A era moderna dos treinamentos de IA, principalmente para modelos de grande porte, enfrenta demandas simultâneas por escala computacional e rigorosa privacidade de dados. O machine learning (ML) tradicional exige a centralização dos dados de treinamento, resultando em obstáculos e esforços significativos em relação à privacidade, à segurança e à eficiência/volume dos dados.
Esse desafio é ampliado em infraestruturas globais heterogêneas em ambientes multicloud, de nuvem híbrida e de edge. Por isso, as organizações devem treinar modelos usando os conjuntos de dados distribuídos existentes e, ao mesmo tempo, proteger a privacidade dos dados.
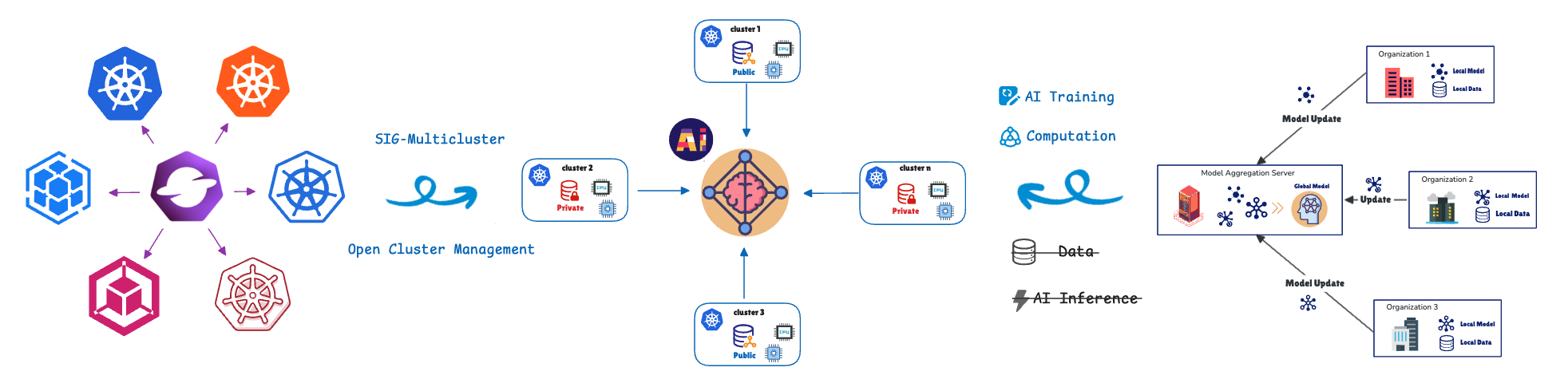
O aprendizado federado ("Federated Learning" - FL) resolve esse desafio migrando o treinamento do modelo para os dados. Clusters ou dispositivos remotos (colaboradores/clientes) treinam modelos localmente usando seus dados privados e só compartilham atualizações do modelo (não os dados brutos) com um servidor central (agregador). Isso ajuda a proteger a privacidade dos dados de ponta a ponta. Essa abordagem é crucial para cenários sensíveis à privacidade ou com alta carga de dados, como encontramos nas áreas de saúde, varejo, automação industrial e veículos definidos por software (SDV), que contam com funcionalidades como: sistemas avançados de assistência ao motorista (ADAS) e direção autônoma (AD), como aviso de partida, controle de cruzeiro adaptativo e monitoramento de fadiga do motorista.
Para gerenciar e orquestrar essas unidades de computação distribuídas, usamos a definição de recurso personalizado (CRD) de aprendizado federado do Open Cluster Management (OCM).
OCM: a base para operações distribuídas
O OCM é uma plataforma de orquestração multicluster do Kubernetes e um projeto open source do CNCF Sandbox.
O OCM emprega uma arquitetura hub-spoke e usa um modelo pull-based.
- Cluster de hub: ele atua como o control plane central (control plane do OCM) responsável pela orquestração.
- Clusters gerenciados (spoke): são clusters remotos nos quais as cargas de trabalho são implementadas.
Os clusters gerenciados extraem o estado desejado do hub e reportam o status de volta para ele. O OCM oferece APIs como ManifestWork e Placement para programar cargas de trabalho. Abordaremos mais detalhes da API de aprendizado federado abaixo.
Vejamos agora por que e como o design de gerenciamento de cluster distribuído do OCM se alinha estreitamente aos requisitos de implementação e gerenciamento de colaboradores de FL.
Integração nativa: OCM como orquestrador de FL
1. Alinhamento da arquitetura
A combinação de OCM e FL é eficaz devido à sua congruência estrutural fundamental. O OCM oferece suporte nativo ao FL porque ambos os sistemas compartilham um design de base idêntico: a arquitetura hub-spoke e um protocolo pull-based.

Componente do OCM | Componente FL | Função |
Control plane do hub do OCM | Agregador/Servidor | Orquestra o estado e agrega atualizações de modelos. |
Cluster gerenciado | Colaborador/cliente | Extrai o estado desejado/modelo global, treina localmente e envia atualizações. |
2. Posicionamento flexível para seleção de clientes com vários atores
A principal vantagem operacional do OCM é a capacidade de automatizar a seleção de clientes em configurações de FL, aproveitando seus recursos flexíveis de agendamento entre clusters. Esse recurso usa a API Placement do OCM para implementar políticas multicritério sofisticadas, fornecendo eficiência e conformidade de privacidade simultaneamente.
A API Placement permite a seleção integrada de clientes com base nos seguintes fatores:
- Localidade dos dados (critério de privacidade): as cargas de trabalho de FL são agendadas apenas para clusters gerenciados que afirmam ter os dados privados necessários.
- Otimização de recursos (critério de eficiência): a estratégia de agendamento do OCM oferece políticas flexíveis que permitem a avaliação combinada de vários fatores. Ele seleciona clusters com base não apenas na presença de dados, mas também em atributos anunciados, como disponibilidade de CPU/memória.
3. Comunicação segura entre o colaborador e o agregador por meio do registro de add-on do OCM
O colaborador de add-on de FL é implementado nos clusters gerenciados e aproveita o mecanismo de registro de add-on do OCM para estabelecer uma comunicação protegida e criptografada com o agregador no hub. Após o registro, cada add-on de colaborador recebe automaticamente certificados do hub OCM. Esses certificados autenticam e criptografam todas as atualizações de modelos trocadas durante o FL, permitindo confidencialidade, integridade e privacidade em vários clusters.
Esse processo atribui tarefas de treinamento de IA com eficiência apenas a clusters com recursos adequados, oferecendo uma seleção integrada de clientes com base na localidade dos dados e na capacidade de recursos.
Ciclo de vida do treinamento de FL: programação orientada pelo OCM
Um Federated Learning Controller dedicado foi desenvolvido para gerenciar o ciclo de vida de treinamento do FL em vários clusters. O controlador utiliza CRDs para definir os fluxos de trabalho e é compatível com runtimes de FL populares, como Flower e OpenFL, e é extensível.


O fluxo de trabalho gerenciado pelo OCM passa por estágios definidos:
Etapas | Fase de OCM/FL | Descrição |
0 | Pré-requisito | O add-on de aprendizado federado está instalado. O aplicativo de FL está disponível como um container implantável pelo Kubernetes. |
1 | CR da Federated Learning | Um recurso personalizado é criado no hub, definindo a estrutura (por exemplo, flower), o número de rodadas de treinamento (cada rodada sendo um ciclo completo em que os clientes treinam localmente e retornam atualizações para agregação), o número necessário de colaboradores de treinamento disponíveis e a configuração de armazenamento de modelos (por exemplo, especificando um caminho PersistentVolumeClaim (PVC)). |
2, 3, 4 | Espera e agendamento | O status do recurso é “Waiting”. O servidor (agregador) é inicializado no hub, e o controlador OCM usa Placement para agendar clientes (colaboradores). |
5, 6 | Em execução | O status muda para “Running”. Os clientes extraem o modelo global, treinam o modelo localmente com dados privados e sincronizam as atualizações do modelo com o agregador de modelos. O parâmetro de rodadas de treinamento determina a frequência com que essa fase se repete. |
7 | Concluído | O status chega a “Completed”. A validação pode ser realizada por meio da implementação de Jupyter Notebooks para verificar o desempenho do modelo em relação ao conjunto de dados agregado inteiro (por exemplo, confirmar se ele prevê todos os dígitos do Instituto Nacional de Padrões e Tecnologia Modificado (MNIST)). |
Red Hat Advanced Cluster Management: controle empresarial e valor operacional para ambientes de FL
As APIs e a arquitetura fornecidas pelo OCM são a base do Red Hat Advanced Cluster Management for Kubernetes. O Red Hat Advanced Cluster Management oferece gerenciamento do ciclo de vida para uma plataforma de FL homogênea (o Red Hat OpenShift) em uma infraestrutura heterogênea. Executar o controlador de FL no Red Hat Advanced Cluster Management oferece mais benefícios do que o OCM oferece isoladamente. O Red Hat Advanced Cluster Management oferece visibilidade centralizada, governança orientada por políticas e gerenciamento do ciclo de vida em estados multicluster, melhorando significativamente a capacidade de gerenciamento de ambientes distribuídos e de FL.
1. Observabilidade
O Red Hat Advanced Cluster Management oferece observabilidade unificada em fluxos de trabalho de FL distribuídos, permitindo que os operadores monitorem o progresso do treinamento, o status do cluster e a coordenação entre clusters em uma interface única e consistente.
2. Conectividade e segurança aprimoradas
A CRD de FL é compatível com a comunicação protegida entre o agregador e os clientes por meio de canais habilitados para TLS. Ele também oferece opções de rede flexíveis além do NodePort, incluindo LoadBalancer, Route e outros tipos de entrada, oferecendo conectividade protegida e adaptável em ambientes heterogêneos.
3. Integração completa do ciclo de vida de ML com o Red Hat Advanced Cluster Management e o Red Hat OpenShift AI
Ao usar o Red Hat Advanced Cluster Management com o OpenShift AI, as empresas podem criar um fluxo de trabalho de FL completo, desde a prototipagem de modelos e treinamento distribuído até a validação e implementação de produção, em uma plataforma unificada.
Conclusão
O FL está transformando a IA ao migrar o treinamento de modelos diretamente para os dados, resolvendo efetivamente o atrito entre escala computacional, transferência de dados e requisitos rigorosos de privacidade. Destacamos aqui como o Red Hat Advanced Cluster Management oferece a orquestração, a proteção e a observabilidade necessárias para gerenciar ambientes Kubernetes distribuídos e complexos.
Entre em contato com a Red Hat hoje mesmo para descobrir como capacitar sua organização com o aprendizado federado.
Recurso
A empresa adaptável: da prontidão para a IA à disrupção
Sobre os autores

Andreas Spanner leads Red Hat’s Cloud Strategy & Digital Transformation efforts across Australia and New Zealand. Spanner has worked on a wide range of initiatives across different industries in Europe, North America and APAC including full-scale ERP migrations, HR, finance and accounting, manufacturing, supply chain logistics transformations and scalable core banking strategies to support regional business growth strategies. He has an engineering degree from the University of Ravensburg, Germany.

Meng Yan is a Senior Software Engineer at Red Hat, specializing in event-driven architectures for multi-cluster management at scale. His research interests focus on agentic AI systems and intelligent automation for software engineering, as well as AI/ML applications in distributed environments such as federated learning and multi-cluster inference.
Mais como este
Unlocking sovereign AI and protected collaboration with confidential computing
Building a hardened, image-based foundation for AI agents
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem