Introduction: Important terms
Let’s get on the same page regarding some terms.
-
Virtual Memory Management (VMM) is code in the kernel which, among other things, helps us to present each process with its own virtual address space.
-
Overcommitment means that processes can request more memory from the kernel than we have available physically and as swap. Please note that this is only allowing us to request more, writing to more than available is not possible.
-
A page is a piece of memory.
-
Paging is the operation of making a copy of a page, for example to a swap device.
-
Swapping is the usage of swap devices, so making copies of pages between physical memory and a swap device.
-
Thrashing is when swapping uses more resources than the other processes on the system.
 Read more about optimizing performance for the open-hybrid enterprise.
Read more about optimizing performance for the open-hybrid enterprise.
Visit our Red Hat Enterprise Linux (RHEL) Performance Series page
Read more about optimizing performance for the open-hybrid enterprise.
Overview: When is swap used?
Swap is used to give processes room, even when the physical RAM of the system is already used up. In a normal system configuration, when a system faces memory pressure, swap is used, and later when the memory pressure disappears and the system returns to normal operation, swap is no longer used. In this typical situation, swap helped through the time of memory shortage, at the cost of reduced performance while swapping.
Pages that were stored in swap are not moved back into RAM unless they are accessed/requested. This is the reason that many counters show swapped pages, although the system might already be in a state where no active swapping is happening.
Let’s look at typical speed scales of RAM, SSD and rotating disks. A typical reference to RAM is in the area of 100ns, accessing data on a SSD 150μs (so 1500 times of the RAM) and accessing data on a rotating disk 10ms (so 100.000 times the RAM).
Let’s look at the behaviour of a system with 2GB of RAM, a 2GB swap device, and a hard disk. Just after boot, system processes are using only a few dozens of MB of RAM. This illustration was created with Performance Co-Pilot, which is part of Red Hat Enterprise Linux.
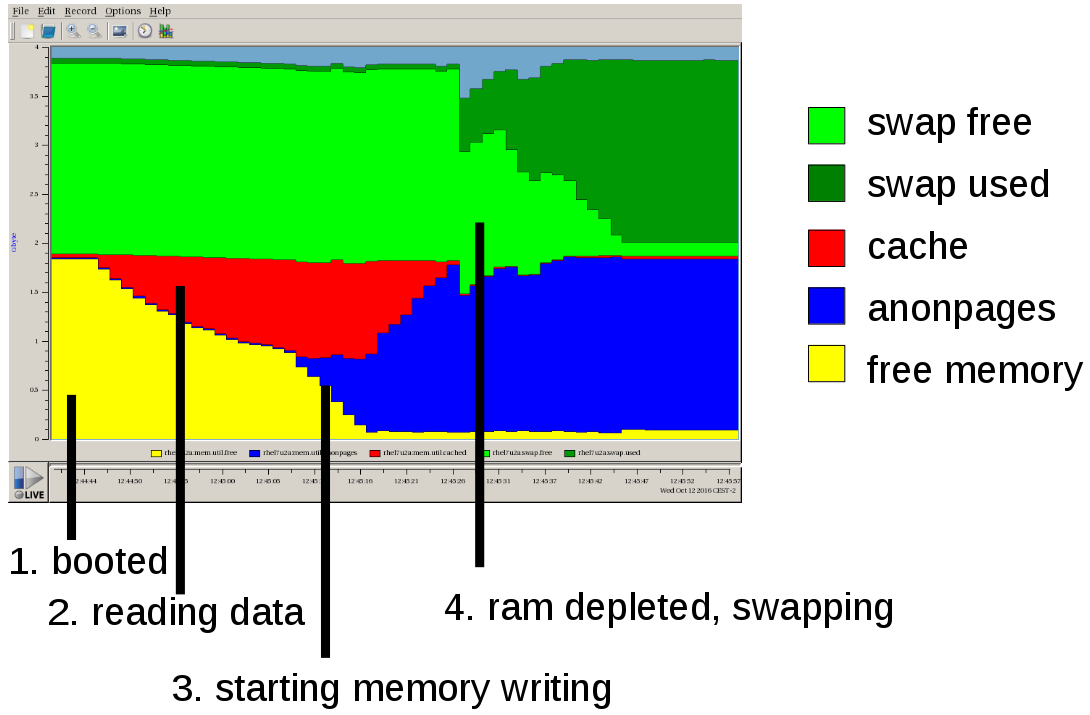
-
A just booted system, most memory is free.
-
Now we start processes, requesting and writing to only a small part of RAM, and reading data from disk. As our RAM would otherwise be unused, the kernel is using it to cache the data we are reading. If data is requested a second time, it is available from the cache.
-
Now we start processes, writing to more RAM. The kernel will now sacrifice the RAM used for disk caching and hand it out to the processes. Once the processes are requesting more memory than we have physically available, the kernel starts to utilize the swap. The process itself sees no difference - just that the swap is by orders of magnitudes slower than physical RAM.
-
If processes attempt to write to more memory than available including swap, the Out of Memory (OOM) handler has to decide for a process, and kill it.
The details: How is swap used?
In the past, some application vendors recommended swap of a size equal to the RAM, or even twice the RAM. Now let us imagine the above-mentioned system with 2GB of RAM and 2GB of swap. A database on the system was by mistake configured for a system with 5GB of RAM. Once the physical memory is used up, swap gets used. As the swap disk is much slower than RAM, the performance goes down, and thrashing occurs. At this point, even logins into the system might become impossible. As more and more memory gets written to, eventually both physical- and swap memory are completely exhausted and the OOM killer kicks in, killing one or more processes. In our case, quite a lot of swap is available, so the time of poor performance is long.
Now, let us imagine the above situation with no swap configured. As the system runs out of RAM, it has no swap to hand out. There is almost no time frame of reduced performance - the OOM kicks in immediately. So in this case:
-
The admins have no timeframe to react and possibly take countermeasures to maybe solve the issue without the application losing data. They might decide to reset the system themselves.
-
The admin teams get a notification after the incident and can then only analyze the issue.
Our size recommendation for most modern systems is ‘a part of the physical RAM’, for example, 20%. With this, the painfully slow phase of operation in our example will not last as long, and the OOM kicks in earlier.
Of course, there are scenarios when different behaviour is desired. When aware of the behaviour, such swap configurations are ok, as well as running the system without any swap. Such a system is supported by us as well - but the customer should know the behaviour in the above situations.
How much swap is recommended nowadays?
This depends on the desired behaviour of the system, but configuring an amount of 20% of the RAM as swap is usually a good idea. More details are in this solution document.
Can I run without swap? Is further tuning possible?
Systems without swap can make sense and are supported by Red Hat - just be sure the behaviour of such a system under memory pressure is what you want. In most environments, a bit of swap makes sense.
-
/proc/meminfo Committed_AS field shows how much memory processes have requested.
-
Using sysctl, we can enable/disable overcommit, and configure how much overcommit should be allowed. The defaults need to be changed only in rare cases, and after properly testing the new settings. The RHEL Performance Tuning Guide has details.
-
A solution document with details regarding the likeliness of swapping - for example in changing vm.swappiness. This also requires good testing with your applications.
-
Without swap, the system will call the OOM when the memory is exhausted. You can prioritize which processes get killed first in configuring oom_adj_score.
-
If you write an application, want to lock pages into RAM and prevent them from getting swapped, mlock() can be used.
-
If you design your applications to regularly use swap, make sure to use faster devices, like SSD - starting with Red Hat Enterprise Linux 7.1, ‘swapon --discard’ can be used to send TRIM to SSD devices, to discard the device contents on swapon.
-
The Storage Administration Guide has also a section on swap configuration.
A Red Hat Technical Account Manager (TAM) is a specialized product expert who works collaboratively with IT organizations to strategically plan for successful deployments and help realize optimal performance and growth. The TAM is part of Red Hat’s world class Customer Experience and Engagement organization and provides proactive advice and guidance to help you identify and address potential problems before they occur. Should a problem arise, your TAM will own the issue and engage the best resources to resolve it as quickly as possible with minimal disruption to your business.
Sobre o autor

Christian Horn is a Senior Technical Account Manager at Red Hat. After working with customers and partners since 2011 at Red Hat Germany, he moved to Japan, focusing on mission critical environments. Virtualization, debugging, performance monitoring and tuning are among the returning topics of his daily work. He also enjoys diving into new technical topics, and sharing the findings via documentation, presentations or articles.
Mais como este
Navigating the Mythos-haunted world of platform security
Managed identity in Azure Red Hat OpenShift portal
Collaboration In Product Security | Compiler
Keeping Track Of Vulnerabilities With CVEs | Compiler
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem