


Taking generative AI (gen AI) from experimentation to enterprise deployment is never one-size-fits-all. Healthcare, finance, manufacturing, and retail each have their own vocabularies, data quirks, and compliance challenges. These complexities can’t be addressed with generic workflows because real, business-critical deployments demand depth, control, and precision.
Red Hat AI offers a model customization experience that builds on the success of InstructLab, evolving it into a modular architecture powered by Python libraries created by Red Hat. This approach preserves InstructLab’s core strengths—its open, extensible pipeline for fine-tuning and instruction-following—while enabling greater flexibility and scalability for enterprise environments.
With this foundation, AI experts and ML practitioners can adapt methods, orchestrate pipelines, and scale model training without losing the agility to evolve as techniques improve. The result is a more sophisticated path to enterprise-grade model customization—one that delivers adaptability and control without sacrificing speed.
At the heart of this evolution are 3 core components that enable experts to fine-tune models and integrate them effectively with retrieval-augmented generation (RAG).
- Docling for data processing
- SDG hub for synthetic data generation (SDG)
- Training hub for fine-tuning and continual learning
Since these components are modular, you can use them independently or connect them end-to-end. We will also provide more supported notebooks and AI/data science pipelines that teach you the technology as well as how to adapt it to your use case, your data, your model, and run it reliably by combining data processing, synthetic data generation, and fine-tuning techniques.
Docling: Document intelligence
Docling is our supported solution for data processing. It’s the number one open source repository for document intelligence. Docling allows you to preprocess and structure your enterprise documents with confidence—whether it’s PDFs, HTML, Markdown, or Office files.
And it’s not just about local experimentation. With Red Hat’s supported build, Docling integrates directly into Kubeflow Pipelines, so you can process documents at scale—powering applications like information extraction, RAG pipelines, and compliance workflows.
SDG hub: Collection of high quality synthetic data pipelines
SDG hub is a modular framework for building and orchestrating high-quality synthetic data pipelines for model training. It provides a growing collection of validated, out-of-the-box pipelines designed to accelerate data generation and fine-tuning workflows.
With SDG hub, you can:
- Leverage validated pipelines for immediate use in model training.
- Mix and match both large language model (LLM)-powered and traditional components to compose flexible data flows.
- Orchestrate everything from simple transforms to complex multistage pipelines with minimal code.
- Extend and customize—create your own blocks and plug them into existing flows effortlessly.
Built for transparency and modularity, SDG hub makes sure that every synthetic data pipeline is production-ready, reusable, and easily auditable. Its maintained library of validated pipelines continues to grow, empowering teams to accelerate experimentation while maintaining consistency and quality across use cases.
Training hub: Simplifying model training and adaptation in one place
The training hub offers a consistent and reliable interface for accessing the latest training algorithms. It's a semantic layer with a stable API that remains consistent even after an algorithm is adopted by broader upstream communities. This allows you to leverage new research early while maintaining a consistent experience.
With the Red Hat AI 3 release, the training hub will support a range of powerful training methods, including:
- Supervised fine-tuning (SFT) from
instructlab.training - Orthogonal subspace learning for LLMs, a new continual-learning post-training algorithm that solves the problem of catastrophic forgetting in LLMs
- Full compatibility with LAB’s multiphase pipeline
- Integration with the latest open source models like GPT-OSS, for both SFT and continual learning
The training hub algorithms are being integrated with Kubeflow SDK and Kubeflow Trainer allowing to scale training algorithms into distributed production grade runs on Red Hat OpenShift AI.
The path from experiment to enterprise deployment
To make this journey even easier, Red Hat AI provides guided examples that guide customers through the full workflow—using Docling for enterprise document intelligence, SDG hub for generating high-quality synthetic training datasets, and training hub for fine-tuning models on that data.
These guided examples are developed by an open source community, but enterprises can run them in a fully supported way on OpenShift AI using our validated builds of these libraries.
From a UX perspective, the experimentation flow starts with trying custom notebooks and scripts in a workbench. Once the data scientist is satisfied with the initial experimentation, the model customization workflow is moved to enterprise deployment, taking advantage of distributed workloads across the cluster using multiple nodes (KubeFlow Trainer) and distributed steps on orchestrated workflows (KubeFlow Pipeline), while reusing pipeline components/features for each step—making it simple to scale from prototype to production.
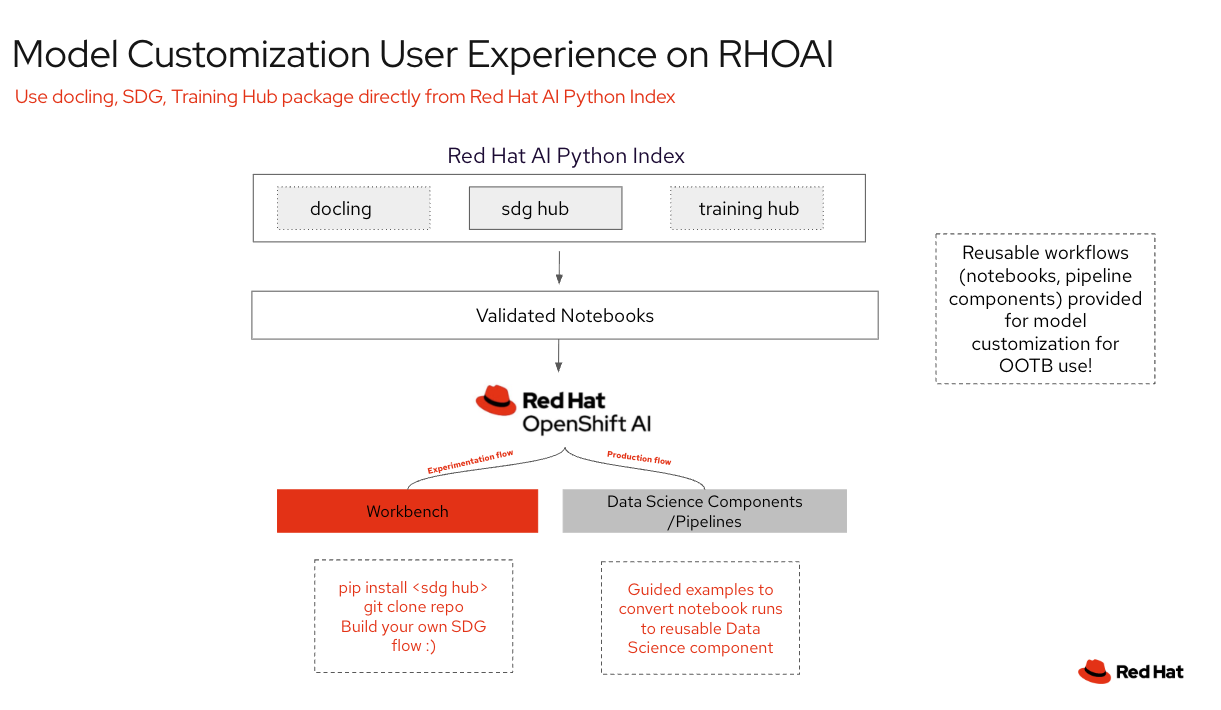
Red Hat AI supports client needs for first-class model customization by implementing individual steps as separate, reusable components within KubeFlow Pipelines. This strategy is designed to streamline complex model customization by delivering flexible, reusable, and extensible pipelines and components.
Conclusion
Most of the foundation models today are not able to make use of the private data that truly matters to an enterprise. Your internal documents, business processes, and domain expertise are invisible to general-purpose models out of the box. Fine-tuning is what bridges that gap—making models contextually relevant, accurate, and valuable for your teams and customers.
We’re not oversimplifying the problem. Instead, we're giving you enterprise-ready building blocks—flexible enough for experimentation, and reliable enough for production. Your data scientists and engineers bring the expertise, and Red Hat provides the platform to help make models smarter, faster, and more scalable.
Red Hat AI simplifies the often-complex process of model fine-tuning, giving your teams the tools to efficiently connect proprietary data to models.
This integrated platform provides a streamlined path from data preparation—using frameworks like Docling and synthetic data pipelines like SDG hub—through advanced training techniques such as continual learning with training hub, all the way to scalable deployment via KubeFlow Trainer and KubeFlow Pipelines.
The result is an accelerated, governed path to creating high-value AI models that enable you to turn your unique data into a powerful competitive advantage.
리소스
적응형 엔터프라이즈: AI 준비성은 곧 위기 대응력
저자 소개
Aditi is a Technical Product Manager at Red Hat, working on Instruct Lab’s synthetic data generation capabilities. She is passionate about leveraging generative AI to create seamless, impactful end user experiences.
Jehlum is a Product Manager in the Red Hat AI team. She's focused on building platforms for generative AI applications. I am especially interested in data processing, observability, safety, evaluation - all key components to build production-grade generative AI applications on platforms that scale.
Ana Biazetti is a senior architect at Red Hat Openshift AI product organization, focusing on Model Customization, Fine Tuning and Distributed Training.
유사한 검색 결과
빠르게 진화하는 AI 위협, 더 빠른 대응
AI의 미래를 위한 하이브리드 기반
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래