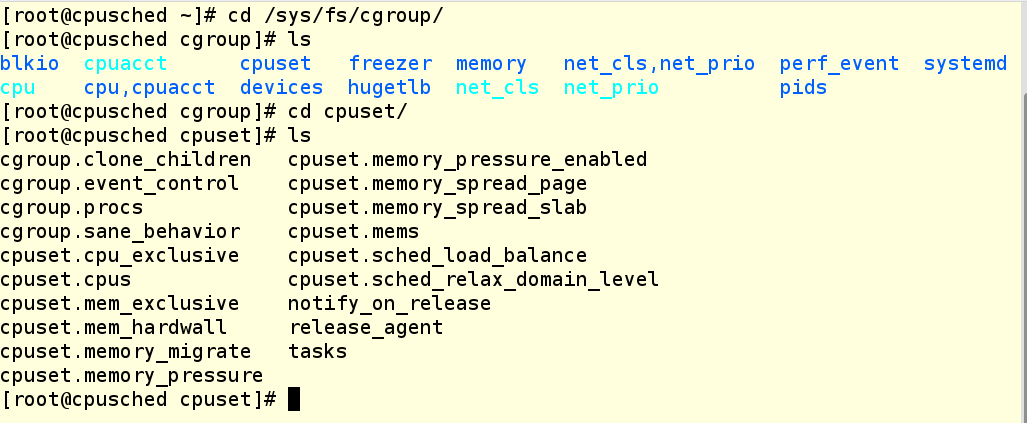
Checking on the system, libcgroup-tools is installed:

If not installed, a quick yum install libcgroup-tools would fix us right up. No reboot required.
Time to make a cpuset. We’re going to use the following commands to create the new cpuset cgroup and then assign some goodness to it:
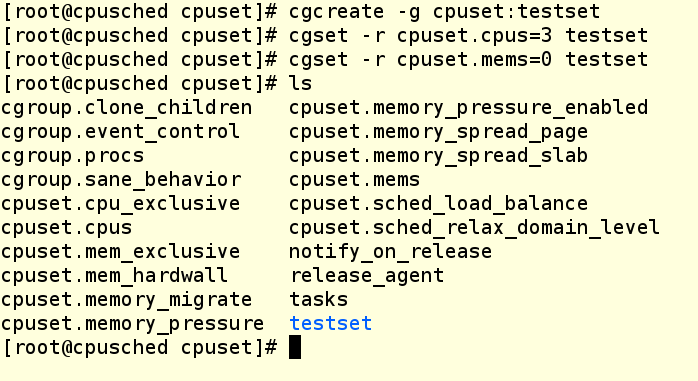
Cgcreate makes a brand new cgroup named “testset” and puts it under the cpuset controller. We then assign core 3 of our VM to the new cpuset and then NUMA zone 0 to the same. Even if we’re not using a NUMA based system (hint, we’re not) you still need to set the zone or else you can’t assign tasks to the cgroup. Finally, we see that the testset subdirectory has been created in the virtual file system. Let’s take a peek at it.
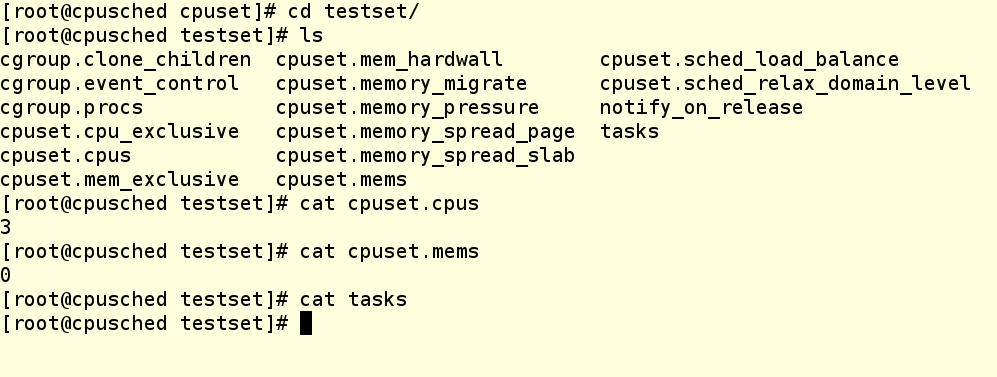
We can see that our changes are there and that there are currently no processes running on the cpuset. How do we get something running there?
Well, there are a few ways:
-
We can echo the PID of an existing process into the file tasks. While this works fine, it’s the least elegant way to do so.
-
We can start a process using cgexec and declare the group to run it in. This works ok for non-daemon applications and can be integrated into an application’s startup script.
-
We can create a service file for applications that are started as daemons under systemd.
Let’s take a look at cgexec.

We started up foo.exe, which launches a child process that does a whole lot of nothing while burning a whole lot of CPU (sounds like a politician, eh?). In the cgexec command, the --sticky option says “any child processes need to stay in the same cgroup as the parent”, so that’s a pretty important option to remember. We can see that the cgroup now has 2 PIDS running under it. Let’s check out top:
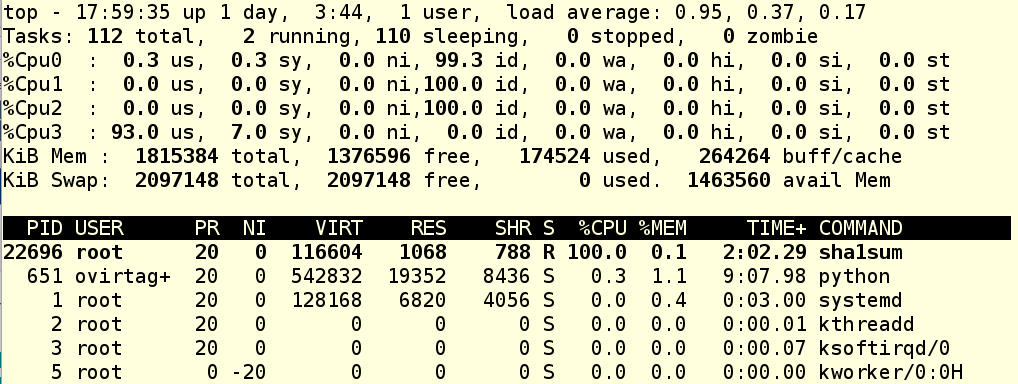
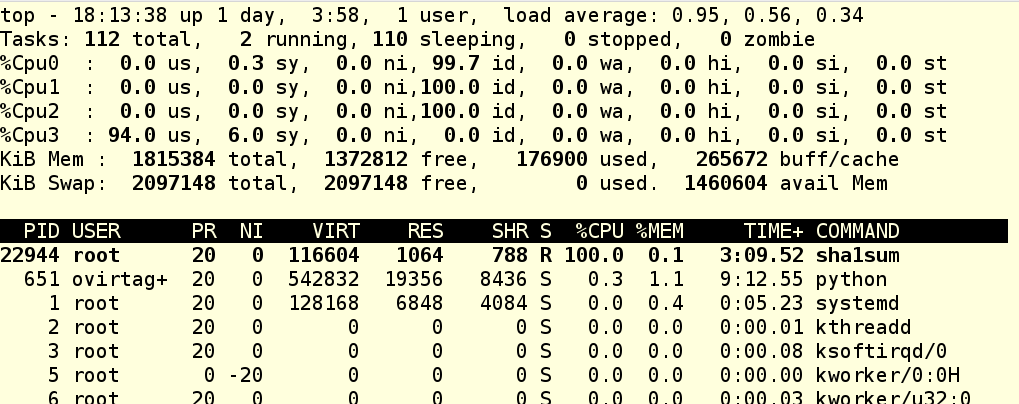
As we can see, CPU 3 is having a grand old time right now.
Here is what a unit file looks like to start the same application as a systemd service:
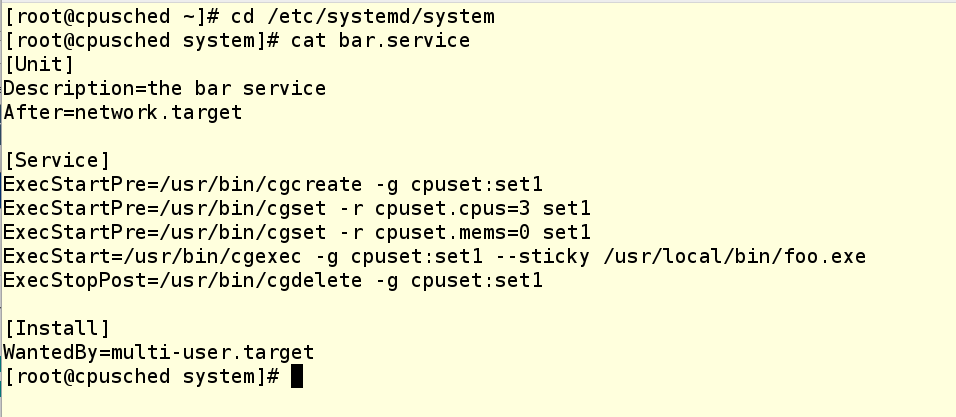
The unit file uses three ExecStartPre commands to run the setup that we already did by hand. ExecStart is then used to start the application. When stopped, our ExecStopPost cleans up after us by deleting the cgroup.
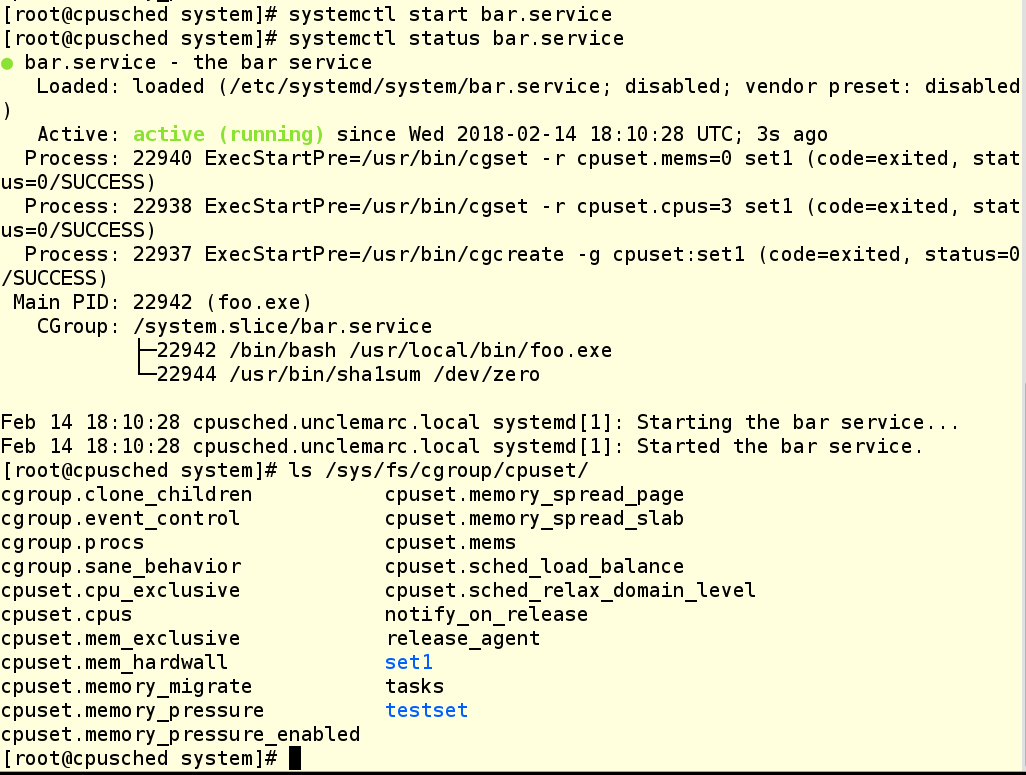
You can see that we’ve created a new cgroup called set1 for this test. Yes, you can have multiple cgroups active that share CPUs. This could be useful or confusing, depending upon how careful you are.
Is it working? I think so!
And now we can shut it down. We can also verify that the cgroup has been destroyed
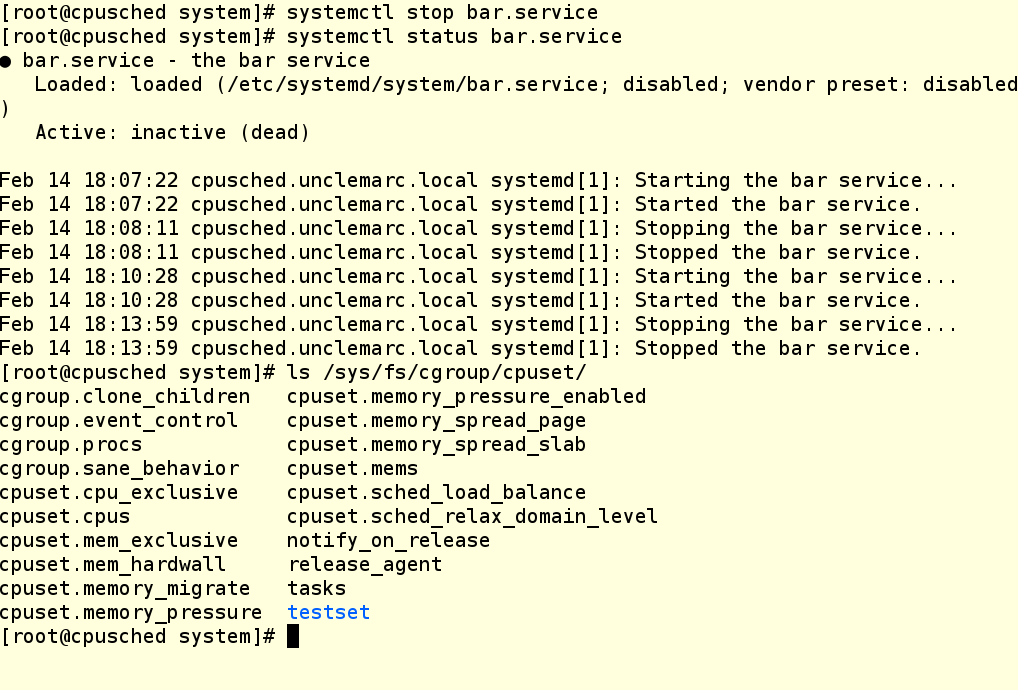
VERY IMPORTANT: When we create cgroups using cgcreate, they are not persistent across system reboots. Therefore, the creation of these groups needs to be part of startup scripts and unit files.
You now have Yet Another Tool or Two in your belt as you go forth and dominate the world using cgroups. Enjoy!

Marc Richter (RHCE) is a Senior Technical Account Manager (TAM) in the US Northeast region. He has expertise in Red Hat Enterprise Linux (going all the way back to the glory days of Red Hat Enterprise Linux 4) as well as Red Hat Satellite. Marc has been a professional Linux nerd for 15 years, having spent time in the pharma industry prior to landing at Red Hat. Find more posts by Marc at https://www.redhat.com/en/about/blog/authors/marc-richter
A Red Hat Technical Account Manager (TAM) is a specialized product expert who works collaboratively with IT organizations to strategically plan for successful deployments and help realize optimal performance and growth. The TAM is part of Red Hat’s world class Customer Experience and Engagement organization and provides proactive advice and guidance to help you identify and address potential problems before they occur. Should a problem arise, your TAM will own the issue and engage the best resources to resolve it as quickly as possible with minimal disruption to your business.
Connect with TAMs at a Red Hat Convergence event near you! Red Hat Convergence is a free, invitation-only event offering technical users an opportunity to deepen their Red Hat product knowledge and discover new ways to apply open source technology to meet their business goals. These events travel to cities around the world to provide you with a convenient, local one-day experience to learn and connect with Red Hat experts and industry peers.
Open source is collaborative curiosity. Join us at Red Hat Summit, May 8-10, in San Francisco to connect with TAMs and other Red Hat experts in person! Register now for only US$1,100 using code CEE18.
À propos de l'auteur

Marc Richter (RHCE) is a Principal Technical Account Manager (TAM) in the US Northeast region. Prior to coming to Red Hat in 2015, Richter spent 10 years as a Linux administrator and engineer at Merck. He has been a Linux user since the late 1990s and a computer nerd since his first encounter with the Apple 2 in 1978. His focus at Red Hat is RHEL Platform, especially around performance and systems management.
Plus de résultats similaires
Shift gears: 10 stories redefining enterprise IT
Friday Five — March 20, 2026 | Red Hat
Keeping Track Of Vulnerabilities With CVEs | Compiler
Post-quantum Cryptography | Compiler
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud