

Introduction
When working with Kubernetes or OpenShift in a multicluster (possibly hybrid cloud) deployment, one of the considerations that comes up is how to direct traffic to the applications deployed across these clusters. To solve this problem, we need a global load balancer.

The diagram above depicts an application called “app” deployed to two Kubernetes clusters and accessible via Ingress or Gateway APIs resources (henceforth Ingress for simplicity), which are in turn exposed by two local load balancers (LLB) accessible via two Virtual IP’s (VIPs): VIP1 and VIP2. A global load balancer sits above the LLB’s and directs the consumers to either of the clusters. Consumers reference a single global FQDN (app.globaldomain.io, in this example) to access the application.
As of the time of the publication of this article, there is no clear direction within the Kubernetes community on how to design and implement global load balancers for Kubernetes clusters. Only small isolated efforts have been attempted.
In this article, we will discuss what it will take to properly architect a global load balancer solution and what it will take to automate the configuration based on the workloads running within Kubernetes clusters.
Before proceeding with the specific architectural options, we will review the common traits that a global load balancer should have.
Global Load Balancer Requirements
A global load balancer for Kubernetes clusters is responsible for determining where the connections to a service should be routed with respect to instances running within individual Kubernetes clusters. These clusters can be geographically distributed or reside within the same metro area.
Kubernetes offers two main methods for incoming traffic to enter the cluster: Ingresses (Ingress, Gateway API and OpenShift Routes) and LoadBalancer Services.
Our global load balancer needs to support both. It is worth noting that in the case of Ingresses (a L7 reverse proxy), we often have a local load balancer exposing VIP that is shared by multiple applications.
Furthermore, a global load balancer should offer sophisticated load balancing policies aside from round robin. In particular, a policy that is often requested is the ability to return the endpoint that is closest to the consumer trying to connect, based on some metric (latency, geographical distance, etc.). In geographically distributed scenarios, this policy allows the consumer to connect to the endpoint with the lowest latency. In metro area scenarios, this allows connections originating in a datacenter to be routed within the same datacenter.
Another commonly needed policy is weighted routing, which aids in achieving an active/passive configuration by assigning all the weight to only one cluster at a time.
Finally, a global load balancer should be able to recognize when applications become unavailable and should direct traffic only to healthy endpoints. This is usually done by configuring health checks.
To summarize, the following are requirements that we look for in a global load balancer:
- Ability to load balance over LoadBalancer Services and Ingresses
- Sophisticated load balancing policies
- Support for health checks and ability to remove unhealthy endpoints from the load balanced pool
Global Load Balancer Architecture Options
Based on our experience, there are two architectural approaches for designing a global load balancer:
- DNS-based.
- Anycast-based.
Let’s examine them separately.
DNS-Based approaches
In DNS-based approaches, the load balancing decision is made by a DNS server.
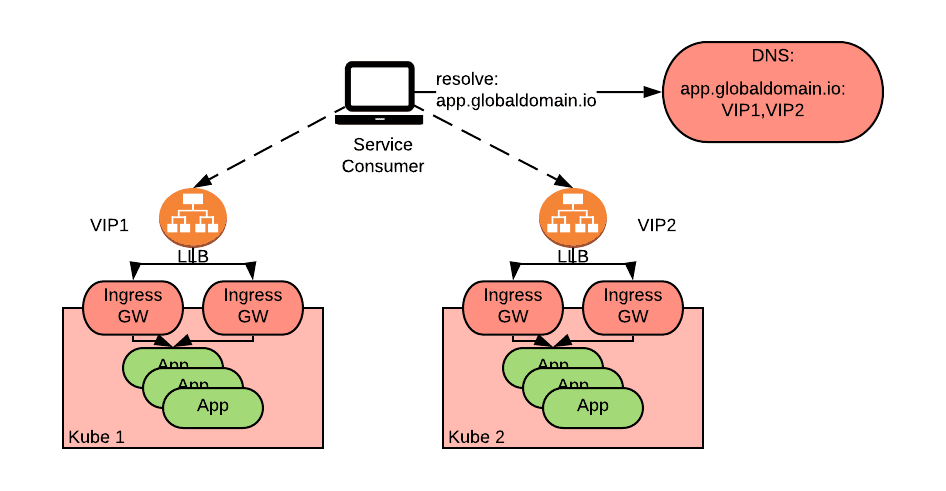
As we can see from the diagram above, a service consumer queries the DNS server for app.globaldomain.io and the DNS server responds with one of the addresses of the two clusters.
DNS-based load balancing has the advantage of being relatively easy to implement as DNS servers are part of any network infrastructure. However, the simplicity comes with a set of limitations:
- Clients will keep the DNS response cached for a certain period of time (normally as per the TTL, but there is no guarantee). If an outage occurs with the location in the cache, the client may not be able to operate until either the issue is resolved with this location or the DNS cache is refreshed.
- When the DNS server is configured to return multiple IPs values, the client then becomes responsible for choosing the particular endpoint that it will connect to, resulting in a potentially unbalanced traffic pattern. This is true even if the DNS server randomizes the order of the returned IPs. This is because there is nothing in the DNS specification that mandates that the order of the IPs must be retained as the responses traverse back the DNS server hierarchy or that the order must be honored by the service consumer.
In addition to the above limitations, typical DNS servers do not support sophisticated load balancing policies nor do they have support for backend health checks.
However, there are several advanced DNS implementations that do support these features including:
- Networking appliances, such as F5 BigIP and Citrix ADC, common in on-premise datacenters
- DNS hosting solutions, such Infoblox and CloudFlare
- DNS service of a major public cloud providers: AWS Route53, Azure Traffic Manager
Note that when implementing these global load balancer approaches, if Ingresses (Ingress v1, v2 or OpenShift Routes) are being used as a way of routing traffic to the application, the host name configured in the ingress must be the same as the global FQDN used by the consumer when querying the DNS server. This hostname will differ from the default address for the application which typically is cluster specific and must be explicitly set.
Summary
| DNS-Based load balancing | Simple DNS servers | Advanced DNS Servers |
| Support for LoadBalancer services | yes | yes |
| Support for Ingress | yes | yes |
| Support for sophisticated load balancing policies | no | yes |
| Support for health checks | no | yes |
| Examples | Any DNS server | On-premise: F5 BigIP, Citrix ADC, etc. ... |
| Limitations | Possibility of uneven load balancing Relatively slow reaction times when an backend suffers an outage (30seconds) | Relatively slow reaction times when an backend suffers an outage (30seconds) |
Anycast-Based approaches
Anycast-based approaches refer to an architectural pattern in which many servers advertise the same IP and a router can route packets to these locations via different network paths.
There are two ways this architecture can be achieved:
- IP/ BGP based anycast service: Explicitly design and leverage IP/ BGP technologies to implement anycast load balancing functionality.
- Use an anycast / CDN cloud service: Leverage an existing anycast capable network (such as special public cloud anycast services that provide anycast centric load balancing and CDN services). Examples of such cloud services include Google Cloud Network Load balancer, AWS Global Accelerator and similar global load balancing services from other providers.
IP/BGP-based approach
We first look at an IP/ BGP-based anycast design. This can be achieved with BGP and ECMP for IPv4 or through native support for anycast in IPv6.
The resulting architecture can be depicted similar to the following:
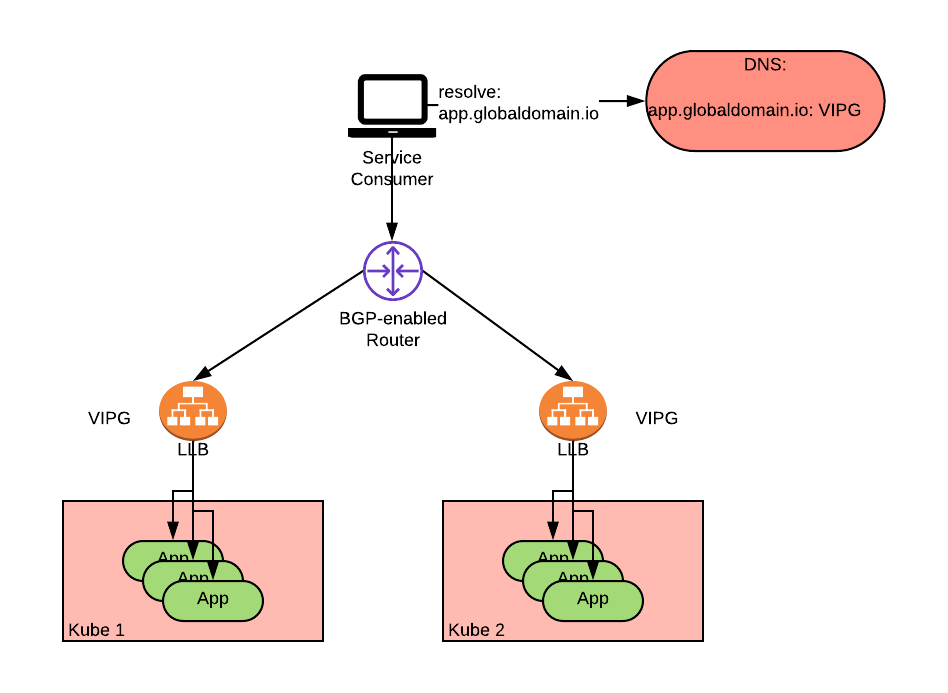
The diagram shows an application deployed within two clusters and exposed via a LoadBalancer service. The VIPs of the two LoadBalancer services are the same (VIPG as in VIP Global in the picture). The router is programmed via BGP to assign equal cost to both paths (ECMP) to VIPG realizing an active-active anycast load balancer solution. Alternate BGP metrics, such as unequal cost and local preference, can also be used to implement additional load balancing policies including active-standby.
Active-standby, in particular, can be achieved by having one cluster advertise a far better route metric than another so that, under normal circumstances, all traffic to a particular VIP is routed to that cluster regardless of the IP hop distance from the client. When a disaster occurs, the less preferable route is chosen as it becomes the only viable alternative.
This approach has the advantage that failover does not depend on the client and is governed by the router, yielding much faster failover (on the order of milliseconds) than DNS-based solutions.
To have the best failover experience, the router needs to perform flow-aware multipath load balancing with 3-tuple or 5-tuple hashing, as well as consistent hashing (sometimes called resilient hashing). Without this functionality, failover performance and availability may suffer since a large number of TCP sessions may get reset upon a network failure event that causes rehashing and re-routing of sessions from one backend to another. Modern routers usually support these features; however, it is necessary to ensure that they are correctly configured for consistent hashing.
This approach has the following limitations:
- BGP/anycast capabilities are not always available in on-premise datacenters.
- Given the fact BGP operates at L3/4 level, it does not directly support the ability to independently failover multiple applications that share the same VIP.
Reference Implementation with Kubernetes
One option to implement the described approach, is to use MetalLB in BGP mode to implement the Kubernetes LoadBalancer Service and have the cluster nodes be connected to a physical network that supports BGP. The topology would look similar to the preceding diagram where the MetalLB agent deployed to each cluster node would peer with the external BGP network to advertise reachability for the same VIP via multiple nodes of multiple clusters:
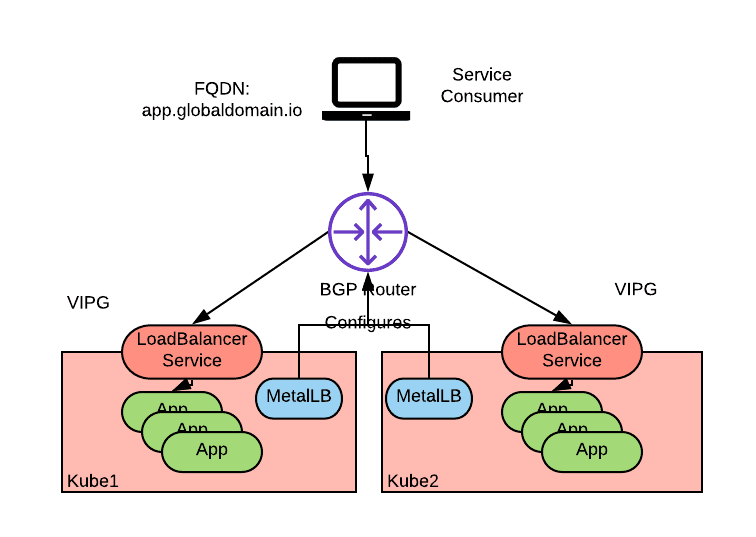
Note that it is not necessary to use a CNI plug-in that uses BGP routing for intra-cluster pod-to- pod networking to achieve this solution. BGP is used only by MetalLB to advertise the LoadBalancer VIP to the external network. MetalLB honors the LoadBalancer API of the Kubernetes service specification and therefore can be used in those scenarios where no cloud provider is available or the cloud provider does not honor the LoadBalancer Service API.
For the global load balancer to work, multiple clusters need to be configured to use the same VIP for Kubernetes Services implementing the same application.
Additional automation can also be implemented to ensure synchronization of this configuration across clusters, for example, to discover the LoadBalancer services that need to be global or to enforce that they have the same LoadBalancer VIP. Support for BGP route metrics, such as Local Preference, can also be coordinated via central automation so that preferential priority can be provided to one cluster over another.
Note that MetalLB is currently not supported on OpenShift as of 4.8, but is an item on the roadmap for future inclusion in the product, including support for BGP mode.
Anycast load balancing cloud service based approach
Many public cloud providers support global load balancing as a service that implements the anycast method in that a single static global IP address is made available for use by the tenant and can be used as the frontend for a multicluster multiregion service.
Examples of such services include the Google Cloud Network Load Balancer, AWS Global Accelerator, Fastly Anycast, and CloudFlare Anycast. These cloud services are often combined with CDN and/or API Gateway functionalities, but in most cases can also be used as a pure global anycast load balancing service without necessarily making use of the other features.
These services are typically implemented using a collection of edge cloud locations, all of which advertise the global static VIP. Traffic destined to the global VIP is directed to the closest edge cloud location from the requester where it is then load balanced and routed internally within the cloud provider’s network towards the backend instances.
The exact techniques used by cloud providers to implement such services are hidden from the end user, but typically involve an internal combination of IP/ BGP based anycast along with Resilient ECMP. Cloud providers are able to leverage their private networks to additionally provide advanced load balancing policies and traffic steering, although these features may not always be consistent between one provider and another.
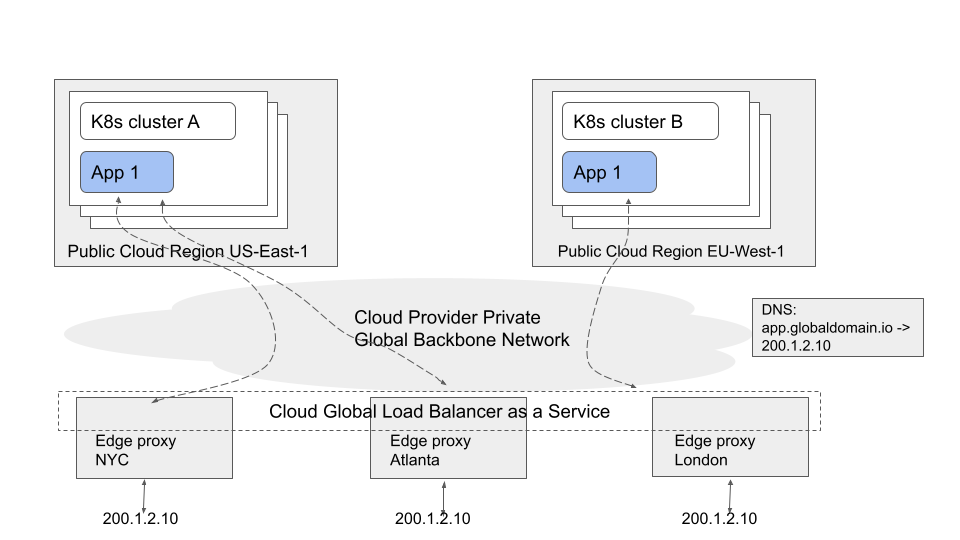
The features provided by each anycast cloud service varies, including whether a customer is allowed to bring their own IPs for such services or whether global IPs are internal or external facing.
Summary
| Anycast-Based load balancing | Simple BGP+ECMP solutions | Anycast LBaaS-based solutions |
| Support for LoadBalancer services | yes | yes |
| Support for Ingress | no | yes |
| Support for sophisticated load balancing policies | some | yes |
| Support for health checks | no | yes |
| Examples | Any BGP+ECMP implementation | LBaaS: Akamai, F5 silverline |
| Limitations | Requires a BGP-aware load balancer service implementation. | Generally not available to on-premise deployments. Each specific implementation can have additional limitations. |
Automating Global Load Balancer Configurations
So far, we have examined several approaches to building global load balancers. But, let’s imagine a scenario in which we have chosen an approach and we need to globally load balance hundreds of applications deployed to multiple clusters. Having some form of automation to aid in the creation of the global load balancing configurations for these applications would certainly be helpful.
One can use traditional automation tools to automate networking configuration, but in a Kubernetes context, the mainstream approach is to use an operator.
A global load balancer operator needs to monitor the configuration of several clusters and, based on the state found in those clusters, configure the global load balancer. One complication in this space is that the ecosystem of tools for building operators today is all focused on building operators that operate on only a single cluster. As a result, the majority of operators being developed are cluster-bound.
In part for this reason and in part for the many ways that can be used to implement a global load balancer operator, there does not seem to be an official implementation for such an operator in the Kubernetes community. However, there are, as we said in the introduction, two initiatives that we are aware of: k8gb and global-loadbalancer-operator.
K8gb
K8gb is a DNS-based global load balancer operator. The interesting part of k8gb is that the DNS server is implemented as a cluster of CoreDNS pods and it is self-hosted and distributed across the Kubernetes clusters that it will serve. This provides inherent resilience to disaster as well as independence from external network capabilities.
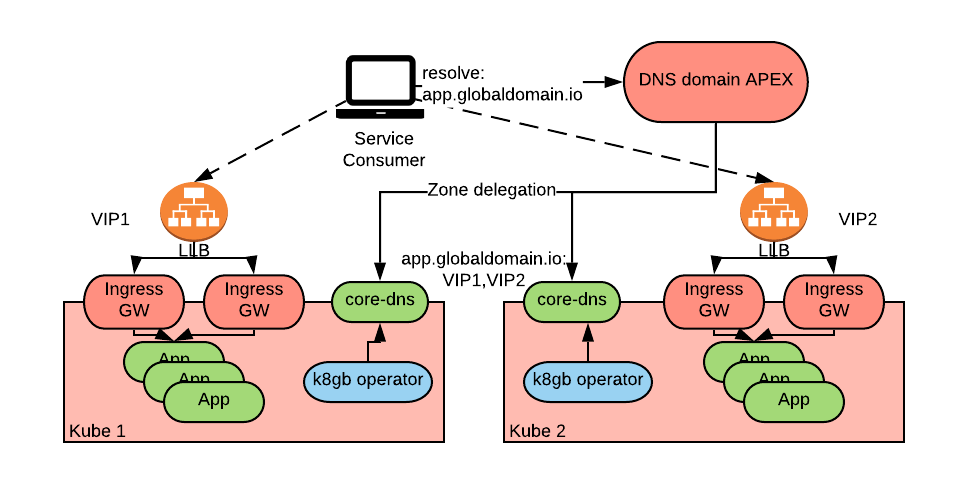
A limitation of k8gb is that it has limited support for advanced load-balancing policies. Efforts are underway to mitigate these shortcomings through the use of CoreDNS plug-ins. Refer to the recently added geoip load balancing strategy for an example of some of the efforts being made.
Global-loadbalancer-operator
The global-loadbalancer-operator is an operator designed to run in a control cluster and configured to watch several controlled clusters for which it will build global load balancer configurations.
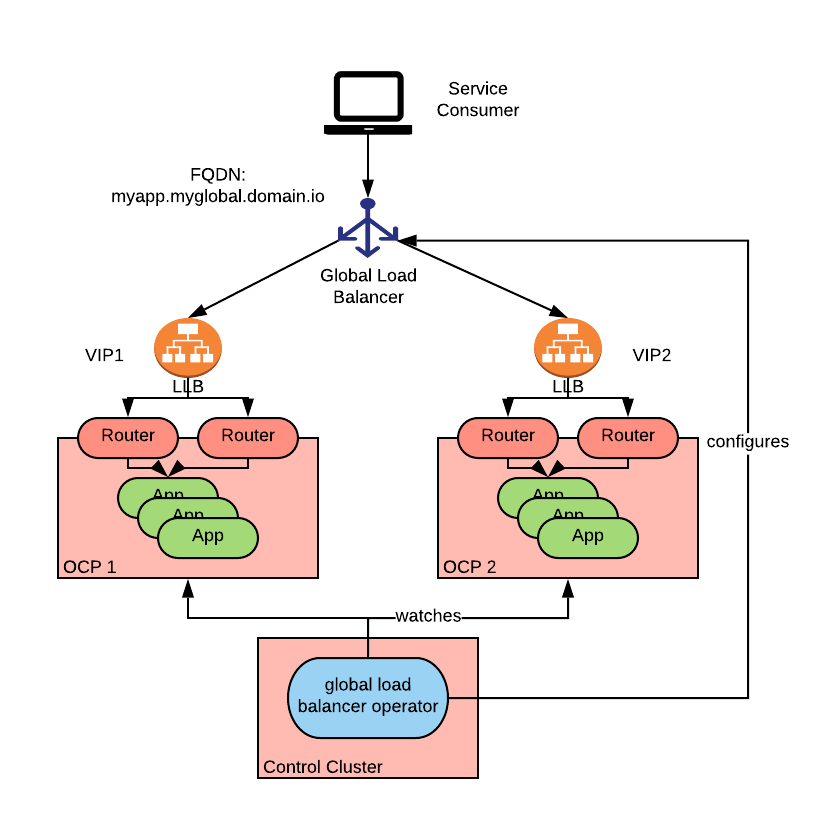
It can be used to configure any DNS server supported by the external-dns operator to achieve basic DNS-based global load balancing.
It has been designed to address both DNS-based and Cloud anycast-based global load balancing. Advanced configuration options are also available when operating in the public cloud.
As of the date of the publication of this post, support is available with AWS Route53, Azure Traffic Manager and soon Google Global IPs as providers that feature more advanced capabilities such as different load balancing policies and health checks.
The use of a control cluster and support for deployment only within OpenShift are two of the limitations of the global-loadbalancer-operator.
Conclusions
In this article, we examined several approaches for building global load balancers in front of Kubernetes clusters. We saw that there are several options suitable for different scenarios, but from an automation standpoint, we are at early stages. Arguably, the ability for global load balancing to be self-service by application teams is one of the obstacles that hinders the deployment of applications across multiple clusters to achieve active/active architectures.
Our hope is that this article will revive the interest from the community and propel the research of more broadly accepted solutions for this type of traffic management in Kubernetes.
Sobre os autores
Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
Mais como este
O paradoxo agêntico e o argumento a favor da IA híbrida
Pare de gerenciar o passado e comece a construir o futuro da TI
The Containers_Derby | Command Line Heroes
Crack the Cloud_Open | Command Line Heroes
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem