

Introdução
Para manter a continuidade de negócios durante interrupções não planejadas, é essencial ter estratégias de recuperação de desastres em máquinas virtuais (VMs) do Red Hat OpenShift. Com a migração de cargas de trabalho críticas para plataformas Kubernetes, a capacidade de recuperá-las com rapidez e eficácia se torna um requisito operacional essencial para as organizações.
Nos ambientes nativos em nuvem, é comum encontrar máquinas virtuais efêmeras e stateless. No entanto, a maioria das cargas de trabalho de VMs empresariais são stateful. Essas máquinas virtuais exigem armazenamento em bloco persistente que possa ser reconectado durante reinicializações ou migrações. Como resultado, os desafios da recuperação de desastres em máquinas virtuais stateful diferem bastante daqueles resolvidos pelos primeiros padrões de recuperação de desastres do Kubernetes (Spaccoli, 2024), que normalmente se concentram em aplicações stateless baseadas em containers.
Este post explica os diferentes requisitos das VMs stateful. Primeiro, aborda como as opções de arquitetura de cluster e armazenamento afetam a viabilidade do failover, o comportamento da replicação e as metas de RPO/RTO. Em seguida, examina a camada de orquestração, mostrando como conduzir o posicionamento e a recuperação de cargas de trabalho usando ferramentas nativas do Kubernetes, como Red Hat Advanced Cluster Management, Helm, Kustomize e pipelines do GitOps. Na conclusão, o post mostra que as plataformas de armazenamento avançadas otimizam o processo de recuperação e conectam a infraestrutura à automação no nível da aplicação ao replicar volumes em bloco e manifestos do Kubernetes.
Conheça nossa terminologia
Antes de continuar, vamos definir alguns termos importantes que usamos:
Desastre:
Neste artigo, o termo "desastre" se refere à perda de um local. A recuperação de desastres (DR), por sua vez, sempre envolve minimizar a interrupção de um serviço de negócios. Ao perder um local, você precisa implementar os planos de DR para restaurar o serviço no local alternativo da forma mais rápida e eficiente possível.
Observação: o plano de DR não é executado somente quando um local é perdido. Mediante uma falha em um componente principal, pode ser necessário mover serviços empresariais individuais para um local alternativo enquanto o componente é restaurado. Nesse caso, é comum adotar planos de recuperação de desastres para tais serviços individuais.
Falha de componente:
Ocorre quando um ou mais subsistemas falham, afetando um subconjunto de aplicações empresariais. Para esse modo de falha, é preciso executar o failover do processamento para um sistema alternativo no local primário ou aplicar planos de DR individuais para mover o processamento da aplicação empresarial para um local secundário.
Objetivo de ponto de recuperação (RPO):
Representa a quantidade máxima de dados (medidos por tempo) aceitável para ser perdida após a recuperação de um desastre ou evento de falha em uma organização.
Objetivo de tempo de recuperação (RTO):
É o tempo máximo pelo qual a organização tolera a indisponibilidade de um serviço. Observe que diferentes opções de arquitetura afetam o RTO, mas isso não será discutido em detalhes neste post.
DR metropolitana e regional:
Há dois tipos de recuperação de desastres: a metropolitana e a regional.
- A DR metropolitana é usada quando os data centers estão próximos o suficiente e o desempenho da rede permite a replicação de dados síncrona, cujo benefício é alcançar o RPO de zero.
- A DR regional é usada quando a replicação assíncrona é necessária, ou seja, quando os data centers estão muito distantes e não permitem a replicação síncrona. A replicação assíncrona quase certamente causará perda de dados. Para os fins deste post, a quantidade de dados perdida não importa.
Observação: se a sua infraestrutura de armazenamento não for compatível com a replicação síncrona, a arquitetura de DR regional será usada para a DR metropolitana.
Reinicializações em massa:
Este evento ocorre quando você tenta reiniciar simultaneamente um número de máquinas virtuais muito grande, sobrecarregando o hypervisor e a infraestrutura de suporte. Como resultado, nenhuma VM é reiniciada ou o processo leva muito mais tempo do que o aceitável. Isso também pode ser descrito como um ataque de negação de serviço não malicioso.
Abordagens de arquitetura para a continuidade de negócios
Há várias abordagens para alcançar a continuidade de negócios e a recuperação de desastres. Confira uma discussão geral sobre o assunto no whitepaper Cloud Native Disaster Recovery for Stateful Workloads (Spaccoli, 2024) da Cloud Native Computing Foundation (CNCF). Em resumo, o diagrama a seguir ilustra quatro abordagens comuns de recuperação de desastres, e a explicação detalhada de cada uma está disponível no whitepaper.
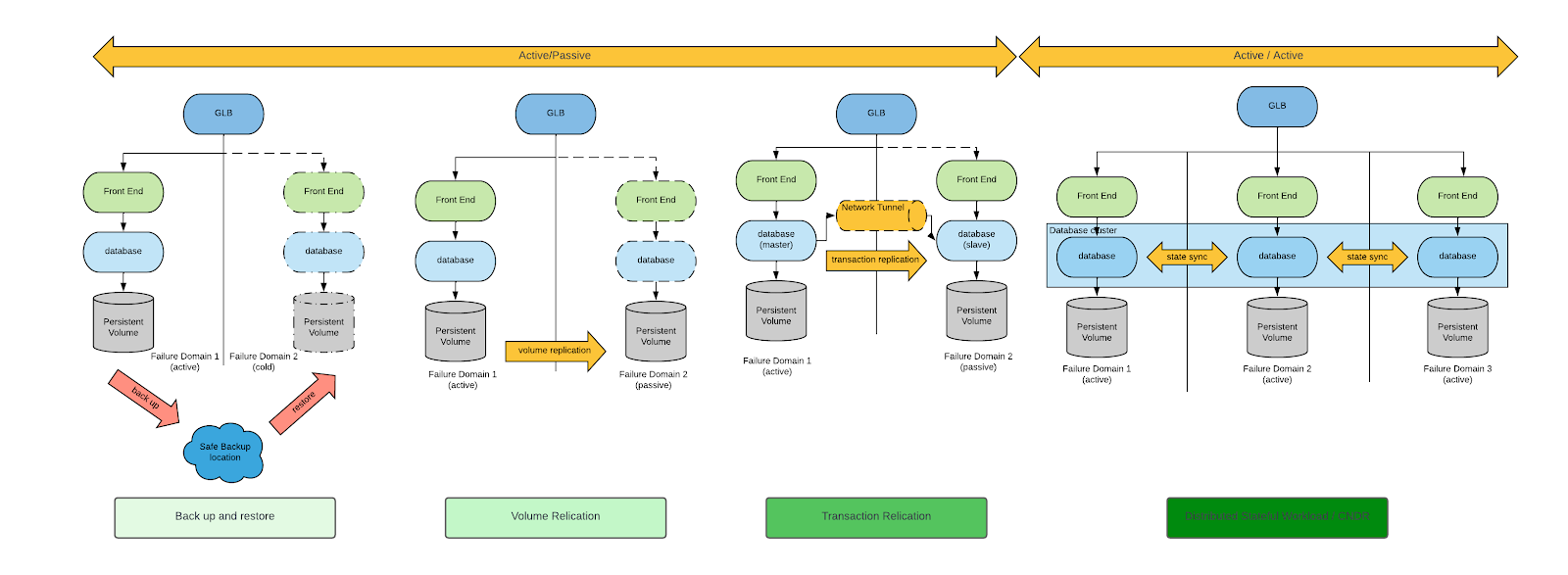
Considerando os requisitos de recuperação de desastres em máquinas virtuais, os únicos padrões apropriados são: backup, restauração e replicação de volumes.
Embora todos esses métodos sejam viáveis, as abordagens de recuperação de desastres baseadas em replicação de volumes minimizam o RPO e o RTO. Por isso, vamos nos concentrar somente nelas.
Com o campo de análise definido, discutiremos duas arquiteturas de DR que usam tipos diferentes de replicação de volumes:
- Replicação unidirecional
- Replicação simétrica ou bidirecional
Replicação unidirecional
Na replicação unidirecional, os volumes são replicados de um data center para outro, mas não fazem o caminho oposto. A direção é controlada pela matriz de armazenamento, e a replicação do volume pode ser síncrona ou assíncrona. A escolha depende da capacidade da matriz de armazenamento e da latência entre os dois data centers. A replicação assíncrona é ideal para data centers que têm alta latência e estão na mesma região geográfica do mundo, mas não na mesma área metropolitana.
A arquitetura da replicação unidirecional é representada nesta figura:
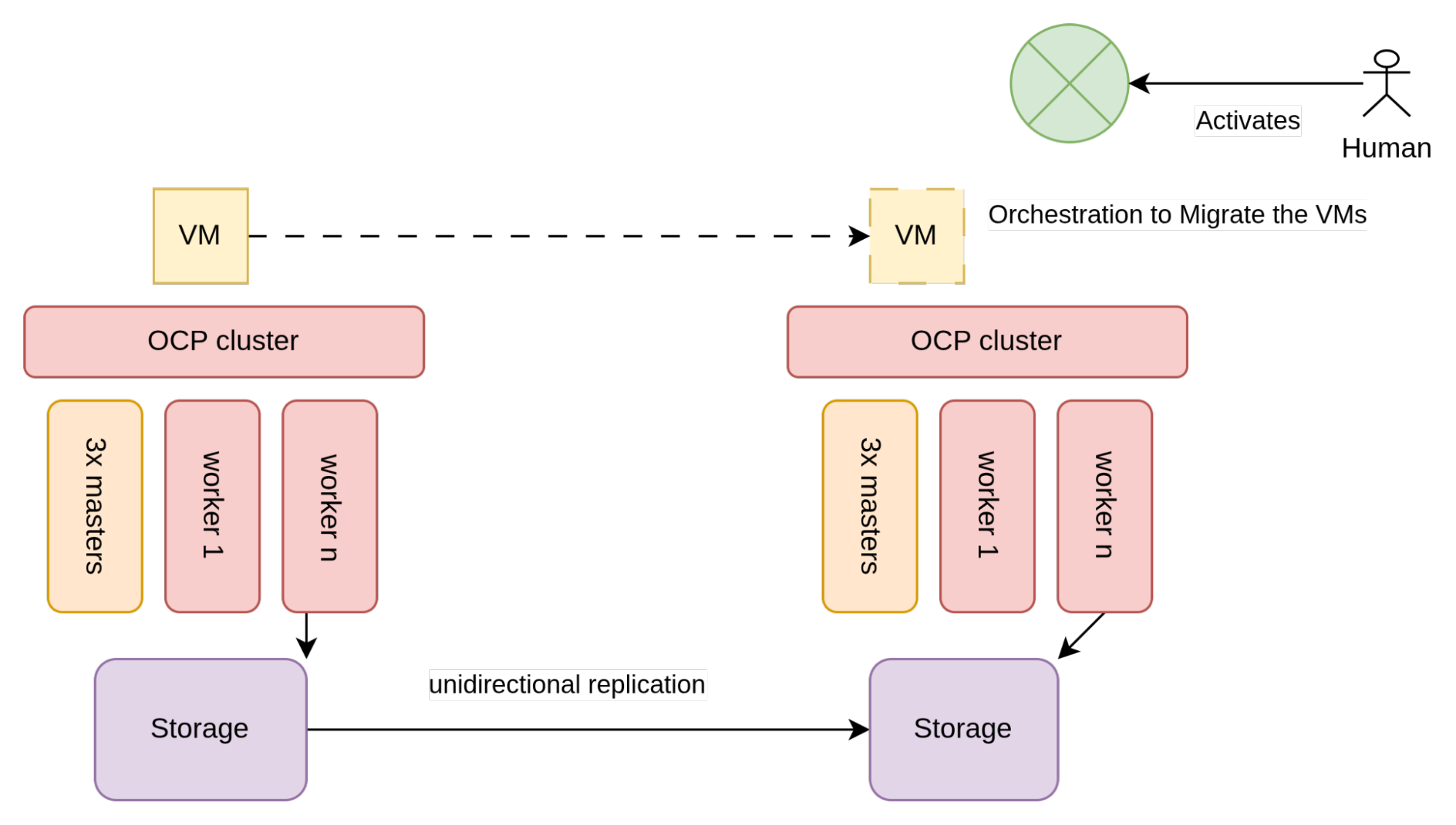
Conforme ilustrado na figura 2, o armazenamento usado pelas VMs (normalmente, matrizes SAN) é configurado para permitir a replicação unidirecional.
Cada data center tem um cluster do OpenShift conectado à matriz de armazenamento local. Como os clusters não se reconhecem, as restrições para implementar essa arquitetura dependem do fornecedor de armazenamento e dos requisitos para habilitar a replicação unidirecional.
Considerações sobre a replicação unidirecional de volumes
A replicação de volumes não é padronizada na especificação CSI do Kubernetes. Como resultado, os fornecedores de armazenamento criaram suas próprias definições de recursos personalizados (CRDs) para oferecer essa funcionalidade. Há três níveis de maturidade:
- A replicação de volumes não está disponível no nível da CSI ou está disponível de modo que a criação de uma orquestração de DR adequada exige chamar a API da matriz de armazenamento diretamente.
- A replicação de volumes está disponível no nível da CSI.
- A replicação de volumes está disponível e o fornecedor também gerencia a restauração dos metadados de namespace (ou seja, as máquinas virtuais e outros manifestos presentes no namespace).
Devido a essa fragmentação, não é simples escrever um processo de recuperação de desastres independente de fornecedor para uma configuração de DR regional. A gravação necessária para criar uma orquestração de DR adequada depende do fornecedor de armazenamento.
Vamos observar o comportamento dessa arquitetura em diferentes modos de falha: falha no nó do OpenShift, falha na matriz de armazenamento (falhas de componentes) e falha no data center inteiro (cenário real de DR).
Falha no nó do OpenShift
Em caso de falha de um nó (componente), o scheduler do OpenShift Virtualization é responsável por reiniciar automaticamente a VM no nó seguinte mais apropriado do cluster. Nenhuma outra ação é necessária nesse cenário.
Falha na matriz de armazenamento
Se a matriz de armazenamento falhar, todas as VMs que dependem dela também falharão. Nesse caso, o processo de DR precisará ser executado. (Consulte as etapas necessárias na seção Processo de recuperação de desastres.)
Falha no data center
Durante a falha de um data center, é necessário fazer a DR para reiniciar todas as VMs não afetadas no data center. A automação desempenha um papel fundamental aqui. No entanto, o processo geralmente é iniciado por um agente humano seguindo um framework de gerenciamento de incidentes graves. Confira na seção a seguir uma visão geral das etapas envolvidas.
Processo de recuperação de desastres
Os procedimentos de DR podem ser muito complexos. Mas, de modo geral, devem considerar o seguinte:
- Os volumes de VMs que fazem parte da mesma aplicação devem ser replicados de maneira consistente. Normalmente, esses volumes estão no mesmo grupo de consistência.
- Deve ser possível controlar se e em qual direção os volumes em um grupo de consistência devem ser replicados. Em circunstâncias normais, os volumes são replicados do local ativo para o local passivo. Durante um failover, os volumes não são replicados. Na fase de preparação para o failback, os volumes são replicados do local passivo para o local ativo. Durante o failback, os volumes não são replicados.
- As máquinas virtuais devem ser reiniciadas no outro data center e capazes de se conectar ao volume de armazenamento replicado.
- Para evitar reinicializações em massa, pode ser necessário limitar a reinicialização das VMs. Além disso, às vezes é desejável priorizar a sequência em que elas são reinicializadas. Assim, é possível garantir que as aplicações mais críticas sejam iniciadas primeiro ou que componentes dependentes, como bancos de dados, sejam iniciados antes dos serviços que dependem deles.
Considerações sobre custos
O cluster do OpenShift, dependendo da configuração, pode ser considerado um local de DR morno ou quente. Os locais quentes precisam estar totalmente cobertos pelas subscrições, mas os locais mornos não, podendo gerar economias.
Em geral, o local da recuperação de desastres é considerado morno quando não tem cargas de trabalho ativas. É possível configurar volumes persistentes (PVs), solicitações de volume persistente (PVCs) e até mesmo máquinas virtuais fora de execução, mas prontas para serem iniciadas em caso de desastre, e ainda manter a designação de local morno.
Replicação simétrica ativa/passiva
Não é comum ter 100% das cargas de trabalho no local ativo. As organizações costumam dividi-las meio a meio entre os data centers primário e secundário. Com essa abordagem prática, um desastre não interrompe todos os serviços de uma vez. Além disso, reduz o esforço geral de recuperação.
Ao distribuir VMs ativas para cada data center, cada lado é configurado para conseguir executar failover para o outro lado. Essa configuração também é conhecida como simétrica ativa/passiva.
Ela é usada junto ao OpenShift Virtualization e à arquitetura que analisamos acima. Observe que, neste método, os dois data centers são considerados ativos e, portanto, todos os nós do OpenShift devem estar cobertos por uma subscrição.
Replicação simétrica
Neste caso, os volumes são replicados de maneira síncrona e em ambas as direções. Os dois data centers podem ter volumes ativos e fazer gravações neles. Para isso, a organização precisa ter dois data centers com latência de rede muito baixa (cerca de <5 ms). Normalmente, isso é possível quando ambos estão na mesma área metropolitana. Por isso, essa arquitetura também é conhecida como DR metropolitana. Nesse caso, esta arquitetura pode ser usada:

Nessa arquitetura, o armazenamento usado pelas máquinas virtuais (geralmente, uma matriz SAN) é configurado para realizar replicação simétrica entre os dois data centers.
Isso cria uma matriz de armazenamento lógico estendida aos dois data centers. Para realizar a replicação simétrica, é necessário ter um "local testemunha" que atue como mediador independente para evitar um "split-brain" no caso de uma falha na rede ou no local.
Em termos de latência, o local testemunha não precisa estar tão próximo quanto os dois data centers principais, pois é usado para criar quórum e desempatar cenários de "split-brain". Esse local deve ser uma zona de disponibilidade independente, não pode transportar cargas de trabalho de aplicações nem ter grande capacidade, mas suas operações devem ter a mesma qualidade de serviço dos outros data centers (por exemplo, segurança física/lógica, gerenciamento de energia e resfriamento).
Com a extensão do armazenamento aos data centers, o OpenShift também é estendido. Para implementar isso em uma arquitetura altamente disponível, o control plane do OpenShift requer três zonas de disponibilidade (locais). Isso porque o banco de dados etcd interno do Kubernetes exige pelo menos três domínios de falha para manter um quórum confiável. Normalmente, o local testemunha do armazenamento é usado como um dos nós do control plane.
A maioria dos fornecedores de SAN (redes de área de armazenamento) oferece suporte à replicação simétrica das matrizes de armazenamento. No entanto, nem todos disponibilizam esse recurso no nível da CSI. Quando o fornecedor oferece o recurso e todos os pré-requisitos e configurações necessários são atendidos, a criação de uma PVC aciona o provisionamento de um número de unidade lógica (LUN) com múltiplos caminhos. O LUN inclui caminhos que vão para ambos os data centers. Portanto, todos os nós do OpenShift devem estar configurados para permitir a conexão com as duas matrizes de armazenamento. Normalmente, o dispositivo de múltiplos caminhos é criado de duas maneiras: com uma configuração de acesso à unidade lógica assimétrica (ALUA) (Pearson IT Certification, 2024), ou seja, caminhos ativo/passivo, onde o caminho ativo leva à matriz mais próxima; ou com um caminho ativo/ativo com pesos diferentes, onde a matriz mais próxima tem pesos altos.
Alguns fornecedores permitem essa arquitetura mesmo quando as conexões fiber channel não são "uniformes". Nesse caso, os nós em um local só podem se conectar à matriz de armazenamento local. Nesse caso, a configuração ALUA não é criada.
Essa topologia de cluster ajuda a proteger contra falhas em componentes e desastres. Vamos analisar o comportamento da arquitetura mediante diferentes modos de falha.
Falha no nó do OpenShift
Em caso de falha de um nó (componente), o scheduler do OpenShift Virtualization é responsável por reiniciar automaticamente a VM no nó seguinte mais apropriado do cluster. Nenhuma outra ação é necessária nesse cenário.
Falha na matriz de armazenamento
Quando uma das duas matrizes de armazenamento falha ou é desativada para manutenção, os LUNs de múltiplos caminhos ajudam a oferecer a continuidade de serviços. Em um cenário de conectividade uniforme, o caminho passivo ou menos ponderado dos LUNs de múltiplos caminhos é usado para conectar a máquina virtual às outras matrizes. Essa falha é completamente transparente para as VMs, resultando em um possível aumento da latência de E/S no disco. Quando a conectividade não é uniforme, a VM precisa ser migrada para um nó com conectividade.
Falha no data center
Quando um data center inteiro fica indisponível, o OpenShift estendido interpreta isso como uma falha em vários nós ao mesmo tempo. O OpenShift começará a programar as VMs para nós no outro data center, conforme descrito na seção Falha no nó do OpenShift.
Desde que haja capacidade de reserva suficiente para migrar as cargas de trabalho, todas as máquinas serão reiniciadas no outro data center. Nas VMs que foram reiniciadas, o RPO é exatamente zero, e o RTO é fornecido pela soma dos seguintes tempos:
- O tempo que o OpenShift leva para perceber que os nós não estão prontos.
- O tempo necessário para isolar os nós.
- O tempo necessário para reiniciar as VMs.
- O tempo necessário para concluir o processo de inicialização da VM.
Em essência, esse mecanismo de DR é totalmente autônomo e não requer intervenção humana. Isso nem sempre é desejável. Para evitar reinicializações em massa, muitas vezes é recomendado controlar quais VMs são reiniciadas e quando esse processo é iniciado.
Considerações sobre a DR metropolitana
Entenda melhor essa abordagem:
- Como as máquinas virtuais são normalmente conectadas a VLANs, para poderem se mover entre os data centers, é necessário que as VLANs também sejam estendidas até o data center metropolitano. Em alguns casos, isso pode ser indesejável.
- Muitas vezes, a rede de gerenciamento do local testemunha (rede de nós do OpenShift) não está na mesma sub-rede L2 que a rede de gerenciamento dos data centers metropolitanos.
- Algumas vertentes não consideram essa solução de recuperação de desastres completa, já que o control plane do OpenShift e o control plane da matriz de armazenamento são dois pontos únicos de falha (SPOF). Esse SPOF é lógico, já que, do ponto de vista físico, há redundância. No entanto, teoricamente, basta um único comando errado no OpenShift ou na matriz de armazenamento para apagar todo o ambiente. Por isso, para cargas de trabalho mais críticas, essa arquitetura às vezes é conectada em série a uma arquitetura de DR regional mais tradicional.
- Por conta própria, durante uma recuperação de desastres, o OpenShift reprograma automaticamente todas as máquinas virtuais no data center afetado para o data center íntegro. Isso pode causar um fenômeno conhecido como reinicialização em massa. Diversas funcionalidades do Kubernetes mitigam esse risco, controlando quando e quais aplicações passam por failover. O conceito de reinicializações em massa será discutido em seções posteriores.
Considerações sobre custos
Na replicação simétrica, como os dois locais pertencem a um único cluster ativo do OpenShift, ambos devem estar totalmente cobertos por uma subscrição. Já na replicação unidirecional, cada local deve ter superprovisionamento de 100%, permitindo executar o failover de 100% do outro local.
Conclusão
Para criar a estratégia de recuperação de desastres do OpenShift Virtualization, o primeiro passo é decidir entre as arquiteturas de replicação unidirecional ou simétrica. Cada modelo tem suas vantagens e desvantagens em relação à complexidade operacional, custo da infraestrutura, garantias de RPO/RTO e potencial de automação. Seja em um design de cluster duplo ou de cluster estendido, a arquitetura de base deve estar alinhada às expectativas de continuidade de negócios e às restrições da infraestrutura. Com a base estabelecida, a segunda etapa muda o foco da infraestrutura para a orquestração: para além do armazenamento, examina como as VMs são posicionadas, reiniciadas e controladas em condições de desastre.
Teste de produto
Red Hat OpenShift Virtualization Engine | Teste de solução
Sobre os autores
Bryon is a skilled infrastructure and software engineering specialist with deep expertise in AI/ML, Kubernetes, OpenShift, cloud-native architecture, and enterprise networking. With a strong background in storage technologies, infrastructure, and virtualisation, Bryon works across domains including system administration, AI model deployment, and platform engineering. He is proficient in C#, Golang and Python, experienced in container orchestration, and actively contributes to Red Hat-based solutions. Passionate about education and enablement, Bryon frequently develops technical workshops and training programs, particularly in AI/ML and DevOps. He is also a practising musician, blending his technical acumen with creative expression.
Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
Mais como este
A nova moeda da velocidade empresarial
Por que agentes de IA são a evolução das aplicações
Container Roundup | Compiler
Untangling Networks | Compiler
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem