

최근 주목을 끄는 추세가 있습니다. 그것은 바로 대규모 언어 모델(Large Language Model, LLM) 인프라를 사내에 도입하는 조직이 늘고 있다는 사실입니다. 대기 시간, 컴플라이언스 또는 데이터 프라이버시와 관련하여 자체 하드웨어에서 오픈소스 모델을 사용하는 셀프 호스팅을 통해 AI 여정을 주도적으로 관리할 수 있습니다. 그러나 LLM을 실험 단계에서 프로덕션급 서비스로 확장하려면 상당한 비용과 함께 복잡성이 뒤따릅니다.
새로운 오픈소스 프레임워크인 llm-d는 이러한 과제를 해결하는 것을 목적으로 하며, Red Hat, IBM, Google을 비롯한 강력한 기여자들의 지원을 받고 있습니다. 이는 문제의 핵심인 AI 추론에 초점을 맞춥니다. AI 추론은 모델이 프롬프트, 에이전트, 검색 증강 생성(Retrieval-Augmented Generation, RAG) 등에 대한 결과를 생성하는 프로세스를 말합니다.
스마트한 스케줄링 결정(세분화)과 AI 특화 라우팅 패턴을 통해, llm-d는 LLM을 위한 동적이고 지능적인 워크로드 분산을 가능하게 합니다. 이것이 중요한 이유는 무엇일까요? llm-d의 작동 방식을 살펴보고 llm-d가 AI 비용을 절감하면서 성능을 높이는 데 어떻게 도움이 될 수 있는지 알아보겠습니다.
LLM 추론 확장 관련 과제
쿠버네티스와 같은 플랫폼에서 기존 웹 서비스를 확장하는 것은 일정한 패턴을 따릅니다. 표준 HTTP 요청은 일반적으로 빠르고 균일하며 스테이트리스(Stateless)인 것이 특징입니다. 그러나 LLM 추론 확장은 근본적으로 다른 문제입니다.
주요 이유 중 하나는 요청 특성의 편차가 크기 때문입니다. 예를 들어, RAG 패턴은 벡터 데이터베이스의 컨텍스트가 포함된 긴 입력 프롬프트를 사용하여 한 문장으로 된 짧은 답변을 생성할 수 있습니다. 반대로 추론 태스크는 짧은 프롬프트로 시작하여 긴 멀티 스텝 응답을 생성할 수 있습니다. 이러한 차이로 인해 성능이 떨어지고 테일 대기 시간(ITL)이 증가할 수 있는 부하 불균형이 발생합니다. 또한 LLM 추론은 중간 결과를 저장하기 위해 LLM의 단기 메모리인 키 값(key value, KV) 캐시에 크게 의존합니다. 기존 부하 분산은 이 캐시의 상태를 인식하지 못하기 때문에 요청 라우팅이 비효율적이고 컴퓨팅 리소스 활용률이 낮습니다.

쿠버네티스의 현재 접근 방식은 LLM을 모놀리식 컨테이너, 즉 가시성이나 제어 권한이 없는 대규모 블랙박스로 배포하는 것이었습니다. 이는 프롬프트 구조, 토큰 수, 응답 대기 시간 목표(서비스 수준 목표또는 SLO), 캐시 가용성 및 기타 여러 요인을 무시할 뿐만 아니라 효과적인 확장을 어렵게 만듭니다.
간단히 말해 현재의 추론 시스템은 비효율적이며 필요한 것 이상으로 많은 컴퓨팅 리소스를 사용하고 있습니다.
llm-d를 통해 추론의 효율성과 비용 효율성 향상
vLLM은 광범위한 하드웨어 전반에서 광범위한 모델 지원을 제공하지만, llm-d는 여기서 한 단계 더 나아갑니다. 기존 엔터프라이즈 IT 인프라를 기반으로 구축된 llm-d는 분산형 및 고급 추론 기능을 제공하여 리소스를 절약하고 성능을 개선하는 데 도움이 됩니다. 예를 들면 첫 토큰 생성 시간이 3배 개선되거나 대기 시간(SLO) 제약 조건에서 성능이 2배 향상될 수 있습니다. llm-d는 강력하고 다양한 혁신 사항을 제공하지만, 추론을 개선하는 데 도움이 되는 두 가지 혁신에 초점을 맞추고 있습니다.
- 분리: 프로세스를 분리하면 추론 중에 하드웨어 가속기를 더 효율적으로 사용할 수 있습니다. 여기에는 프롬프트 처리(프리필 단계)를 토큰 생성(디코드 단계)에서 포드(pod)라는 개별 워크로드로 분리하는 작업이 포함됩니다. 이렇게 분리하면 컴퓨팅 요구 사항이 다르기 때문에 각 단계를 독립적으로 확장하고 최적화할 수 있습니다.
- 지능형 스케줄링 계층: 쿠버네티스 게이트웨이 API를 확장하여 수신 요청에 대해 더 정교한 라우팅 결정을 지원합니다. 이는 KV 캐시 활용도, 포드 부하와 같은 실시간 데이터를 활용하여 요청을 최적의 인스턴스로 전달함으로써 캐시 적중을 극대화하고 워크로드를 클러스터 전반으로 분산합니다.

재계산을 방지하기 위해 요청 전반에서 KV 페어를 캐싱하는 기능 외에도, llm-d는 LLM 추론을 모듈식의 지능형 서비스로 분할하여 확장 가능한 성능을 지원합니다(vLLM 자체에서 제공하는 광범위한 지원을 기반으로 함). 각 기술을 자세히 살펴보고 몇 가지 실제적인 사례를 통해 llm-d에서 이러한 기술이 어떻게 사용되는지 알아보겠습니다.
분리를 통해 대기 시간을 줄이고 처리량을 늘리는 방법
LLM 추론의 프리필(prefill) 단계와 디코드 단계의 근본적인 차이로 인해 리소스를 균일하게 할당하는 데 어려움이 따릅니다. 입력 프롬프트를 처리하는 프리필 단계에서는 일반적으로 대량의 계산이 수행되며, 초기 KV 캐시 엔트리를 생성하기 위해 높은 처리 능력이 필요합니다. 반대로 토큰이 하나씩 생성되는 디코드 단계는 주로 상대적으로 적은 컴퓨팅을 통해 KV 캐시에서 읽고 쓰는 작업을 포함하므로 메모리 대역폭에 성능이 좌우되는 경우가 많습니다.
llm-d는 분리를 통해 이 서로 다른 특징을 가진 두 단계를 각각 별도의 쿠버네티스 포드에서 처리할 수 있도록 합니다. 즉, 컴퓨팅 집약적인 태스크에 최적화된 리소스로 프리필 포드를 프로비저닝하고 메모리 대역폭 효율성에 맞춤화된 구성으로 포드를 디코딩할 수 있습니다.
LLM 인식 추론 게이트웨이의 작동 방식
llm-d를 사용한 성능 개선을 이끄는 가장 중요한 요소는 지능형 스케줄링 라우터로, 이는 추론 요청이 처리되는 위치와 방법을 효과적으로 조율합니다. 추론 요청이 llm-d 게이트웨이(kgateway 기반)에 도착하면 단순히 사용 가능한 다음 포드로 전달되는 것이 아니라, llm-d 스케줄러의 핵심 구성 요소인 엔드포인트 선택기(Endpoint Picker, EPP)가 여러 실시간 요인을 평가하여 최적의 대상을 결정합니다.
- KV 캐시 인식: 스케줄러는 실행 중인 모든 vLLM 복제본에서 KV 캐시 상태의 인덱스를 유지 관리합니다. 새로운 요청이 특정 포드에 이미 캐시된 세션과 공통된 접두사를 공유하는 경우 스케줄러는 해당 포드로의 라우팅을 우선적으로 고려합니다. 따라서 캐시 적중률이 크게 증가하여 중복 프리필 계산을 방지하고 대기 시간을 직접적으로 줄일 수 있습니다.
- 부하 인식: 스케줄러는 단순한 요청 수 외에도 각 vLLM 포드의 실제 부하를 평가하여 GPU 메모리 사용률과 처리 대기열을 고려하므로 병목 현상을 방지하는 데 도움이 됩니다.
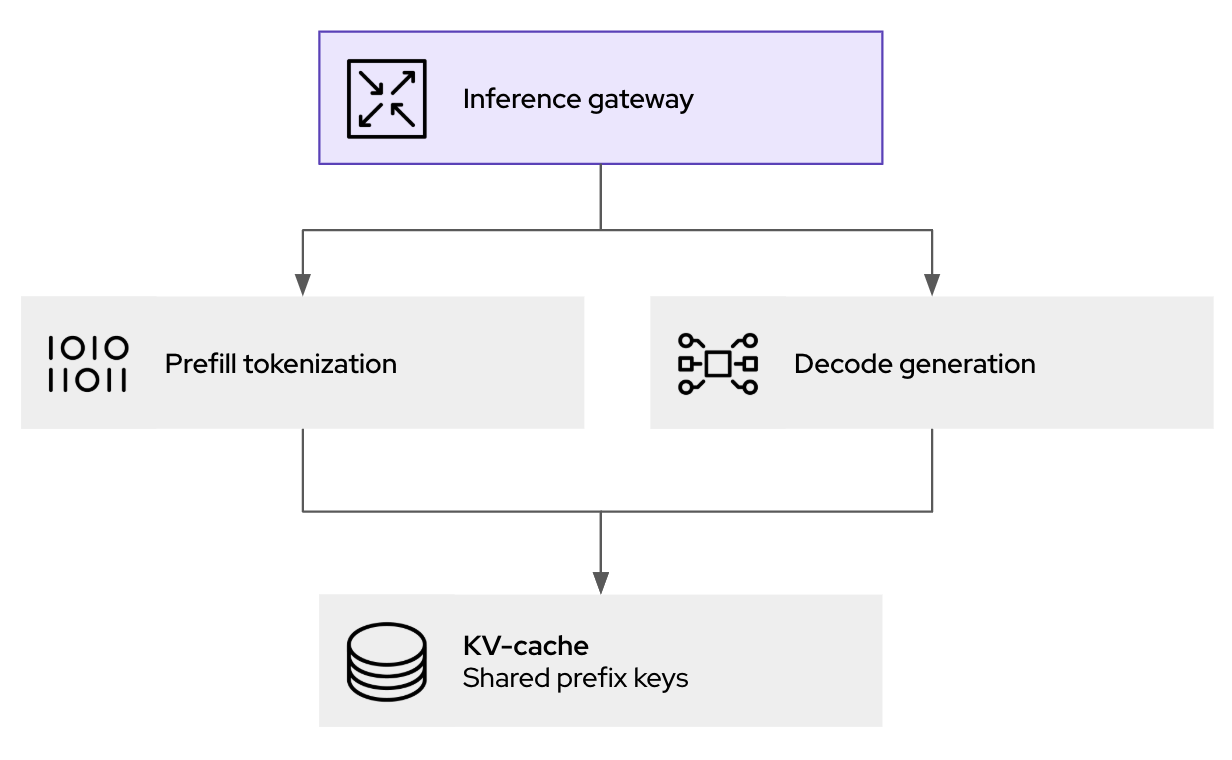
이러한 쿠버네티스 네이티브 접근 방식은 생성형 AI 추론을 위한 정책, 보안, 관측성 레이어를 제공합니다. 이는 트래픽 처리에 도움이 될 뿐만 아니라 추론으로 전달하기 전에 즉각적인 로깅 및 감사(거버넌스 및 컴플라이언스 측면)는 물론 가드레일을 지원합니다.
llm-d 시작하기
llm-d 프로젝트에 거는 기대는 매우 큽니다. vLLM이 단일 서버 환경에 적합하다면, llm-d는 고성능의 비용 효율적인 AI 추론을 목표로 클러스터를 관리하는 운영자에게 적합합니다. 직접 살펴볼 준비가 되셨나요? GitHub에서 llm-d 리포지토리에 대해 알아보고 Slack에서 대화에 참여하세요! 궁금한 점에 대해 질문하고 업계 동료들과 함께하세요.
AI의 미래는 개방과 협업의 원칙을 기반으로 건설되고 있습니다. Red Hat은 vLLM과 같은 커뮤니티, 그리고 llm-d와 같은 프로젝트를 통해 개발자가 어디에서나 접근성이 뛰어나고 경제적이며 우수한 성능을 제공하는 AI를 개발할 수 있도록 돕기 위해 최선을 다하고 있습니다.
리소스
엔터프라이즈를 위한 AI 시작하기: 입문자용 가이드
저자 소개
Cedric Clyburn (@cedricclyburn), Senior Developer Advocate at Red Hat, is an enthusiastic software technologist with a background in Kubernetes, DevOps, and container tools. He has experience speaking and organizing conferences including DevNexus, WeAreDevelopers, The Linux Foundation, KCD NYC, and more. Cedric loves all things open-source, and works to make developer's lives easier! Based out of New York.
Christopher Nuland is a Principal Technical Marketing Manager for AI at Red Hat and has been with the company for over six years. Before Red Hat, he focused on machine learning and big data analytics for companies in the finance and agriculture sectors. Once coming to Red Hat, he specialized in cloud native migrations, metrics-driven transformations, and the deployment and management of modern AI platforms as a Senior Architect for Red Hat’s consulting services, working almost exclusively with Fortune 50 companies until recently moving into his current role. Christopher has spoken worldwide on AI at conferences like IBM Think, KubeCon EU/US, and Red Hat’s Summit events.
유사한 검색 결과
빠르게 진화하는 AI 위협, 더 빠른 대응
AI의 미래를 위한 하이브리드 기반
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래